 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADG-Pose: Automated Dataset Generation for Real-World Human Pose Estimation
Feb 01, 2022Recent advancements in computer vision have seen a rise in the prominence of applications using neural networks to understand human poses. However, while accuracy has been steadily increasing on State-of-the-Art datasets, these datasets often do not address the challenges seen in real-world applications. These challenges are dealing with people distant from the camera, people in crowds, and heavily occluded people. As a result, many real-world applications have trained on data that does not reflect the data present in deployment, leading to significant underperformance. This article presents ADG-Pose, a method for automatically generating datasets for real-world human pose estimation. These datasets can be customized to determine person distances, crowdedness, and occlusion distributions. Models trained with our method are able to perform in the presence of these challenges where those trained on other datasets fail. Using ADG-Pose, end-to-end accuracy for real-world skeleton-based action recognition sees a 20% increase on scenes with moderate distance and occlusion levels, and a 4X increase on distant scenes where other models failed to perform better than random.
Real-World Graph Convolution Networks (RW-GCNs) for Action Recognition in Smart Video Surveillance
Jan 15, 2022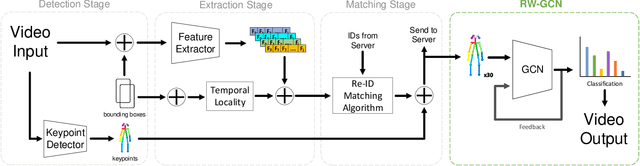
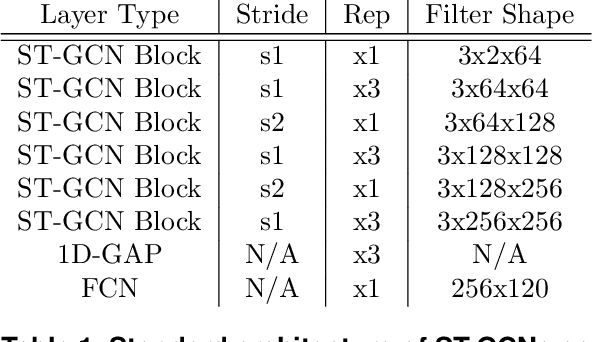

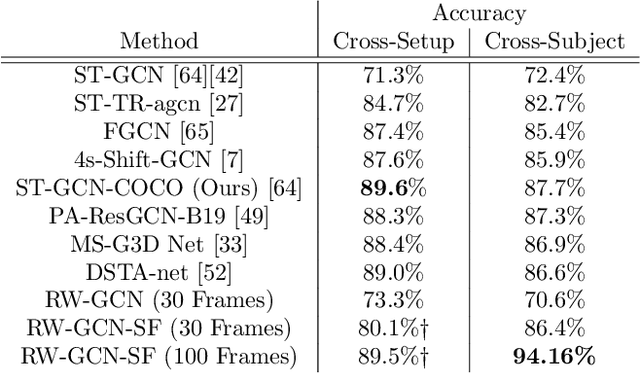
Action recognition is a key algorithmic part of emerging on-the-edge smart video surveillance and security systems. Skeleton-based action recognition is an attractive approach which, instead of using RGB pixel data, relies on human pose information to classify appropriate actions. However, existing algorithms often assume ideal conditions that are not representative of real-world limitations, such as noisy input, latency requirements, and edge resource constraints. To address the limitations of existing approaches, this paper presents Real-World Graph Convolution Networks (RW-GCNs), an architecture-level solution for meeting the domain constraints of Real World Skeleton-based Action Recognition. Inspired by the presence of feedback connections in the human visual cortex, RW-GCNs leverage attentive feedback augmentation on existing near state-of-the-art (SotA) Spatial-Temporal Graph Convolution Networks (ST-GCNs). The ST-GCNs' design choices are derived from information theory-centric principles to address both the spatial and temporal noise typically encountered in end-to-end real-time and on-the-edge smart video systems. Our results demonstrate RW-GCNs' ability to serve these applications by achieving a new SotA accuracy on the NTU-RGB-D-120 dataset at 94.1%, and achieving 32X less latency than baseline ST-GCN applications while still achieving 90.4% accuracy on the Northwestern UCLA dataset in the presence of spatial keypoint noise. RW-GCNs further show system scalability by running on the 10X cost effective NVIDIA Jetson Nano (as opposed to NVIDIA Xavier NX), while still maintaining a respectful range of throughput (15.6 to 5.5 Actions per Second) on the resource constrained device. The code is available here: https://github.com/TeCSAR-UNCC/RW-GCN.
