 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating AI into CCTV Systems: A Comprehensive Evaluation of Smart Video Surveillance in Community Space
Dec 04, 2023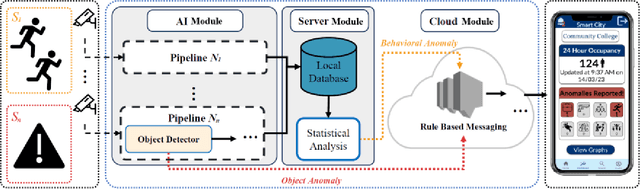

This article presents an AI-enabled Smart Video Surveillance (SVS) designed to enhance safety in community spaces such as educational and recreational areas, and small businesses. The proposed system innovatively integrates with existing CCTV and wired camera networks, simplifying its adoption across various community cases to leverage recent AI advancements. Our SVS system, focusing on privacy, uses metadata instead of pixel data for activity recognition, aligning with ethical standards. It features cloud-based infrastructure and a mobile app for real-time, privacy-conscious alerts in communities. This article notably pioneers a comprehensive real-world evaluation of the SVS system, covering AI-driven visual processing, statistical analysis, database management, cloud communication, and user notifications. It's also the first to assess an end-to-end anomaly detection system's performance, vital for identifying potential public safety incidents. For our evaluation, we implemented the system in a community college, serving as an ideal model to exemplify the proposed system's capabilities. Our findings in this setting demonstrate the system's robustness, with throughput, latency, and scalability effectively managing 16 CCTV cameras. The system maintained a consistent 16.5 frames per second (FPS) over a 21-hour operation. The average end-to-end latency for detecting behavioral anomalies and alerting users was 26.76 seconds.
Real-Time Online Unsupervised Domain Adaptation for Real-World Person Re-identification
Jun 06, 2023Following the popularity of Unsupervised Domain Adaptation (UDA) in person re-identification, the recently proposed setting of Online Unsupervised Domain Adaptation (OUDA) attempts to bridge the gap towards practical applications by introducing a consideration of streaming data. However, this still falls short of truly representing real-world applications. This paper defines the setting of Real-world Real-time Online Unsupervised Domain Adaptation (R$^2$OUDA) for Person Re-identification. The R$^2$OUDA setting sets the stage for true real-world real-time OUDA, bringing to light four major limitations found in real-world applications that are often neglected in current research: system generated person images, subset distribution selection, time-based data stream segmentation, and a segment-based time constraint. To address all aspects of this new R$^2$OUDA setting, this paper further proposes Real-World Real-Time Online Streaming Mutual Mean-Teaching (R$^2$MMT), a novel multi-camera system for real-world person re-identification. Taking a popular person re-identification dataset, R$^2$MMT was used to construct over 100 data subsets and train more than 3000 models, exploring the breadth of the R$^2$OUDA setting to understand the training time and accuracy trade-offs and limitations for real-world applications. R$^2$MMT, a real-world system able to respect the strict constraints of the proposed R$^2$OUDA setting, achieves accuracies within 0.1% of comparable OUDA methods that cannot be applied directly to real-world applications.
