 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Resilience to Out-of-Distribution Visual Data via Input Optimization and Model Finetuning
Nov 29, 2022A major challenge in machine learning is resilience to out-of-distribution data, that is data that exists outside of the distribution of a model's training data. Training is often performed using limited, carefully curated datasets and so when a model is deployed there is often a significant distribution shift as edge cases and anomalies not included in the training data are encountered. To address this, we propose the Input Optimisation Network, an image preprocessing model that learns to optimise input data for a specific target vision model. In this work we investigate several out-of-distribution scenarios in the context of semantic segmentation for autonomous vehicles, comparing an Input Optimisation based solution to existing approaches of finetuning the target model with augmented training data and an adversarially trained preprocessing model. We demonstrate that our approach can enable performance on such data comparable to that of a finetuned model, and subsequently that a combined approach, whereby an input optimization network is optimised to target a finetuned model, delivers superior performance to either method in isolation. Finally, we propose a joint optimisation approach, in which input optimization network and target model are trained simultaneously, which we demonstrate achieves significant further performance gains, particularly in challenging edge-case scenarios. We also demonstrate that our architecture can be reduced to a relatively compact size without a significant performance impact, potentially facilitating real time embedded applications.
Efficient Neural Mapping for Localisation of Unmanned Ground Vehicles
Nov 09, 2022



Global localisation from visual data is a challenging problem applicable to many robotics domains. Prior works have shown that neural networks can be trained to map images of an environment to absolute camera pose within that environment, learning an implicit neural mapping in the process. In this work we evaluate the applicability of such an approach to real-world robotics scenarios, demonstrating that by constraining the problem to 2-dimensions and significantly increasing the quantity of training data, a compact model capable of real-time inference on embedded platforms can be used to achieve localisation accuracy of several centimetres. We deploy our trained model onboard a UGV platform, demonstrating its effectiveness in a waypoint navigation task. Along with this work we will release a novel localisation dataset comprising simulated and real environments, each with training samples numbering in the tens of thousands.
