 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Measure the Intelligence of Large Language Models?
Jul 30, 2024
With the release of ChatGPT and other large language models (LLMs) the discussion about the intelligence, possibilities, and risks, of current and future models have seen large attention. This discussion included much debated scenarios about the imminent rise of so-called "super-human" AI, i.e., AI systems that are orders of magnitude smarter than humans. In the spirit of Alan Turing, there is no doubt that current state-of-the-art language models already pass his famous test. Moreover, current models outperform humans in several benchmark tests, so that publicly available LLMs have already become versatile companions that connect everyday life, industry and science. Despite their impressive capabilities, LLMs sometimes fail completely at tasks that are thought to be trivial for humans. In other cases, the trustworthiness of LLMs becomes much more elusive and difficult to evaluate. Taking the example of academia, language models are capable of writing convincing research articles on a given topic with only little input. Yet, the lack of trustworthiness in terms of factual consistency or the existence of persistent hallucinations in AI-generated text bodies has led to a range of restrictions for AI-based content in many scientific journals. In view of these observations, the question arises as to whether the same metrics that apply to human intelligence can also be applied to computational methods and has been discussed extensively. In fact, the choice of metrics has already been shown to dramatically influence assessments on potential intelligence emergence. Here, we argue that the intelligence of LLMs should not only be assessed by task-specific statistical metrics, but separately in terms of qualitative and quantitative measures.
German Text Embedding Clustering Benchmark
Jan 05, 2024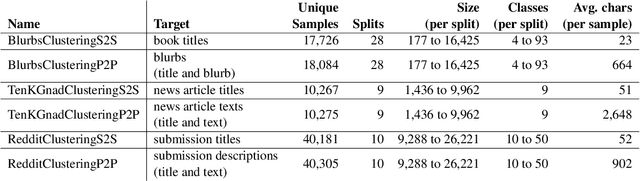
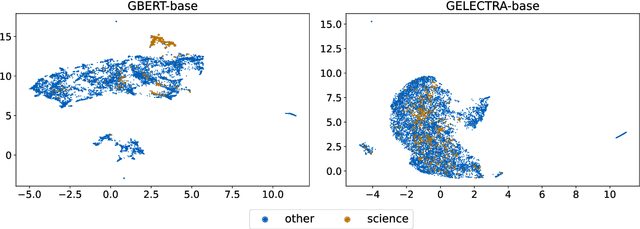
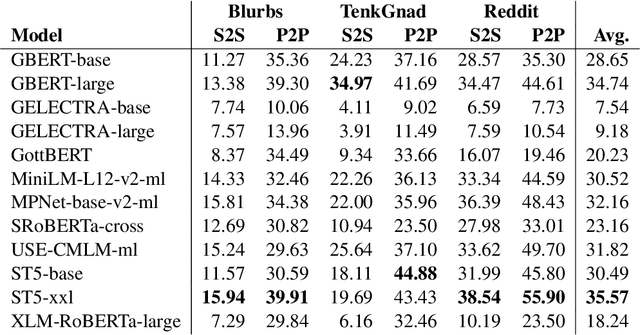
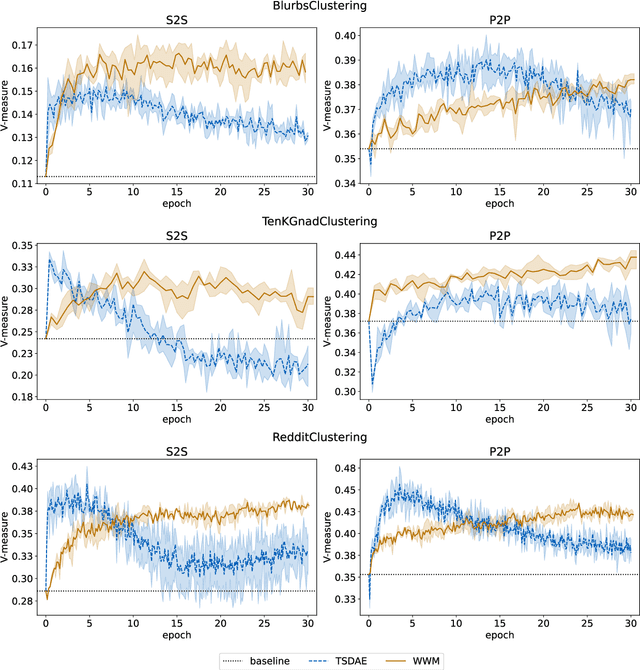
This work introduces a benchmark assessing the performance of clustering German text embeddings in different domains. This benchmark is driven by the increasing use of clustering neural text embeddings in tasks that require the grouping of texts (such as topic modeling) and the need for German resources in existing benchmarks. We provide an initial analysis for a range of pre-trained mono- and multilingual models evaluated on the outcome of different clustering algorithms. Results include strong performing mono- and multilingual models. Reducing the dimensions of embeddings can further improve clustering. Additionally, we conduct experiments with continued pre-training for German BERT models to estimate the benefits of this additional training. Our experiments suggest that significant performance improvements are possible for short text. All code and datasets are publicly available.
