 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Trade-Off Between Transparency and Security in Adversarial Machine Learning
Nov 14, 2025Transparency and security are both central to Responsible AI, but they may conflict in adversarial settings. We investigate the strategic effect of transparency for agents through the lens of transferable adversarial example attacks. In transferable adversarial example attacks, attackers maliciously perturb their inputs using surrogate models to fool a defender's target model. These models can be defended or undefended, with both players having to decide which to use. Using a large-scale empirical evaluation of nine attacks across 181 models, we find that attackers are more successful when they match the defender's decision; hence, obscurity could be beneficial to the defender. With game theory, we analyze this trade-off between transparency and security by modeling this problem as both a Nash game and a Stackelberg game, and comparing the expected outcomes. Our analysis confirms that only knowing whether a defender's model is defended or not can sometimes be enough to damage its security. This result serves as an indicator of the general trade-off between transparency and security, suggesting that transparency in AI systems can be at odds with security. Beyond adversarial machine learning, our work illustrates how game-theoretic reasoning can uncover conflicts between transparency and security.
fAux: Testing Individual Fairness via Gradient Alignment
Oct 10, 2022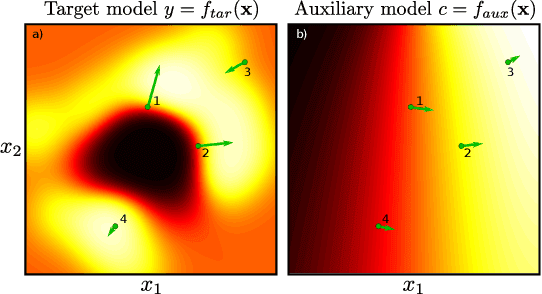
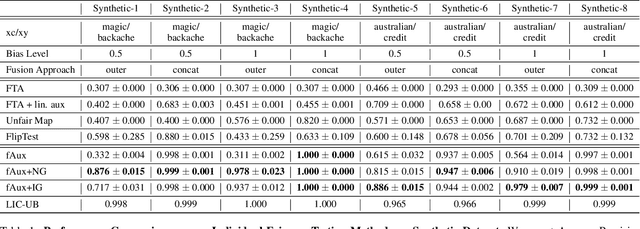


Machine learning models are vulnerable to biases that result in unfair treatment of individuals from different populations. Recent work that aims to test a model's fairness at the individual level either relies on domain knowledge to choose metrics, or on input transformations that risk generating out-of-domain samples. We describe a new approach for testing individual fairness that does not have either requirement. We propose a novel criterion for evaluating individual fairness and develop a practical testing method based on this criterion which we call fAux (pronounced fox). This is based on comparing the derivatives of the predictions of the model to be tested with those of an auxiliary model, which predicts the protected variable from the observed data. We show that the proposed method effectively identifies discrimination on both synthetic and real-world datasets, and has quantitative and qualitative advantages over contemporary methods.
