 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Asynchronous Multi-Task Model with Class Incremental Contrastive Learning for Surgical Scene Understanding
Nov 28, 2022Purpose: Surgery scene understanding with tool-tissue interaction recognition and automatic report generation can play an important role in intra-operative guidance, decision-making and postoperative analysis in robotic surgery. However, domain shifts between different surgeries with inter and intra-patient variation and novel instruments' appearance degrade the performance of model prediction. Moreover, it requires output from multiple models, which can be computationally expensive and affect real-time performance. Methodology: A multi-task learning (MTL) model is proposed for surgical report generation and tool-tissue interaction prediction that deals with domain shift problems. The model forms of shared feature extractor, mesh-transformer branch for captioning and graph attention branch for tool-tissue interaction prediction. The shared feature extractor employs class incremental contrastive learning (CICL) to tackle intensity shift and novel class appearance in the target domain. We design Laplacian of Gaussian (LoG) based curriculum learning into both shared and task-specific branches to enhance model learning. We incorporate a task-aware asynchronous MTL optimization technique to fine-tune the shared weights and converge both tasks optimally. Results: The proposed MTL model trained using task-aware optimization and fine-tuning techniques reported a balanced performance (BLEU score of 0.4049 for scene captioning and accuracy of 0.3508 for interaction detection) for both tasks on the target domain and performed on-par with single-task models in domain adaptation. Conclusion: The proposed multi-task model was able to adapt to domain shifts, incorporate novel instruments in the target domain, and perform tool-tissue interaction detection and report generation on par with single-task models.
ST-MTL: Spatio-Temporal Multitask Learning Model to Predict Scanpath While Tracking Instruments in Robotic Surgery
Dec 10, 2021



Representation learning of the task-oriented attention while tracking instrument holds vast potential in image-guided robotic surgery. Incorporating cognitive ability to automate the camera control enables the surgeon to concentrate more on dealing with surgical instruments. The objective is to reduce the operation time and facilitate the surgery for both surgeons and patients. We propose an end-to-end trainable Spatio-Temporal Multi-Task Learning (ST-MTL) model with a shared encoder and spatio-temporal decoders for the real-time surgical instrument segmentation and task-oriented saliency detection. In the MTL model of shared parameters, optimizing multiple loss functions into a convergence point is still an open challenge. We tackle the problem with a novel asynchronous spatio-temporal optimization (ASTO) technique by calculating independent gradients for each decoder. We also design a competitive squeeze and excitation unit by casting a skip connection that retains weak features, excites strong features, and performs dynamic spatial and channel-wise feature recalibration. To capture better long term spatio-temporal dependencies, we enhance the long-short term memory (LSTM) module by concatenating high-level encoder features of consecutive frames. We also introduce Sinkhorn regularized loss to enhance task-oriented saliency detection by preserving computational efficiency. We generate the task-aware saliency maps and scanpath of the instruments on the dataset of the MICCAI 2017 robotic instrument segmentation challenge. Compared to the state-of-the-art segmentation and saliency methods, our model outperforms most of the evaluation metrics and produces an outstanding performance in the challenge.
RASEC: Rescaling Acquisition Strategy with Energy Constraints under SE-OU Fusion Kernel for Active Trachea Palpation and Incision Recommendation in Laryngeal Region
Nov 12, 2021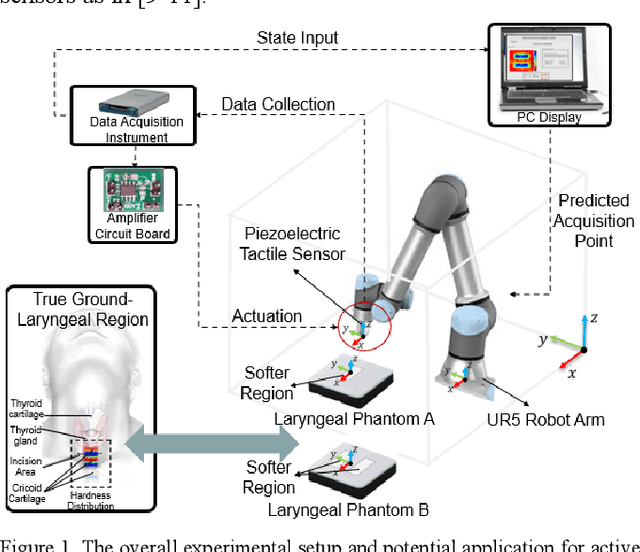
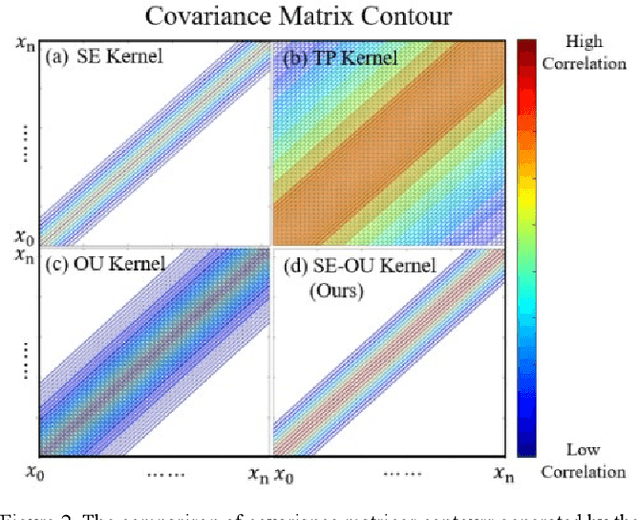
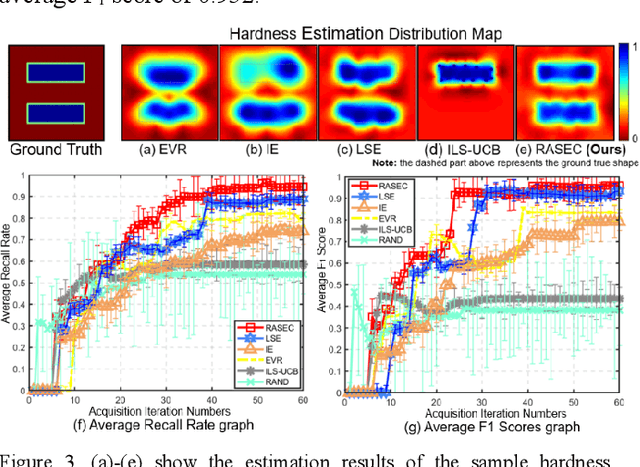
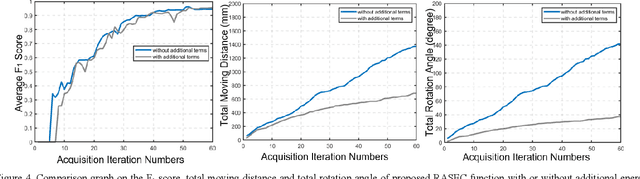
A novel palpation-based incision detection strategy in the laryngeal region, potentially for robotic tracheotomy, is proposed in this letter. A tactile sensor is introduced to measure tissue hardness in the specific laryngeal region by gentle contact. The kernel fusion method is proposed to combine the Squared Exponential (SE) kernel with Ornstein-Uhlenbeck (OU) kernel to figure out the drawbacks that the existing kernel functions are not sufficiently optimal in this scenario. Moreover, we further regularize exploration factor and greed factor, and the tactile sensor's moving distance and the robotic base link's rotation angle during the incision localization process are considered as new factors in the acquisition strategy. We conducted simulation and physical experiments to compare the newly proposed algorithm - Rescaling Acquisition Strategy with Energy Constraints (RASEC) in trachea detection with current palpation-based acquisition strategies. The result indicates that the proposed acquisition strategy with fusion kernel can successfully localize the incision with the highest algorithm performance (Average Precision 0.932, Average Recall 0.973, Average F1 score 0.952). During the robotic palpation process, the cumulative moving distance is reduced by 50%, and the cumulative rotation angle is reduced by 71.4% with no sacrifice in the comprehensive performance capabilities. Therefore, it proves that RASEC can efficiently suggest the incision zone in the laryngeal region and greatly reduced the energy loss.
Class-Incremental Domain Adaptation with Smoothing and Calibration for Surgical Report Generation
Jul 23, 2021