Real-World Community-in-the-Loop Smart Video Surveillance -- A Case Study at a Community College
Mar 22, 2023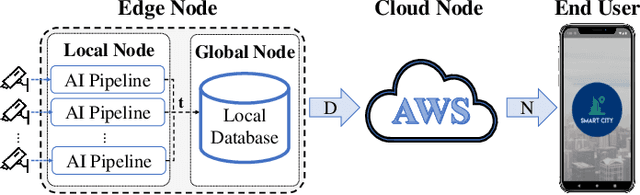
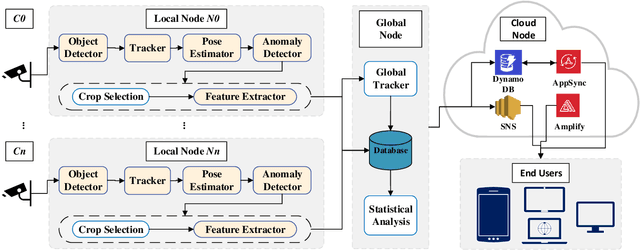
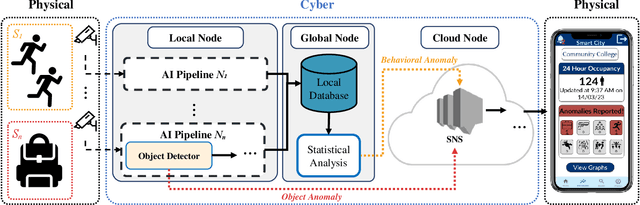
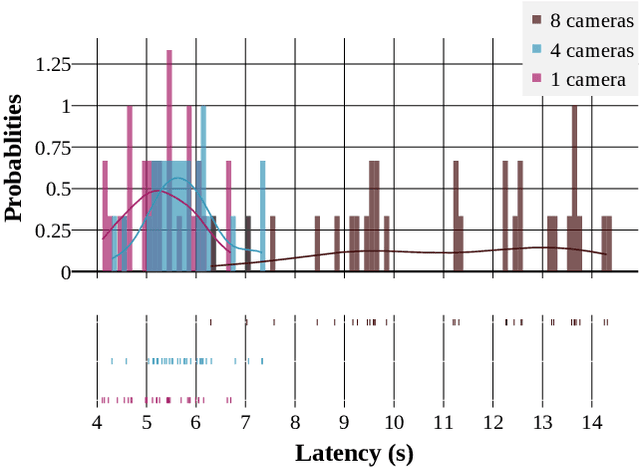
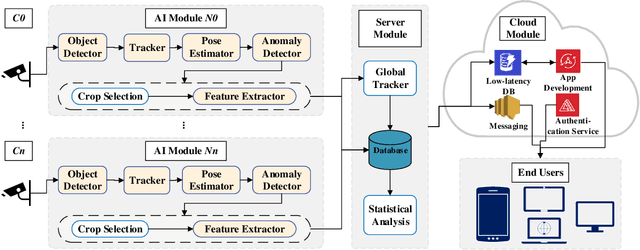
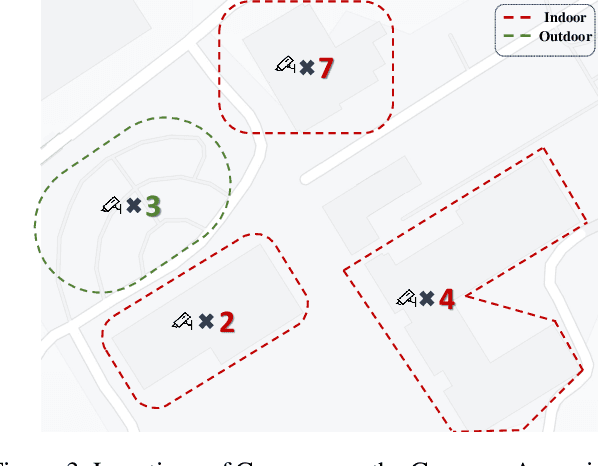
Smart Video surveillance systems have become important recently for ensuring public safety and security, especially in smart cities. However, applying real-time artificial intelligence technologies combined with low-latency notification and alarming has made deploying these systems quite challenging. This paper presents a case study for designing and deploying smart video surveillance systems based on a real-world testbed at a community college. We primarily focus on a smart camera-based system that can identify suspicious/abnormal activities and alert the stakeholders and residents immediately. The paper highlights and addresses different algorithmic and system design challenges to guarantee real-time high-accuracy video analytics processing in the testbed. It also presents an example of cloud system infrastructure and a mobile application for real-time notification to keep students, faculty/staff, and responsible security personnel in the loop. At the same time, it covers the design decision to maintain communities' privacy and ethical requirements as well as hardware configuration and setups. We evaluate the system's performance using throughput and end-to-end latency. The experiment results show that, on average, our system's end-to-end latency to notify the end users in case of detecting suspicious objects is 5.3, 5.78, and 11.11 seconds when running 1, 4, and 8 cameras, respectively. On the other hand, in case of detecting anomalous behaviors, the system could notify the end users with 7.3, 7.63, and 20.78 seconds average latency. These results demonstrate that the system effectively detects and notifies abnormal behaviors and suspicious objects to the end users within a reasonable period. The system can run eight cameras simultaneously at a 32.41 Frame Per Second (FPS) rate.