A Solver + Gradient Descent Training Algorithm for Deep Neural Networks
Jul 07, 2022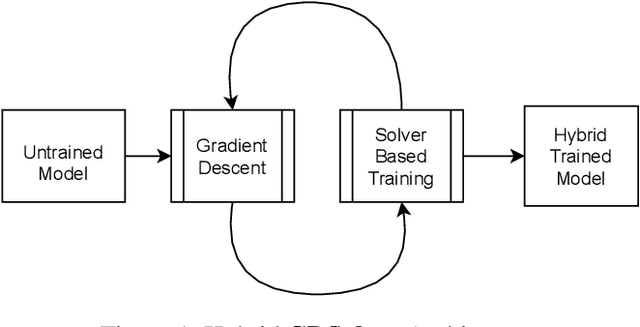
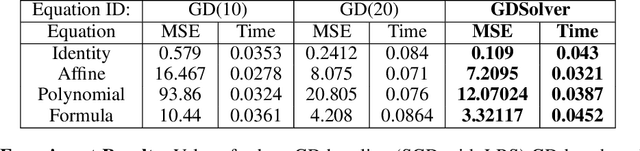

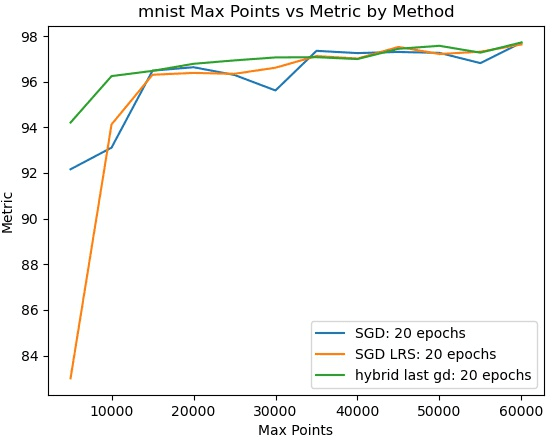
We present a novel hybrid algorithm for training Deep Neural Networks that combines the state-of-the-art Gradient Descent (GD) method with a Mixed Integer Linear Programming (MILP) solver, outperforming GD and variants in terms of accuracy, as well as resource and data efficiency for both regression and classification tasks. Our GD+Solver hybrid algorithm, called GDSolver, works as follows: given a DNN $D$ as input, GDSolver invokes GD to partially train $D$ until it gets stuck in a local minima, at which point GDSolver invokes an MILP solver to exhaustively search a region of the loss landscape around the weight assignments of $D$'s final layer parameters with the goal of tunnelling through and escaping the local minima. The process is repeated until desired accuracy is achieved. In our experiments, we find that GDSolver not only scales well to additional data and very large model sizes, but also outperforms all other competing methods in terms of rates of convergence and data efficiency. For regression tasks, GDSolver produced models that, on average, had 31.5% lower MSE in 48% less time, and for classification tasks on MNIST and CIFAR10, GDSolver was able to achieve the highest accuracy over all competing methods, using only 50% of the training data that GD baselines required.
Nonlocal optimization of binary neural networks
Apr 05, 2022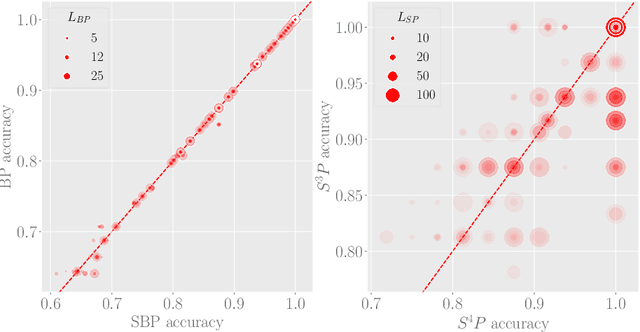
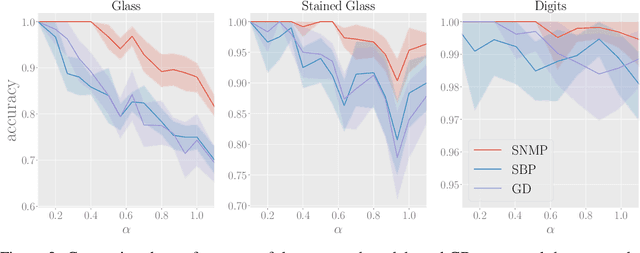
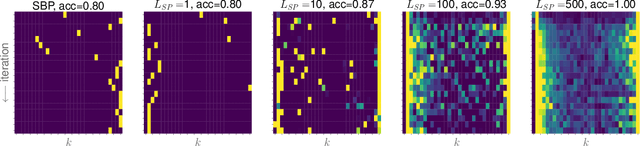
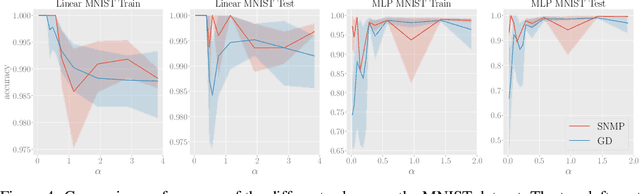
We explore training Binary Neural Networks (BNNs) as a discrete variable inference problem over a factor graph. We study the behaviour of this conversion in an under-parameterized BNN setting and propose stochastic versions of Belief Propagation (BP) and Survey Propagation (SP) message passing algorithms to overcome the intractability of their current formulation. Compared to traditional gradient methods for BNNs, our results indicate that both stochastic BP and SP find better configurations of the parameters in the BNN.