On Efficient Real-Time Semantic Segmentation: A Survey
Jun 17, 2022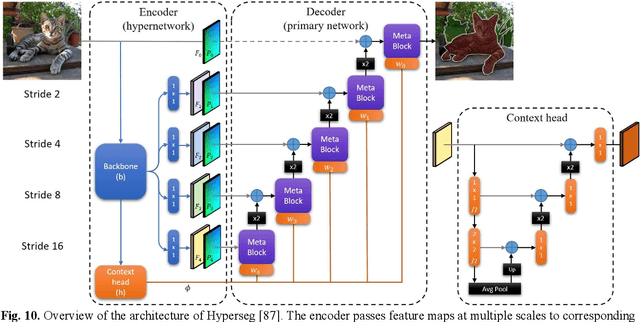
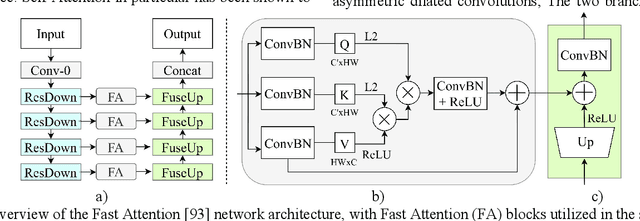
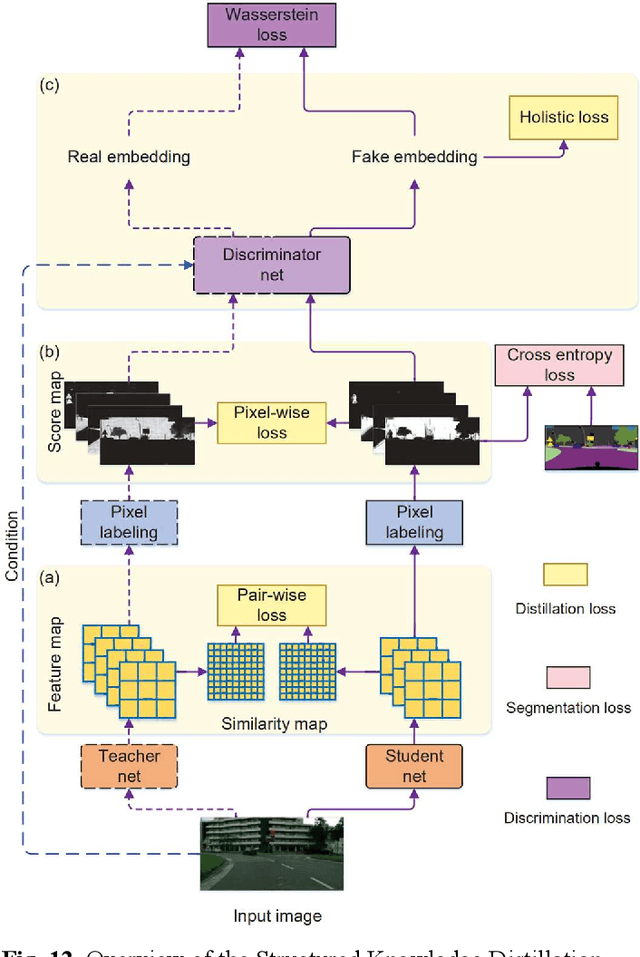
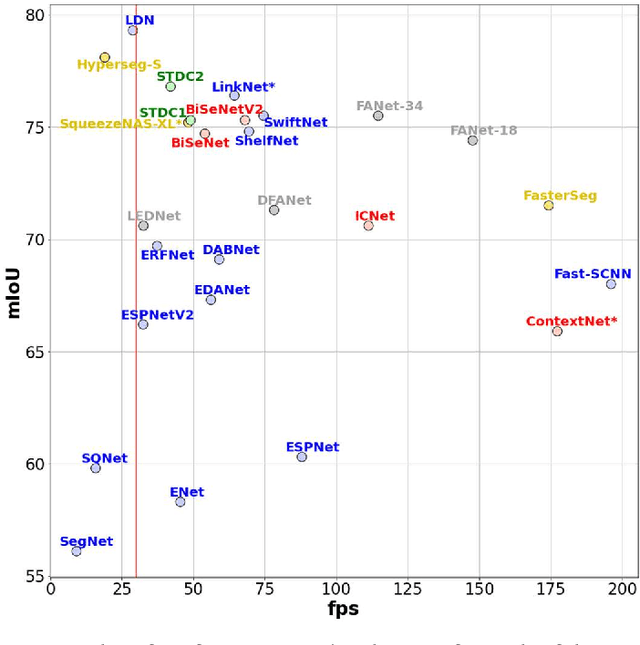
Semantic segmentation is the problem of assigning a class label to every pixel in an image, and is an important component of an autonomous vehicle vision stack for facilitating scene understanding and object detection. However, many of the top performing semantic segmentation models are extremely complex and cumbersome, and as such are not suited to deployment onboard autonomous vehicle platforms where computational resources are limited and low-latency operation is a vital requirement. In this survey, we take a thorough look at the works that aim to address this misalignment with more compact and efficient models capable of deployment on low-memory embedded systems while meeting the constraint of real-time inference. We discuss several of the most prominent works in the field, placing them within a taxonomy based on their major contributions, and finally we evaluate the inference speed of the discussed models under consistent hardware and software setups that represent a typical research environment with high-end GPU and a realistic deployed scenario using low-memory embedded GPU hardware. Our experimental results demonstrate that many works are capable of real-time performance on resource-constrained hardware, while illustrating the consistent trade-off between latency and accuracy.
Depth Not Needed - An Evaluation of RGB-D Feature Encodings for Off-Road Scene Understanding by Convolutional Neural Network
Jan 04, 2018
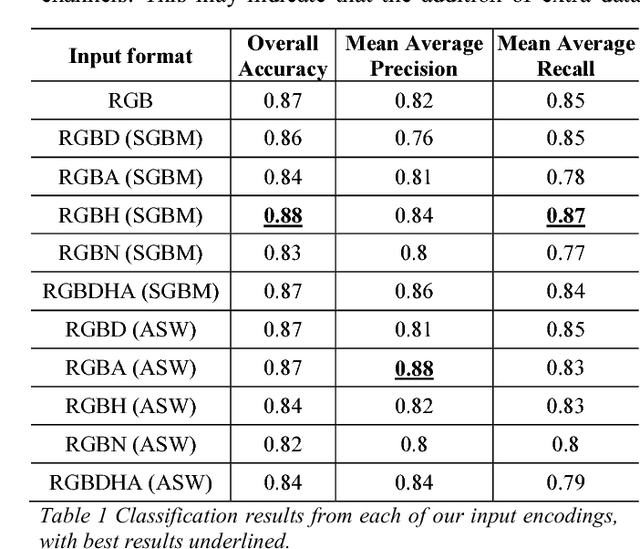

Scene understanding for autonomous vehicles is a challenging computer vision task, with recent advances in convolutional neural networks (CNNs) achieving results that notably surpass prior traditional feature driven approaches. However, limited work investigates the application of such methods either within the highly unstructured off-road environment or to RGBD input data. In this work, we take an existing CNN architecture designed to perform semantic segmentation of RGB images of urban road scenes, then adapt and retrain it to perform the same task with multichannel RGBD images obtained under a range of challenging off-road conditions. We compare two different stereo matching algorithms and five different methods of encoding depth information, including disparity, local normal orientation and HHA (horizontal disparity, height above ground plane, angle with gravity), to create a total of ten experimental variations of our dataset, each of which is used to train and test a CNN so that classification performance can be evaluated against a CNN trained using standard RGB input.