 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks
Jan 08, 2026We introduce enhanced Constitutional Classifiers that deliver production-grade jailbreak robustness with dramatically reduced computational costs and refusal rates compared to previous-generation defenses. Our system combines several key insights. First, we develop exchange classifiers that evaluate model responses in their full conversational context, which addresses vulnerabilities in last-generation systems that examine outputs in isolation. Second, we implement a two-stage classifier cascade where lightweight classifiers screen all traffic and escalate only suspicious exchanges to more expensive classifiers. Third, we train efficient linear probe classifiers and ensemble them with external classifiers to simultaneously improve robustness and reduce computational costs. Together, these techniques yield a production-grade system achieving a 40x computational cost reduction compared to our baseline exchange classifier, while maintaining a 0.05% refusal rate on production traffic. Through extensive red-teaming comprising over 1,700 hours, we demonstrate strong protection against universal jailbreaks -- no attack on this system successfully elicited responses to all eight target queries comparable in detail to an undefended model. Our work establishes Constitutional Classifiers as practical and efficient safeguards for large language models.
Central Yup'ik and Machine Translation of Low-Resource Polysynthetic Languages
Sep 09, 2020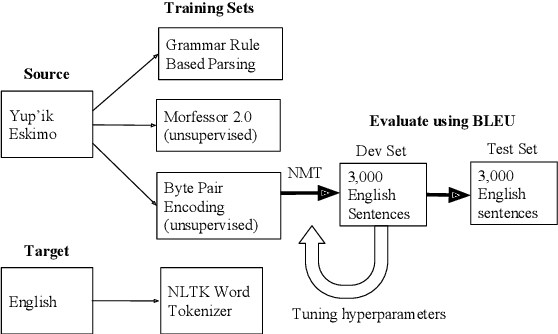
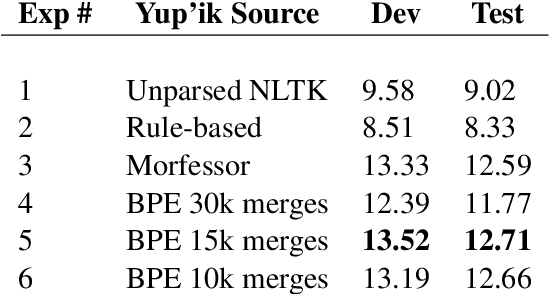
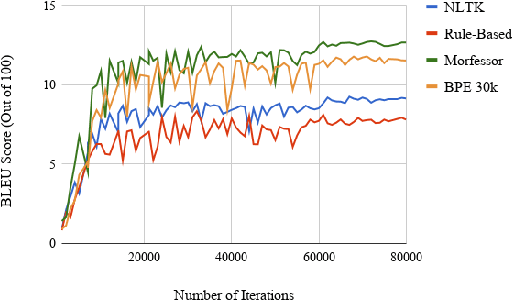
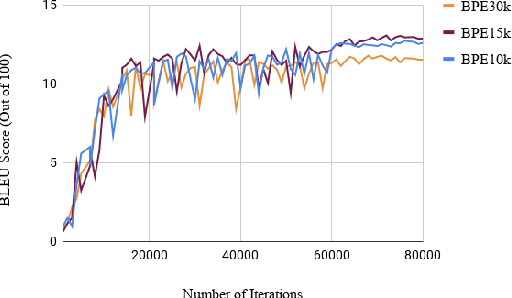
Machine translation tools do not yet exist for the Yup'ik language, a polysynthetic language spoken by around 8,000 people who live primarily in Southwest Alaska. We compiled a parallel text corpus for Yup'ik and English and developed a morphological parser for Yup'ik based on grammar rules. We trained a seq2seq neural machine translation model with attention to translate Yup'ik input into English. We then compared the influence of different tokenization methods, namely rule-based, unsupervised (byte pair encoding), and unsupervised morphological (Morfessor) parsing, on BLEU score accuracy for Yup'ik to English translation. We find that using tokenized input increases the translation accuracy compared to that of unparsed input. Although overall Morfessor did best with a vocabulary size of 30k, our first experiments show that BPE performed best with a reduced vocabulary size.