Scalable Whitebox Attacks on Tree-based Models
Mar 31, 2022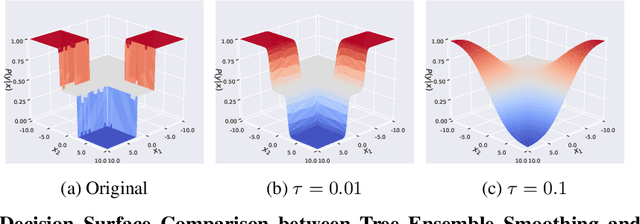
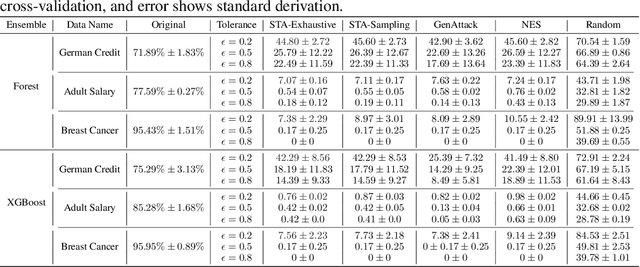
Adversarial robustness is one of the essential safety criteria for guaranteeing the reliability of machine learning models. While various adversarial robustness testing approaches were introduced in the last decade, we note that most of them are incompatible with non-differentiable models such as tree ensembles. Since tree ensembles are widely used in industry, this reveals a crucial gap between adversarial robustness research and practical applications. This paper proposes a novel whitebox adversarial robustness testing approach for tree ensemble models. Concretely, the proposed approach smooths the tree ensembles through temperature controlled sigmoid functions, which enables gradient descent-based adversarial attacks. By leveraging sampling and the log-derivative trick, the proposed approach can scale up to testing tasks that were previously unmanageable. We compare the approach against both random perturbations and blackbox approaches on multiple public datasets (and corresponding models). Our results show that the proposed method can 1) successfully reveal the adversarial vulnerability of tree ensemble models without causing computational pressure for testing and 2) flexibly balance the search performance and time complexity to meet various testing criteria.
PUMA: Performance Unchanged Model Augmentation for Training Data Removal
Mar 02, 2022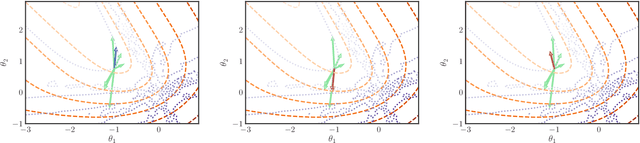
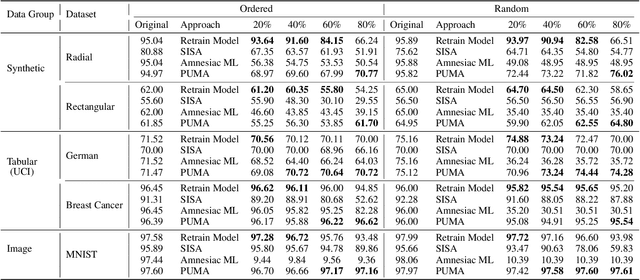
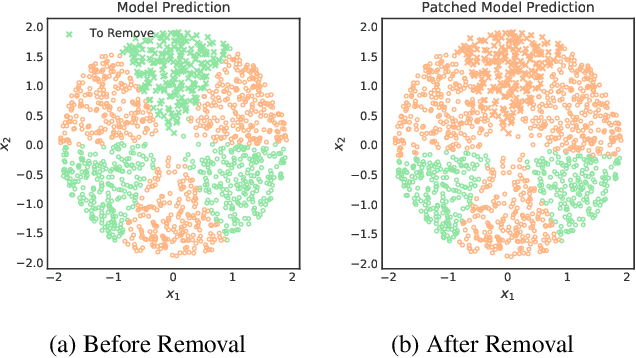

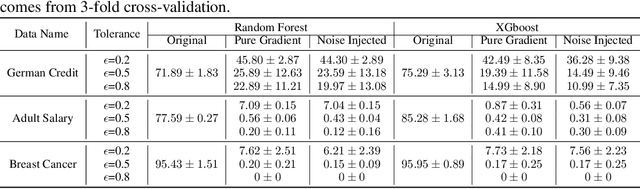
Preserving the performance of a trained model while removing unique characteristics of marked training data points is challenging. Recent research usually suggests retraining a model from scratch with remaining training data or refining the model by reverting the model optimization on the marked data points. Unfortunately, aside from their computational inefficiency, those approaches inevitably hurt the resulting model's generalization ability since they remove not only unique characteristics but also discard shared (and possibly contributive) information. To address the performance degradation problem, this paper presents a novel approach called Performance Unchanged Model Augmentation~(PUMA). The proposed PUMA framework explicitly models the influence of each training data point on the model's generalization ability with respect to various performance criteria. It then complements the negative impact of removing marked data by reweighting the remaining data optimally. To demonstrate the effectiveness of the PUMA framework, we compared it with multiple state-of-the-art data removal techniques in the experiments, where we show the PUMA can effectively and efficiently remove the unique characteristics of marked training data without retraining the model that can 1) fool a membership attack, and 2) resist performance degradation. In addition, as PUMA estimates the data importance during its operation, we show it could serve to debug mislabelled data points more efficiently than existing approaches.