Understanding Policy and Technical Aspects of AI-Enabled Smart Video Surveillance to Address Public Safety
Feb 08, 2023Recent advancements in artificial intelligence (AI) have seen the emergence of smart video surveillance (SVS) in many practical applications, particularly for building safer and more secure communities in our urban environments. Cognitive tasks, such as identifying objects, recognizing actions, and detecting anomalous behaviors, can produce data capable of providing valuable insights to the community through statistical and analytical tools. However, artificially intelligent surveillance systems design requires special considerations for ethical challenges and concerns. The use and storage of personally identifiable information (PII) commonly pose an increased risk to personal privacy. To address these issues, this paper identifies the privacy concerns and requirements needed to address when designing AI-enabled smart video surveillance. Further, we propose the first end-to-end AI-enabled privacy-preserving smart video surveillance system that holistically combines computer vision analytics, statistical data analytics, cloud-native services, and end-user applications. Finally, we propose quantitative and qualitative metrics to evaluate intelligent video surveillance systems. The system shows the 17.8 frame-per-second (FPS) processing in extreme video scenes. However, considering privacy in designing such a system results in preferring the pose-based algorithm to the pixel-based one. This choice resulted in dropping accuracy in both action and anomaly detection tasks. The results drop from 97.48 to 73.72 in anomaly detection and 96 to 83.07 in the action detection task. On average, the latency of the end-to-end system is 36.1 seconds.
Ancilia: Scalable Intelligent Video Surveillance for the Artificial Intelligence of Things
Jan 09, 2023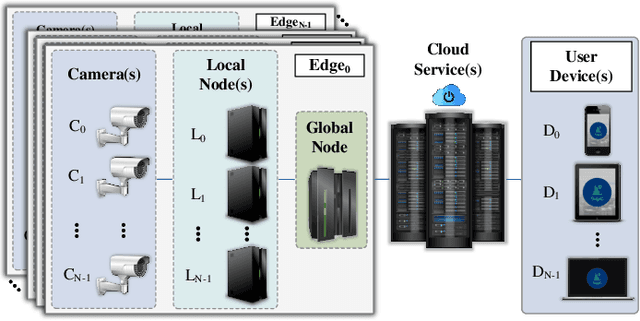
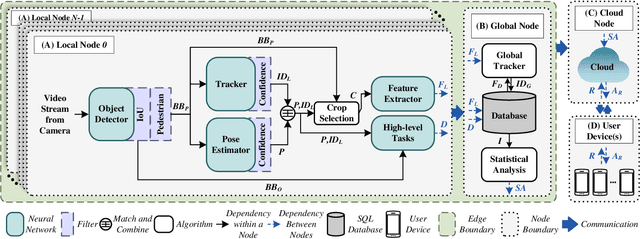
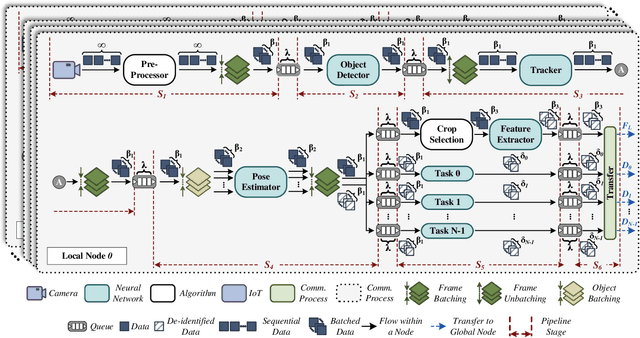
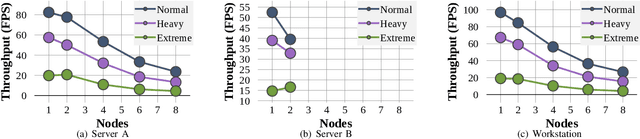
With the advancement of vision-based artificial intelligence, the proliferation of the Internet of Things connected cameras, and the increasing societal need for rapid and equitable security, the demand for accurate real-time intelligent surveillance has never been higher. This article presents Ancilia, an end-to-end scalable, intelligent video surveillance system for the Artificial Intelligence of Things. Ancilia brings state-of-the-art artificial intelligence to real-world surveillance applications while respecting ethical concerns and performing high-level cognitive tasks in real-time. Ancilia aims to revolutionize the surveillance landscape, to bring more effective, intelligent, and equitable security to the field, resulting in safer and more secure communities without requiring people to compromise their right to privacy.
