 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Quantities of Interest from Dynamical Systems for Observation-Consistent Inversion
Sep 15, 2020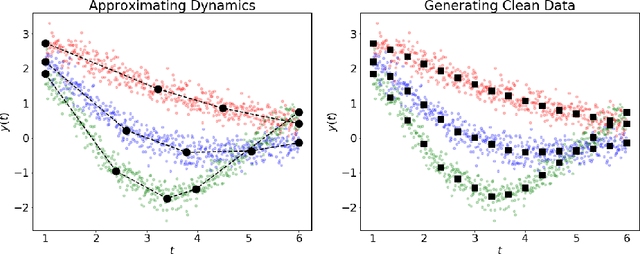

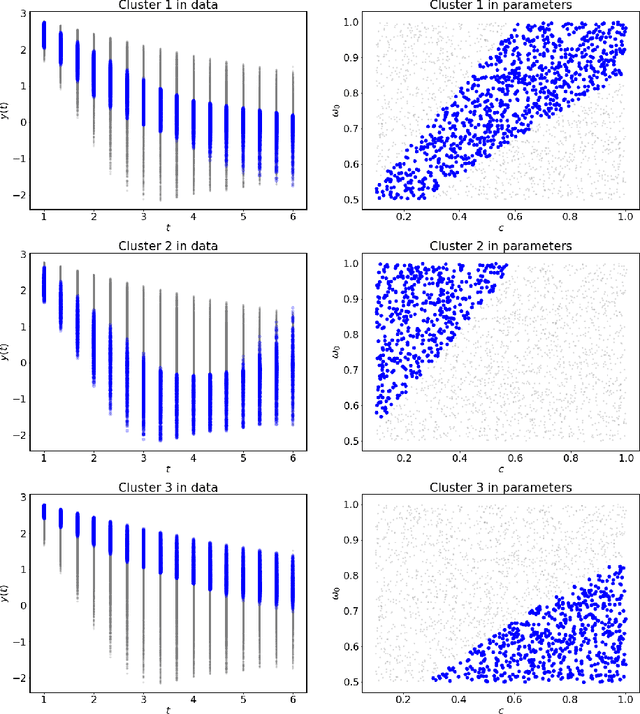

Dynamical systems arise in a wide variety of mathematical models from science and engineering. A common challenge is to quantify uncertainties on model inputs (parameters) that correspond to a quantitative characterization of uncertainties on observable Quantities of Interest (QoI). To this end, we consider a stochastic inverse problem (SIP) with a solution described by a pullback probability measure. We call this an observation-consistent solution, as its subsequent push-forward through the QoI map matches the observed probability distribution on model outputs. A distinction is made between QoI useful for solving the SIP and arbitrary model output data. In dynamical systems, model output data are often given as a series of state variable responses recorded over a particular time window. Consequently, the dimension of output data can easily exceed $\mathcal{O}(1E4)$ or more due to the frequency of observations, and the correct choice or construction of a QoI from this data is not self-evident. We present a new framework, Learning Uncertain Quantities (LUQ), that facilitates the tractable solution of SIPs for dynamical systems. Given ensembles of predicted (simulated) time series and (noisy) observed data, LUQ provides routines for filtering data, unsupervised learning of the underlying dynamics, classifying observations, and feature extraction to learn the QoI map. Subsequently, time series data are transformed into samples of the underlying predicted and observed distributions associated with the QoI so that solutions to the SIP are computable. Following the introduction and demonstration of LUQ, numerical results from several SIPs are presented for a variety of dynamical systems arising in the life and physical sciences. For scientific reproducibility, we provide links to our Python implementation of LUQ and to all data and scripts required to reproduce the results in this manuscript.
