 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentral Yup'ik and Machine Translation of Low-Resource Polysynthetic Languages
Paper and Code
Sep 09, 2020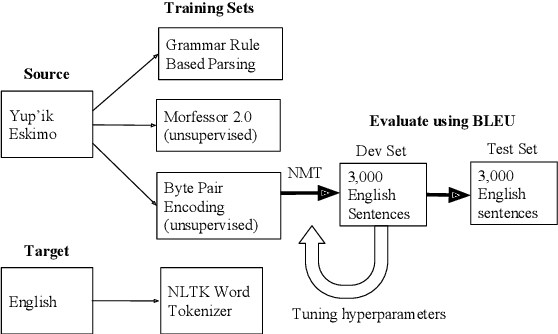
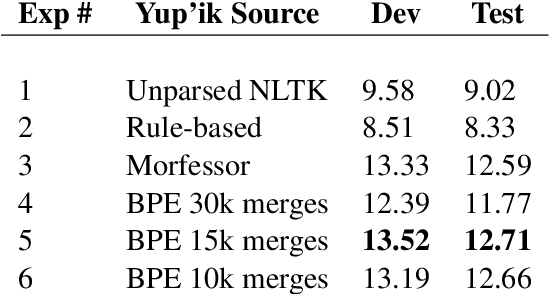
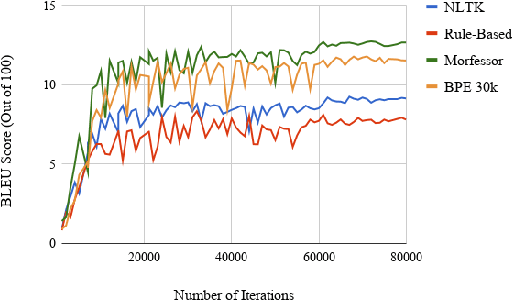
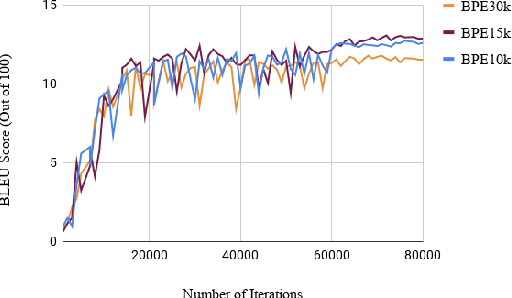
Machine translation tools do not yet exist for the Yup'ik language, a polysynthetic language spoken by around 8,000 people who live primarily in Southwest Alaska. We compiled a parallel text corpus for Yup'ik and English and developed a morphological parser for Yup'ik based on grammar rules. We trained a seq2seq neural machine translation model with attention to translate Yup'ik input into English. We then compared the influence of different tokenization methods, namely rule-based, unsupervised (byte pair encoding), and unsupervised morphological (Morfessor) parsing, on BLEU score accuracy for Yup'ik to English translation. We find that using tokenized input increases the translation accuracy compared to that of unparsed input. Although overall Morfessor did best with a vocabulary size of 30k, our first experiments show that BPE performed best with a reduced vocabulary size.