Understanding Ethics, Privacy, and Regulations in Smart Video Surveillance for Public Safety
Dec 25, 2022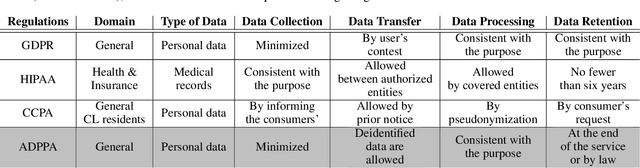
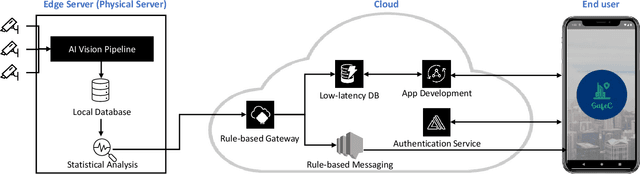
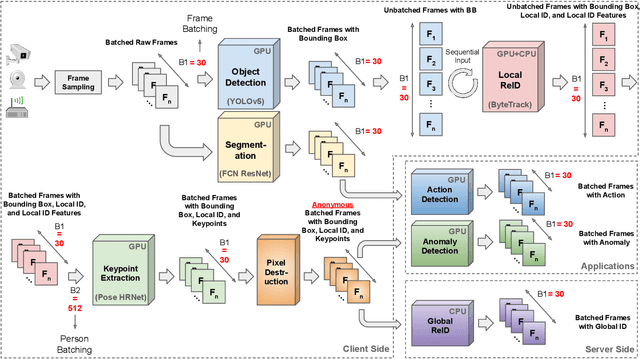
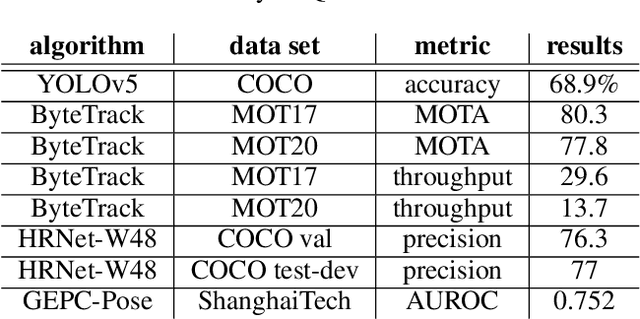
Recently, Smart Video Surveillance (SVS) systems have been receiving more attention among scholars and developers as a substitute for the current passive surveillance systems. These systems are used to make the policing and monitoring systems more efficient and improve public safety. However, the nature of these systems in monitoring the public's daily activities brings different ethical challenges. There are different approaches for addressing privacy issues in implementing the SVS. In this paper, we are focusing on the role of design considering ethical and privacy challenges in SVS. Reviewing four policy protection regulations that generate an overview of best practices for privacy protection, we argue that ethical and privacy concerns could be addressed through four lenses: algorithm, system, model, and data. As an case study, we describe our proposed system and illustrate how our system can create a baseline for designing a privacy perseverance system to deliver safety to society. We used several Artificial Intelligence algorithms, such as object detection, single and multi camera re-identification, action recognition, and anomaly detection, to provide a basic functional system. We also use cloud-native services to implement a smartphone application in order to deliver the outputs to the end users.
CHAD: Charlotte Anomaly Dataset
Dec 19, 2022In recent years, we have seen a significant interest in data-driven deep learning approaches for video anomaly detection, where an algorithm must determine if specific frames of a video contain abnormal behaviors. However, video anomaly detection is particularly context-specific, and the availability of representative datasets heavily limits real-world accuracy. Additionally, the metrics currently reported by most state-of-the-art methods often do not reflect how well the model will perform in real-world scenarios. In this article, we present the Charlotte Anomaly Dataset (CHAD). CHAD is a high-resolution, multi-camera anomaly dataset in a commercial parking lot setting. In addition to frame-level anomaly labels, CHAD is the first anomaly dataset to include bounding box, identity, and pose annotations for each actor. This is especially beneficial for skeleton-based anomaly detection, which is useful for its lower computational demand in real-world settings. CHAD is also the first anomaly dataset to contain multiple views of the same scene. With four camera views and over 1.15 million frames, CHAD is the largest fully annotated anomaly detection dataset including person annotations, collected from continuous video streams from stationary cameras for smart video surveillance applications. To demonstrate the efficacy of CHAD for training and evaluation, we benchmark two state-of-the-art skeleton-based anomaly detection algorithms on CHAD and provide comprehensive analysis, including both quantitative results and qualitative examination.