Single Run Action Detector over Video Stream -- A Privacy Preserving Approach
Feb 05, 2021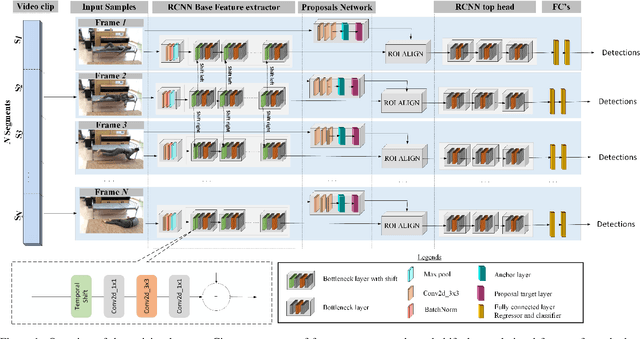
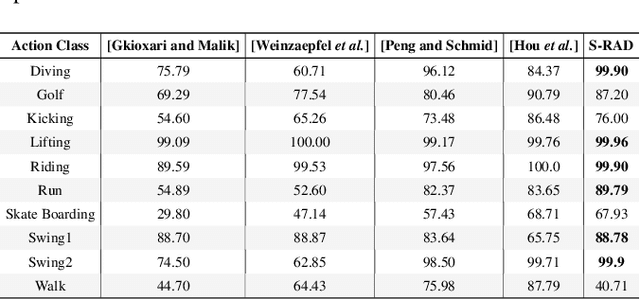
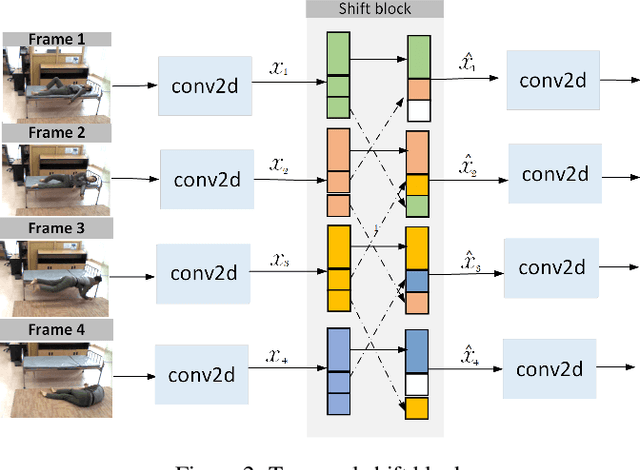
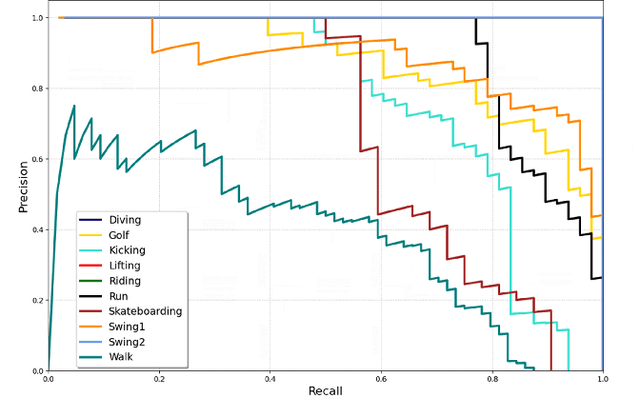
This paper takes initial strides at designing and evaluating a vision-based system for privacy ensured activity monitoring. The proposed technology utilizing Artificial Intelligence (AI)-empowered proactive systems offering continuous monitoring, behavioral analysis, and modeling of human activities. To this end, this paper presents Single Run Action Detector (S-RAD) which is a real-time privacy-preserving action detector that performs end-to-end action localization and classification. It is based on Faster-RCNN combined with temporal shift modeling and segment based sampling to capture the human actions. Results on UCF-Sports and UR Fall dataset present comparable accuracy to State-of-the-Art approaches with significantly lower model size and computation demand and the ability for real-time execution on edge embedded device (e.g. Nvidia Jetson Xavier).