Parity Partition Coding for Sharp Multi-Label Classification
Aug 23, 2019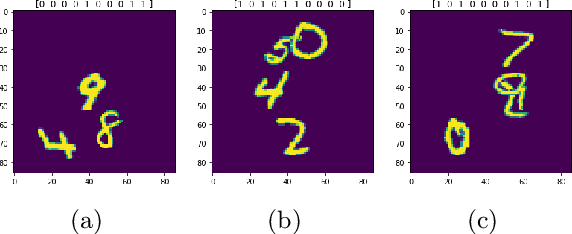
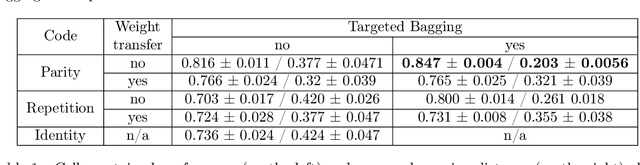
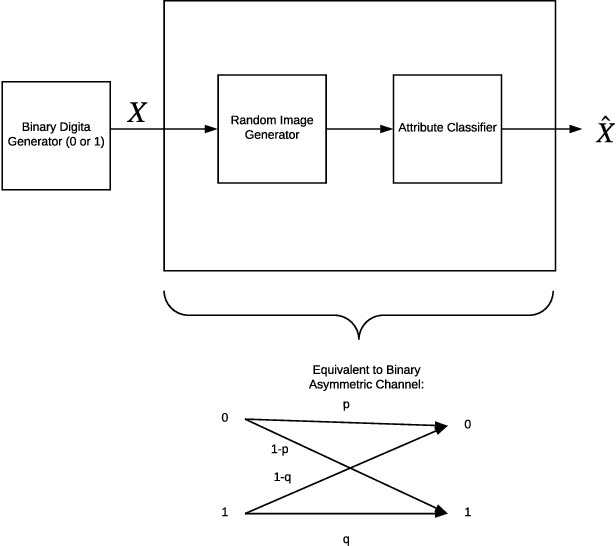
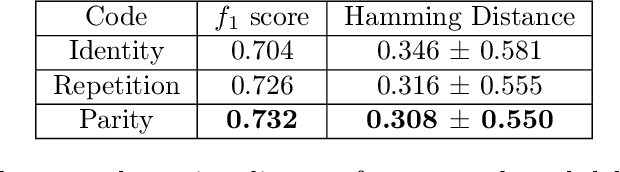
The problem of efficiently training and evaluating image classifiers that can distinguish between a large number of object categories is considered. A novel metric, sharpness, is proposed which is defined as the fraction of object categories that are above a threshold accuracy. To estimate sharpness (along with a confidence value), a technique called fraction-accurate estimation is introduced which samples categories and samples instances from these categories. In addition, a technique called parity partition coding, a special type of error correcting output code, is introduced, increasing sharpness, while reducing the multi-class problem to a multi-label one with exponentially fewer outputs. We demonstrate that this approach outperforms the baseline model for both MultiMNIST and CelebA, while requiring fewer parameters and exceeding state of the art accuracy on individual labels.