Will Artificial Intelligence supersede Earth System and Climate Models?
Jan 22, 2021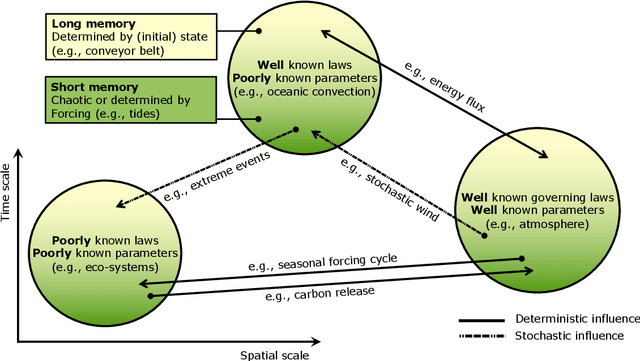
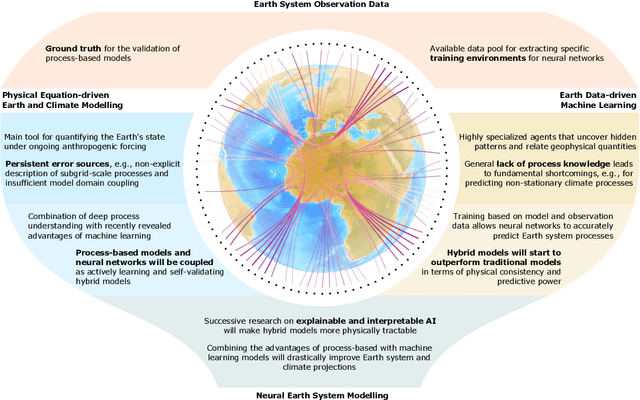
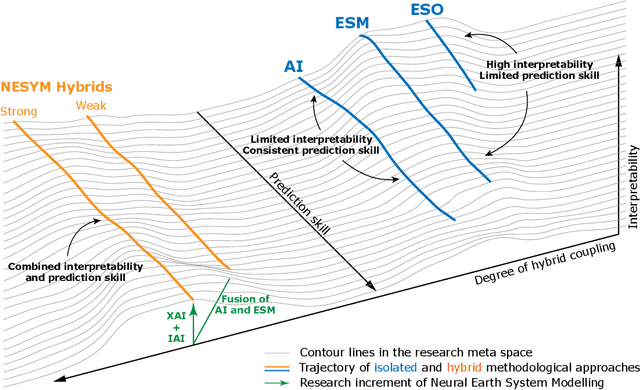
We outline a perspective of an entirely new research branch in Earth and climate sciences, where deep neural networks and Earth system models are dismantled as individual methodological approaches and reassembled as learning, self-validating, and interpretable Earth system model-network hybrids. Following this path, we coin the term "Neural Earth System Modelling" (NESYM) and highlight the necessity of a transdisciplinary discussion platform, bringing together Earth and climate scientists, big data analysts, and AI experts. We examine the concurrent potential and pitfalls of Neural Earth System Modelling and discuss the open question whether artificial intelligence will not only infuse Earth system modelling, but ultimately render them obsolete.