 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompassAD: Intent-Driven 3D Affordance Grounding in Functionally Competing Objects
Apr 02, 2026When told to "cut the apple," a robot must choose the knife over nearby scissors, despite both objects affording the same cutting function. In real-world scenes, multiple objects may share identical affordances, yet only one is appropriate under the given task context. We call such cases confusing pairs. However, existing 3D affordance methods largely sidestep this challenge by evaluating isolated single objects, often with explicit category names provided in the query. We formalize Multi-Object Affordance Grounding under Intent-Driven Instructions, a new 3D affordance setting that requires predicting a per-point affordance mask on the correct object within a cluttered multi-object point cloud, conditioned on implicit natural language intent. To study this problem, we construct CompassAD, the first benchmark centered on implicit intent in confusable multi-object scenes. It comprises 30 confusing object pairs spanning 16 affordance types, 6,422 scenes, and 88K+ query-answer pairs. Furthermore, we propose CompassNet, a framework that incorporates two dedicated modules tailored to this task. Instance-bounded Cross Injection (ICI) constrains language-geometry alignment within object boundaries to prevent cross-object semantic leakage. Bi-level Contrastive Refinement (BCR) enforces discrimination at both geometric-group and point levels, sharpening distinctions between target and confusable surfaces. Extensive experiments demonstrate state-of-the-art results on both seen and unseen queries, and deployment on a robotic manipulator confirms effective transfer to real-world grasping in confusing multi-object scenes.
Trace-Focused Diffusion Policy for Multi-Modal Action Disambiguation in Long-Horizon Robotic Manipulation
Feb 07, 2026Generative model-based policies have shown strong performance in imitation-based robotic manipulation by learning action distributions from demonstrations. However, in long-horizon tasks, visually similar observations often recur across execution stages while requiring distinct actions, which leads to ambiguous predictions when policies are conditioned only on instantaneous observations, termed multi-modal action ambiguity (MA2). To address this challenge, we propose the Trace-Focused Diffusion Policy (TF-DP), a simple yet effective diffusion-based framework that explicitly conditions action generation on the robot's execution history. TF-DP represents historical motion as an explicit execution trace and projects it into the visual observation space, providing stage-aware context when current observations alone are insufficient. In addition, the induced trace-focused field emphasizes task-relevant regions associated with historical motion, improving robustness to background visual disturbances. We evaluate TF-DP on real-world robotic manipulation tasks exhibiting pronounced multi-modal action ambiguity and visually cluttered conditions. Experimental results show that TF-DP improves temporal consistency and robustness, outperforming the vanilla diffusion policy by 80.56 percent on tasks with multi-modal action ambiguity and by 86.11 percent under visual disturbances, while maintaining inference efficiency with only a 6.4 percent runtime increase. These results demonstrate that execution-trace conditioning offers a scalable and principled approach for robust long-horizon robotic manipulation within a single policy.
HoloLLM: Multisensory Foundation Model for Language-Grounded Human Sensing and Reasoning
May 23, 2025Embodied agents operating in smart homes must understand human behavior through diverse sensory inputs and communicate via natural language. While Vision-Language Models (VLMs) have enabled impressive language-grounded perception, their reliance on visual data limits robustness in real-world scenarios with occlusions, poor lighting, or privacy constraints. In this paper, we introduce HoloLLM, a Multimodal Large Language Model (MLLM) that integrates uncommon but powerful sensing modalities, such as LiDAR, infrared, mmWave radar, and WiFi, to enable seamless human perception and reasoning across heterogeneous environments. We address two key challenges: (1) the scarcity of aligned modality-text data for rare sensors, and (2) the heterogeneity of their physical signal representations. To overcome these, we design a Universal Modality-Injection Projector (UMIP) that enhances pre-aligned modality embeddings with fine-grained, text-aligned features from tailored encoders via coarse-to-fine cross-attention without introducing significant alignment overhead. We further introduce a human-VLM collaborative data curation pipeline to generate paired textual annotations for sensing datasets. Extensive experiments on two newly constructed benchmarks show that HoloLLM significantly outperforms existing MLLMs, improving language-grounded human sensing accuracy by up to 30%. This work establishes a new foundation for real-world, language-informed multisensory embodied intelligence.
REI-Bench: Can Embodied Agents Understand Vague Human Instructions in Task Planning?
May 19, 2025Robot task planning decomposes human instructions into executable action sequences that enable robots to complete a series of complex tasks. Although recent large language model (LLM)-based task planners achieve amazing performance, they assume that human instructions are clear and straightforward. However, real-world users are not experts, and their instructions to robots often contain significant vagueness. Linguists suggest that such vagueness frequently arises from referring expressions (REs), whose meanings depend heavily on dialogue context and environment. This vagueness is even more prevalent among the elderly and children, who robots should serve more. This paper studies how such vagueness in REs within human instructions affects LLM-based robot task planning and how to overcome this issue. To this end, we propose the first robot task planning benchmark with vague REs (REI-Bench), where we discover that the vagueness of REs can severely degrade robot planning performance, leading to success rate drops of up to 77.9%. We also observe that most failure cases stem from missing objects in planners. To mitigate the REs issue, we propose a simple yet effective approach: task-oriented context cognition, which generates clear instructions for robots, achieving state-of-the-art performance compared to aware prompt and chains of thought. This work contributes to the research community of human-robot interaction (HRI) by making robot task planning more practical, particularly for non-expert users, e.g., the elderly and children.
