 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-driven Subword Grammar Modeling for Automatic Speech Recognition in Tamil and Kannada
Jul 27, 2022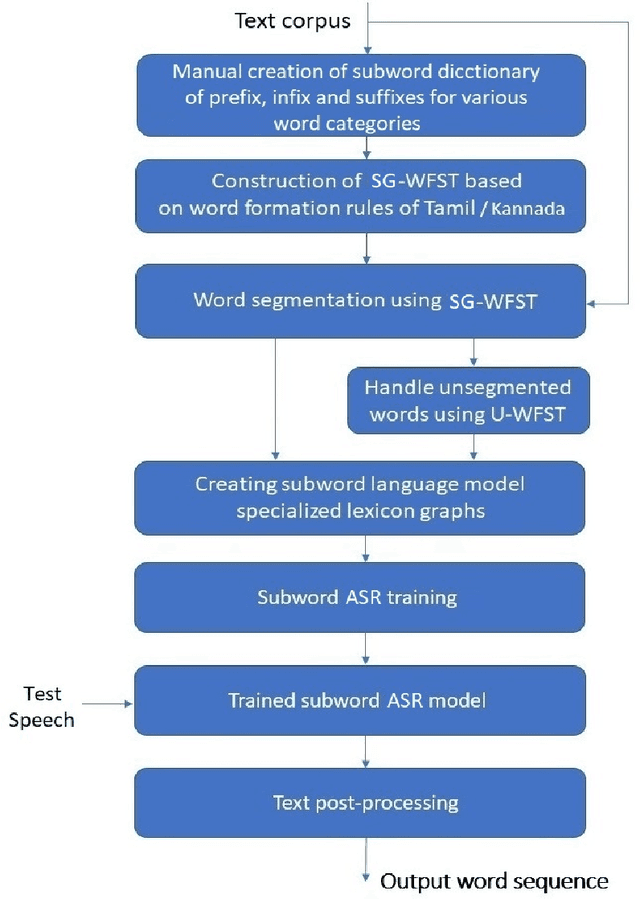
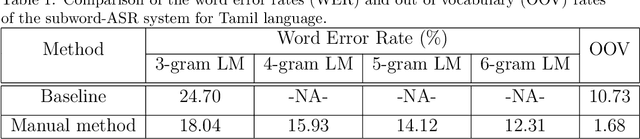

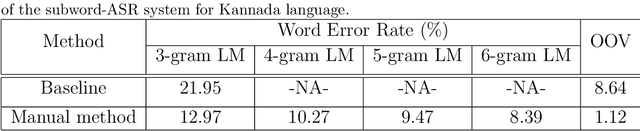
In this paper, we present specially designed automatic speech recognition (ASR) systems for the highly agglutinative and inflective languages of Tamil and Kannada that can recognize unlimited vocabulary of words. We use subwords as the basic lexical units for recognition and construct subword grammar weighted finite state transducer (SG-WFST) graphs for word segmentation that captures most of the complex word formation rules of the languages. We have identified the following category of words (i) verbs, (ii) nouns, (ii) pronouns, and (iv) numbers. The prefix, infix and suffix lists of subwords are created for each of these categories and are used to design the SG-WFST graphs. We also present a heuristic segmentation algorithm that can even segment exceptional words that do not follow the rules encapsulated in the SG-WFST graph. Most of the data-driven subword dictionary creation algorithms are computation driven, and hence do not guarantee morpheme-like units and so we have used the linguistic knowledge of the languages and manually created the subword dictionaries and the graphs. Finally, we train a deep neural network acoustic model and combine it with the pronunciation lexicon of the subword dictionary and the SG-WFST graph to build the subword-ASR systems. Since the subword-ASR produces subword sequences as output for a given test speech, we post-process its output to get the final word sequence, so that the actual number of words that can be recognized is much higher. Upon experimenting the subword-ASR system with the IISc-MILE Tamil and Kannada ASR corpora, we observe an absolute word error rate reduction of 12.39% and 13.56% over the baseline word-based ASR systems for Tamil and Kannada, respectively.