Prevention is Better than Cure: Handling Basis Collapse and Transparency in Dense Networks
Aug 22, 2020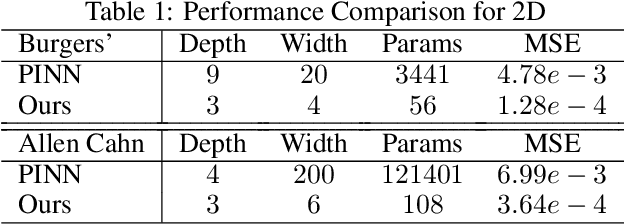
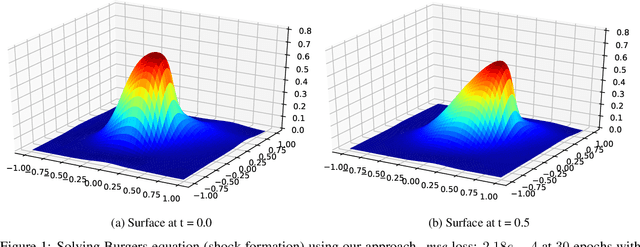
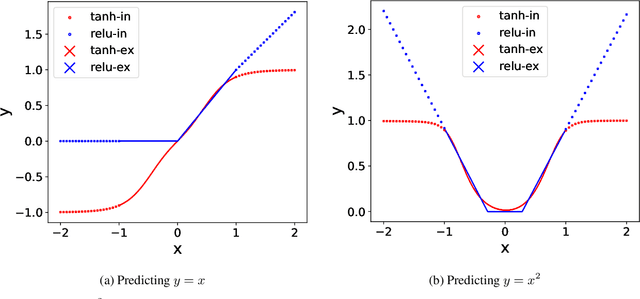
Dense nets are an integral part of any classification and regression problem. Recently, these networks have found a new application as solvers for known representations in various domains. However, one crucial issue with dense nets is it's feature interpretation and lack of reproducibility over multiple training runs. In this work, we identify a basis collapse issue as a primary cause and propose a modified loss function that circumvents this problem. We also provide a few general guidelines relating the choice of activations to loss surface roughness and appropriate scaling for designing low-weight dense nets. We demonstrate through carefully chosen numerical experiments that the basis collapse issue leads to the design of massively redundant networks. Our approach results in substantially concise nets, having $100 \times$ fewer parameters, while achieving a much lower $(10\times)$ MSE loss at scale than reported in prior works. Further, we show that the width of a dense net is acutely dependent on the feature complexity. This is in contrast to the dimension dependent width choice reported in prior theoretical works. To the best of our knowledge, this is the first time these issues and contradictions have been reported and experimentally verified. With our design guidelines we render transparency in terms of a low-weight network design. We share our codes for full reproducibility available at https://github.com/smjtgupta/Dense_Net_Regress.
TIME: A Transparent, Interpretable, Model-Adaptive and Explainable Neural Network for Dynamic Physical Processes
Mar 06, 2020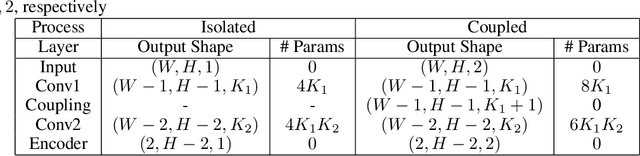

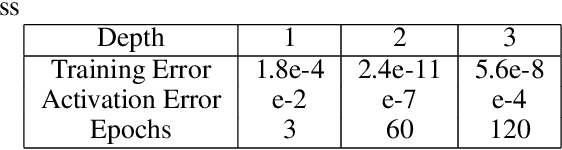
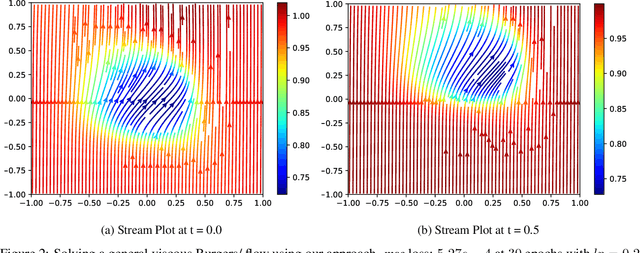
Partial Differential Equations are infinite dimensional encoded representations of physical processes. However, imbibing multiple observation data towards a coupled representation presents significant challenges. We present a fully convolutional architecture that captures the invariant structure of the domain to reconstruct the observable system. The proposed architecture is significantly low-weight compared to other networks for such problems. Our intent is to learn coupled dynamic processes interpreted as deviations from true kernels representing isolated processes for model-adaptivity. Experimental analysis shows that our architecture is robust and transparent in capturing process kernels and system anomalies. We also show that high weights representation is not only redundant but also impacts network interpretability. Our design is guided by domain knowledge, with isolated process representations serving as ground truths for verification. These allow us to identify redundant kernels and their manifestations in activation maps to guide better designs that are both interpretable and explainable unlike traditional deep-nets.