NoisyEQA: Benchmarking Embodied Question Answering Against Noisy Queries
Dec 14, 2024



The rapid advancement of Vision-Language Models (VLMs) has significantly advanced the development of Embodied Question Answering (EQA), enhancing agents' abilities in language understanding and reasoning within complex and realistic scenarios. However, EQA in real-world scenarios remains challenging, as human-posed questions often contain noise that can interfere with an agent's exploration and response, bringing challenges especially for language beginners and non-expert users. To address this, we introduce a NoisyEQA benchmark designed to evaluate an agent's ability to recognize and correct noisy questions. This benchmark introduces four common types of noise found in real-world applications: Latent Hallucination Noise, Memory Noise, Perception Noise, and Semantic Noise generated through an automated dataset creation framework. Additionally, we also propose a 'Self-Correction' prompting mechanism and a new evaluation metric to enhance and measure both noise detection capability and answer quality. Our comprehensive evaluation reveals that current EQA agents often struggle to detect noise in questions, leading to responses that frequently contain erroneous information. Through our Self-Correct Prompting mechanism, we can effectively improve the accuracy of agent answers.
Enhancing Dataset Distillation via Label Inconsistency Elimination and Learning Pattern Refinement
Oct 17, 2024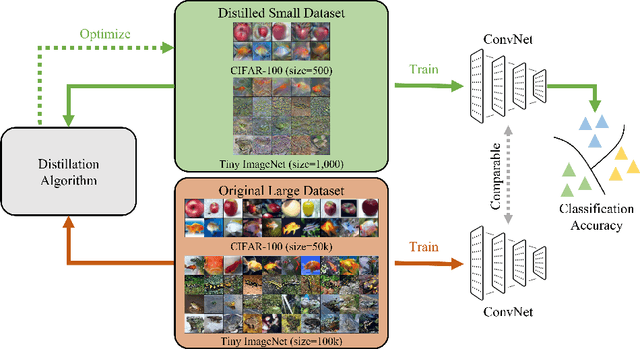
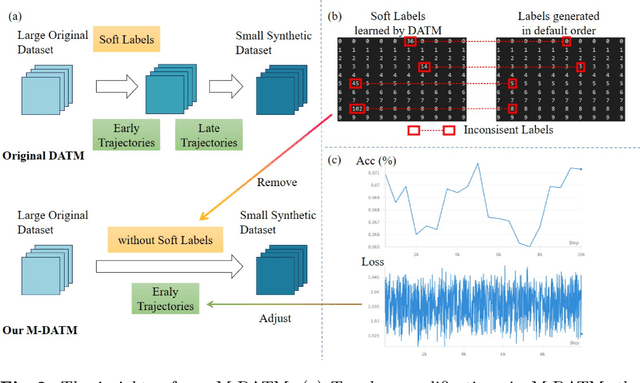

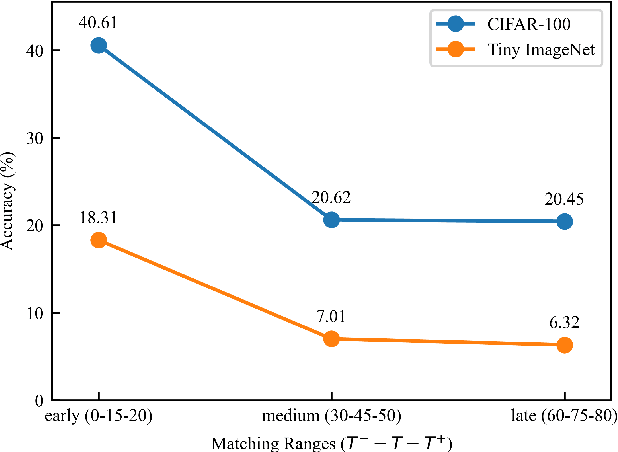
Dataset Distillation (DD) seeks to create a condensed dataset that, when used to train a model, enables the model to achieve performance similar to that of a model trained on the entire original dataset. It relieves the model training from processing massive data and thus reduces the computation resources, storage, and time costs. This paper illustrates our solution that ranks 1st in the ECCV-2024 Data Distillation Challenge (track 1). Our solution, Modified Difficulty-Aligned Trajectory Matching (M-DATM), introduces two key modifications to the original state-of-the-art method DATM: (1) the soft labels learned by DATM do not achieve one-to-one correspondence with the counterparts generated by the official evaluation script, so we remove the soft labels technique to alleviate such inconsistency; (2) since the removal of soft labels makes it harder for the synthetic dataset to learn late trajectory information, particularly on Tiny ImageNet, we reduce the matching range, allowing the synthetic data to concentrate more on the easier patterns. In the final evaluation, our M-DATM achieved accuracies of 0.4061 and 0.1831 on the CIFAR-100 and Tiny ImageNet datasets, ranking 1st in the Fixed Images Per Class (IPC) Track.