 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Not Needed - An Evaluation of RGB-D Feature Encodings for Off-Road Scene Understanding by Convolutional Neural Network
Paper and Code
Jan 04, 2018
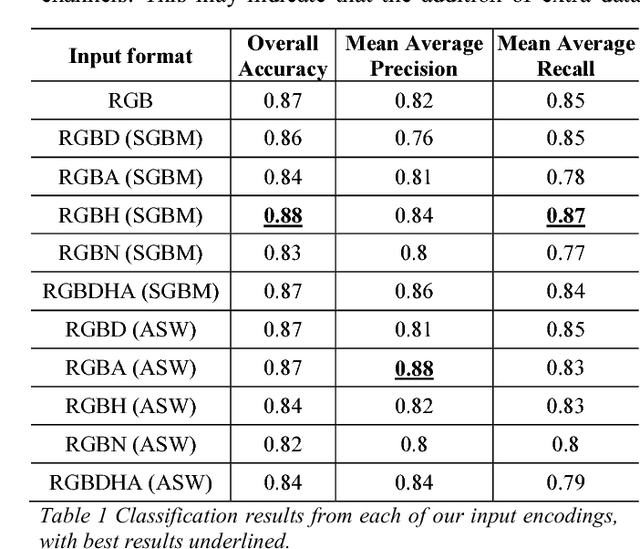

Scene understanding for autonomous vehicles is a challenging computer vision task, with recent advances in convolutional neural networks (CNNs) achieving results that notably surpass prior traditional feature driven approaches. However, limited work investigates the application of such methods either within the highly unstructured off-road environment or to RGBD input data. In this work, we take an existing CNN architecture designed to perform semantic segmentation of RGB images of urban road scenes, then adapt and retrain it to perform the same task with multichannel RGBD images obtained under a range of challenging off-road conditions. We compare two different stereo matching algorithms and five different methods of encoding depth information, including disparity, local normal orientation and HHA (horizontal disparity, height above ground plane, angle with gravity), to create a total of ten experimental variations of our dataset, each of which is used to train and test a CNN so that classification performance can be evaluated against a CNN trained using standard RGB input.