High Temporal Resolution Rainfall Runoff Modelling Using Long-Short-Term-Memory (LSTM) Networks
Feb 07, 2020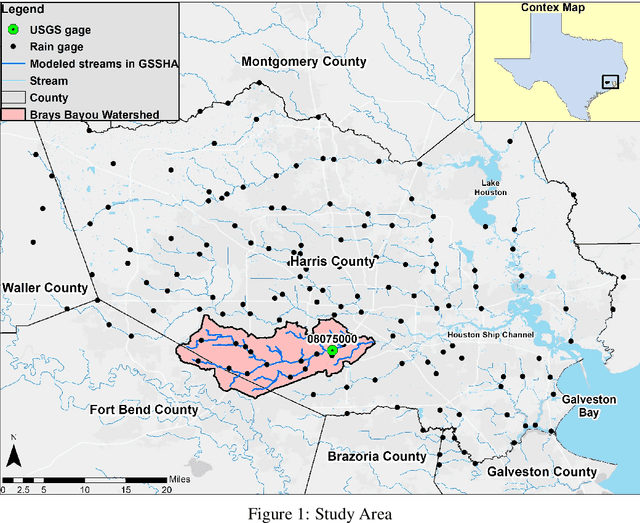
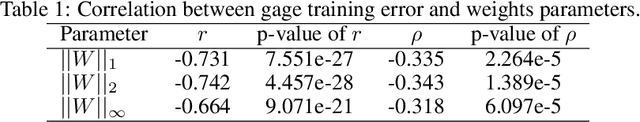
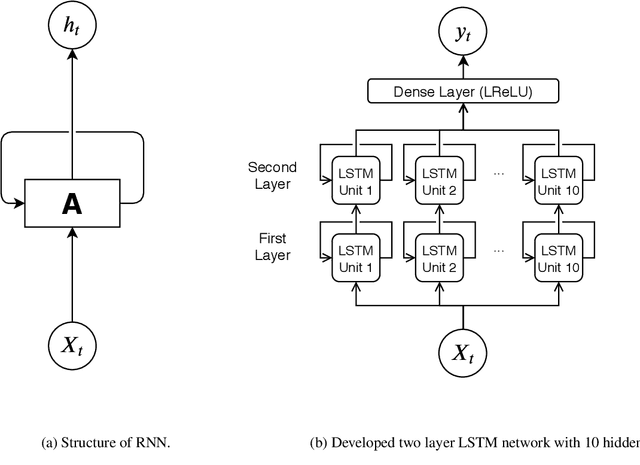
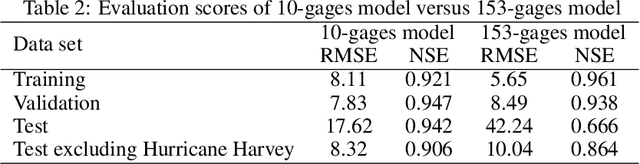
Accurate and efficient models for rainfall runoff (RR) simulations are crucial for flood risk management. Most rainfall models in use today are process-driven; i.e. they solve either simplified empirical formulas or some variation of the St. Venant (shallow water) equations. With the development of machine-learning techniques, we may now be able to emulate rainfall models using, for example, neural networks. In this study, a data-driven RR model using a sequence-to-sequence Long-short-Term-Memory (LSTM) network was constructed. The model was tested for a watershed in Houston, TX, known for severe flood events. The LSTM network's capability in learning long-term dependencies between the input and output of the network allowed modeling RR with high resolution in time (15 minutes). Using 10-years precipitation from 153 rainfall gages and river channel discharge data (more than 5.3 million data points), and by designing several numerical tests the developed model performance in predicting river discharge was tested. The model results were also compared with the output of a process-driven model Gridded Surface Subsurface Hydrologic Analysis (GSSHA). Moreover, physical consistency of the LSTM model was explored. The model results showed that the LSTM model was able to efficiently predict discharge and achieve good model performance. When compared to GSSHA, the data-driven model was more efficient and robust in terms of prediction and calibration. Interestingly, the performance of the LSTM model improved (test Nash-Sutcliffe model efficiency from 0.666 to 0.942) when a selected subset of rainfall gages based on the model performance, were used as input instead of all rainfall gages.