Pishgu: Universal Path Prediction Architecture through Graph Isomorphism and Attentive Convolution
Oct 14, 2022
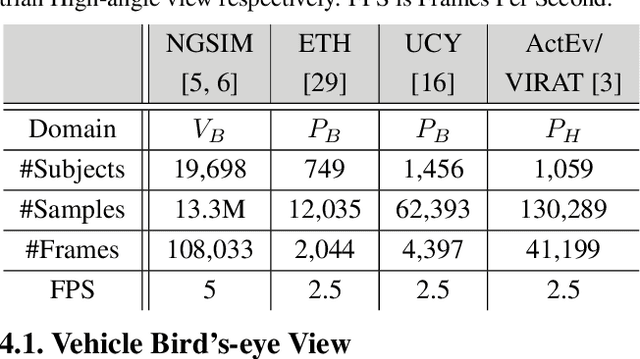
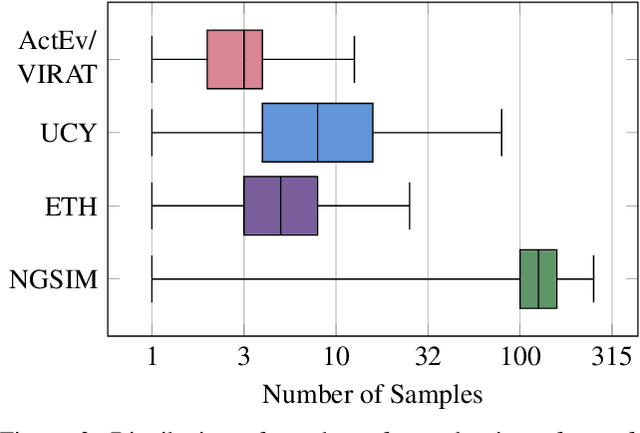
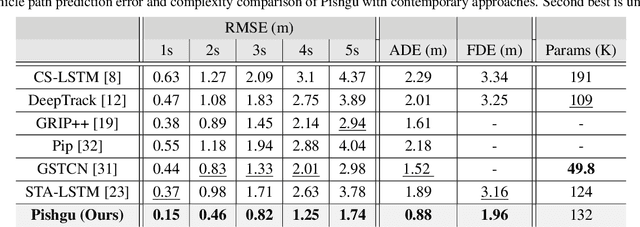
Path prediction is an essential task for several real-world real-time applications, from autonomous driving and video surveillance to environmental monitoring. Most existing approaches are computation-intensive and only target a narrow domain (e.g., a specific point of view for a particular subject). However, many real-time applications demand a universal path predictor that can work across different subjects (vehicles, pedestrians), perspectives (bird's-eye, high-angle), and scenes (sidewalk, highway). This article proposes Pishgu, a universal graph isomorphism approach for attentive path prediction that accounts for environmental challenges. Pishgu captures the inter-dependencies within the subjects in each frame by taking advantage of Graph Isomorphism Networks. In addition, an attention module is adopted to represent the intrinsic relations of the subjects of interest with their surroundings. We evaluate the adaptability of our approach to multiple publicly available vehicle (bird's-eye view) and pedestrian (bird's-eye and high-angle view) path prediction datasets. Pishgu's universal solution outperforms existing domain-focused methods by producing state-of-the-art results for vehicle bird's-eye view by 42% and 61% and pedestrian high-angle views by 23% and 22% in terms of ADE and FDE, respectively. Moreover, we analyze the domain-specific details for various datasets to understand their effect on path prediction and model interpretation. Although our model is a single solution for path prediction problems and defines a new standard in multiple domains, it still has a comparable complexity to state-of-the-art models, which makes it suitable for real-world application. We also report the latency and throughput for all three domains on multiple embedded processors.