Subword Dictionary Learning and Segmentation Techniques for Automatic Speech Recognition in Tamil and Kannada
Jul 27, 2022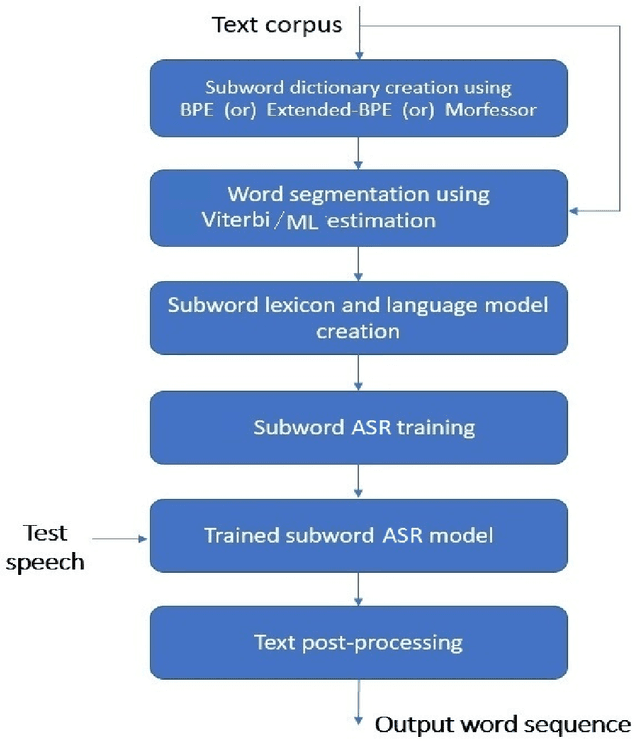

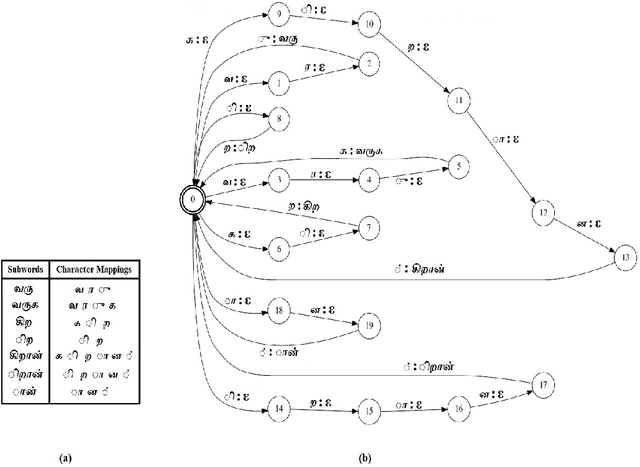
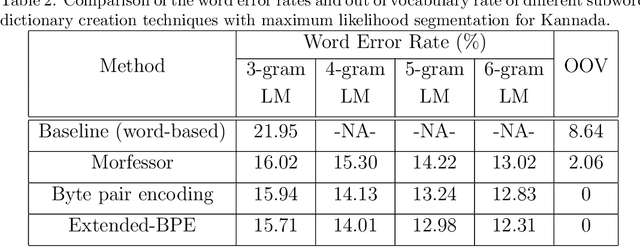
We present automatic speech recognition (ASR) systems for Tamil and Kannada based on subword modeling to effectively handle unlimited vocabulary due to the highly agglutinative nature of the languages. We explore byte pair encoding (BPE), and proposed a variant of this algorithm named extended-BPE, and Morfessor tool to segment each word as subwords. We have effectively incorporated maximum likelihood (ML) and Viterbi estimation techniques with weighted finite state transducers (WFST) framework in these algorithms to learn the subword dictionary from a large text corpus. Using the learnt subword dictionary, the words in training data transcriptions are segmented to subwords and we train deep neural network ASR systems which recognize subword sequence for any given test speech utterance. The output subword sequence is then post-processed using deterministic rules to get the final word sequence such that the actual number of words that can be recognized is much larger. For Tamil ASR, We use 152 hours of data for training and 65 hours for testing, whereas for Kannada ASR, we use 275 hours for training and 72 hours for testing. Upon experimenting with different combination of segmentation and estimation techniques, we find that the word error rate (WER) reduces drastically when compared to the baseline word-level ASR, achieving a maximum absolute WER reduction of 6.24% and 6.63% for Tamil and Kannada respectively.
Shape Representation and Classification through Pattern Spectrum and Local Binary Pattern - A Decision Level Fusion Approach
Apr 27, 2015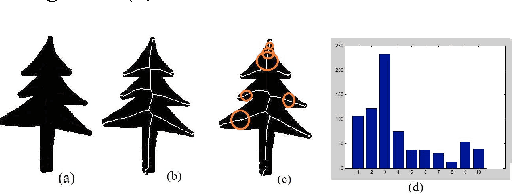
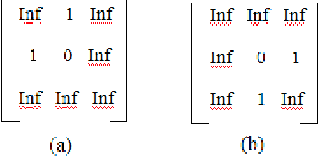
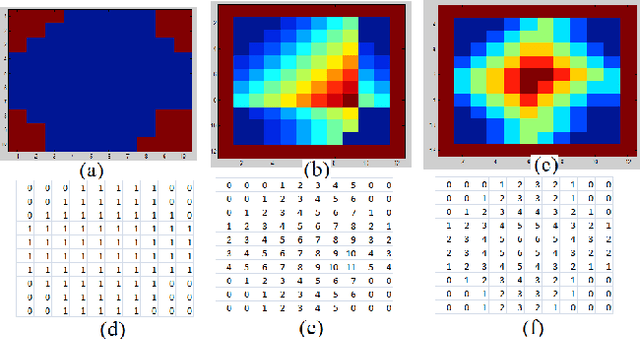
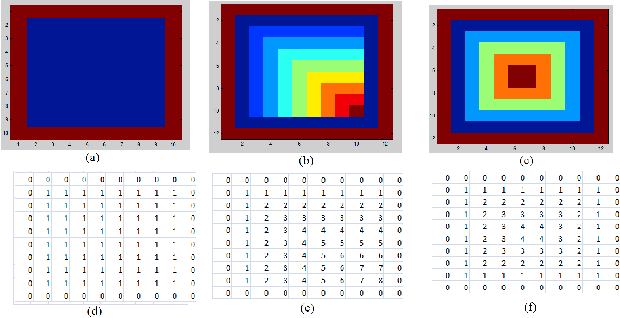
In this paper, we present a decision level fused local Morphological Pattern Spectrum(PS) and Local Binary Pattern (LBP) approach for an efficient shape representation and classification. This method makes use of Earth Movers Distance(EMD) as the measure in feature matching and shape retrieval process. The proposed approach has three major phases : Feature Extraction, Construction of hybrid spectrum knowledge base and Classification. In the first phase, feature extraction of the shape is done using pattern spectrum and local binary pattern method. In the second phase, the histograms of both pattern spectrum and local binary pattern are fused and stored in the knowledge base. In the third phase, the comparison and matching of the features, which are represented in the form of histograms, is done using Earth Movers Distance(EMD) as metric. The top-n shapes are retrieved for each query shape. The accuracy is tested by means of standard Bulls eye score method. The experiments are conducted on publicly available shape datasets like Kimia-99, Kimia-216 and MPEG-7. The comparative study is also provided with the well known approaches to exhibit the retrieval accuracy of the proposed approach.