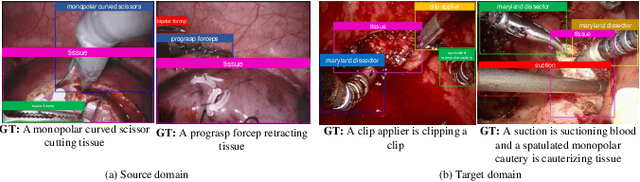
Generating surgical reports aimed at surgical scene understanding in robot-assisted surgery can contribute to documenting entry tasks and post-operative analysis. Despite the impressive outcome, the deep learning model degrades the performance when applied to different domains encountering domain shifts. In addition, there are new instruments and variations in surgical tissues appeared in robotic surgery. In this work, we propose class-incremental domain adaptation (CIDA) with a multi-layer transformer-based model to tackle the new classes and domain shift in the target domain to generate surgical reports during robotic surgery. To adapt incremental classes and extract domain invariant features, a class-incremental (CI) learning method with supervised contrastive (SupCon) loss is incorporated with a feature extractor. To generate caption from the extracted feature, curriculum by one-dimensional gaussian smoothing (CBS) is integrated with a multi-layer transformer-based caption prediction model. CBS smoothes the features embedding using anti-aliasing and helps the model to learn domain invariant features. We also adopt label smoothing (LS) to calibrate prediction probability and obtain better feature representation with both feature extractor and captioning model. The proposed techniques are empirically evaluated by using the datasets of two surgical domains, such as nephrectomy operations and transoral robotic surgery. We observe that domain invariant feature learning and the well-calibrated network improves the surgical report generation performance in both source and target domain under domain shift and unseen classes in the manners of one-shot and few-shot learning. The code is publicly available at https://github.com/XuMengyaAmy/CIDACaptioning.
Learning Domain Adaptation with Model Calibration for Surgical Report Generation in Robotic Surgery
Mar 31, 2021


Generating a surgical report in robot-assisted surgery, in the form of natural language expression of surgical scene understanding, can play a significant role in document entry tasks, surgical training, and post-operative analysis. Despite the state-of-the-art accuracy of the deep learning algorithm, the deployment performance often drops when applied to the Target Domain (TD) data. For this purpose, we develop a multi-layer transformer-based model with the gradient reversal adversarial learning to generate a caption for the multi-domain surgical images that can describe the semantic relationship between instruments and surgical Region of Interest (ROI). In the gradient reversal adversarial learning scheme, the gradient multiplies with a negative constant and updates adversarially in backward propagation, discriminating between the source and target domains and emerging domain-invariant features. We also investigate model calibration with label smoothing technique and the effect of a well-calibrated model for the penultimate layer's feature representation and Domain Adaptation (DA). We annotate two robotic surgery datasets of MICCAI robotic scene segmentation and Transoral Robotic Surgery (TORS) with the captions of procedures and empirically show that our proposed method improves the performance in both source and target domain surgical reports generation in the manners of unsupervised, zero-shot, one-shot, and few-shot learning.