ADG-Pose: Automated Dataset Generation for Real-World Human Pose Estimation
Feb 01, 2022Recent advancements in computer vision have seen a rise in the prominence of applications using neural networks to understand human poses. However, while accuracy has been steadily increasing on State-of-the-Art datasets, these datasets often do not address the challenges seen in real-world applications. These challenges are dealing with people distant from the camera, people in crowds, and heavily occluded people. As a result, many real-world applications have trained on data that does not reflect the data present in deployment, leading to significant underperformance. This article presents ADG-Pose, a method for automatically generating datasets for real-world human pose estimation. These datasets can be customized to determine person distances, crowdedness, and occlusion distributions. Models trained with our method are able to perform in the presence of these challenges where those trained on other datasets fail. Using ADG-Pose, end-to-end accuracy for real-world skeleton-based action recognition sees a 20% increase on scenes with moderate distance and occlusion levels, and a 4X increase on distant scenes where other models failed to perform better than random.
Real-World Graph Convolution Networks (RW-GCNs) for Action Recognition in Smart Video Surveillance
Jan 15, 2022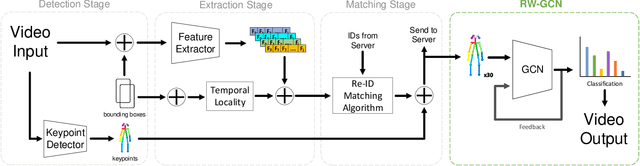
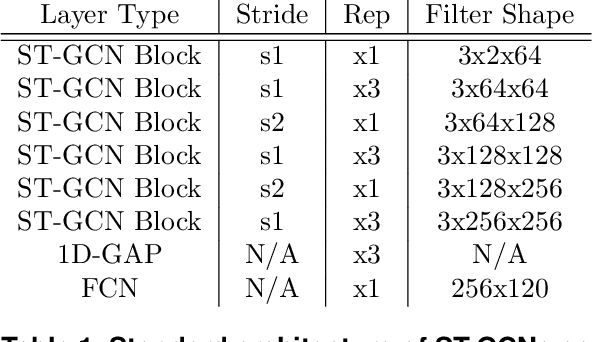

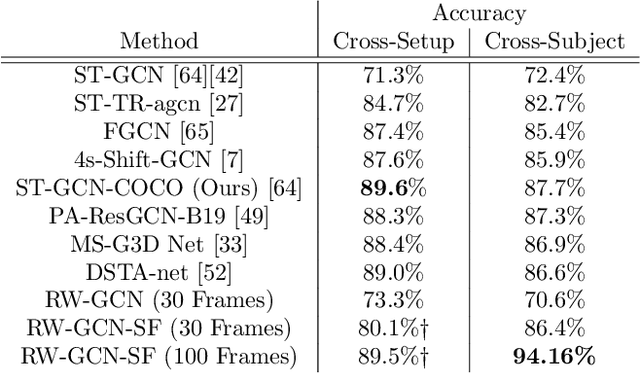
Action recognition is a key algorithmic part of emerging on-the-edge smart video surveillance and security systems. Skeleton-based action recognition is an attractive approach which, instead of using RGB pixel data, relies on human pose information to classify appropriate actions. However, existing algorithms often assume ideal conditions that are not representative of real-world limitations, such as noisy input, latency requirements, and edge resource constraints. To address the limitations of existing approaches, this paper presents Real-World Graph Convolution Networks (RW-GCNs), an architecture-level solution for meeting the domain constraints of Real World Skeleton-based Action Recognition. Inspired by the presence of feedback connections in the human visual cortex, RW-GCNs leverage attentive feedback augmentation on existing near state-of-the-art (SotA) Spatial-Temporal Graph Convolution Networks (ST-GCNs). The ST-GCNs' design choices are derived from information theory-centric principles to address both the spatial and temporal noise typically encountered in end-to-end real-time and on-the-edge smart video systems. Our results demonstrate RW-GCNs' ability to serve these applications by achieving a new SotA accuracy on the NTU-RGB-D-120 dataset at 94.1%, and achieving 32X less latency than baseline ST-GCN applications while still achieving 90.4% accuracy on the Northwestern UCLA dataset in the presence of spatial keypoint noise. RW-GCNs further show system scalability by running on the 10X cost effective NVIDIA Jetson Nano (as opposed to NVIDIA Xavier NX), while still maintaining a respectful range of throughput (15.6 to 5.5 Actions per Second) on the resource constrained device. The code is available here: https://github.com/TeCSAR-UNCC/RW-GCN.