 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Measure the Intelligence of Large Language Models?
Jul 30, 2024
With the release of ChatGPT and other large language models (LLMs) the discussion about the intelligence, possibilities, and risks, of current and future models have seen large attention. This discussion included much debated scenarios about the imminent rise of so-called "super-human" AI, i.e., AI systems that are orders of magnitude smarter than humans. In the spirit of Alan Turing, there is no doubt that current state-of-the-art language models already pass his famous test. Moreover, current models outperform humans in several benchmark tests, so that publicly available LLMs have already become versatile companions that connect everyday life, industry and science. Despite their impressive capabilities, LLMs sometimes fail completely at tasks that are thought to be trivial for humans. In other cases, the trustworthiness of LLMs becomes much more elusive and difficult to evaluate. Taking the example of academia, language models are capable of writing convincing research articles on a given topic with only little input. Yet, the lack of trustworthiness in terms of factual consistency or the existence of persistent hallucinations in AI-generated text bodies has led to a range of restrictions for AI-based content in many scientific journals. In view of these observations, the question arises as to whether the same metrics that apply to human intelligence can also be applied to computational methods and has been discussed extensively. In fact, the choice of metrics has already been shown to dramatically influence assessments on potential intelligence emergence. Here, we argue that the intelligence of LLMs should not only be assessed by task-specific statistical metrics, but separately in terms of qualitative and quantitative measures.
GANetic Loss for Generative Adversarial Networks with a Focus on Medical Applications
Jun 07, 2024Generative adversarial networks (GANs) are machine learning models that are used to estimate the underlying statistical structure of a given dataset and as a result can be used for a variety of tasks such as image generation or anomaly detection. Despite their initial simplicity, designing an effective loss function for training GANs remains challenging, and various loss functions have been proposed aiming to improve the performance and stability of the generative models. In this study, loss function design for GANs is presented as an optimization problem solved using the genetic programming (GP) approach. Initial experiments were carried out using small Deep Convolutional GAN (DCGAN) model and the MNIST dataset, in order to search experimentally for an improved loss function. The functions found were evaluated on CIFAR10, with the best function, named GANetic loss, showing exceptionally better performance and stability compared to the losses commonly used for GAN training. To further evalute its general applicability on more challenging problems, GANetic loss was applied for two medical applications: image generation and anomaly detection. Experiments were performed with histopathological, gastrointestinal or glaucoma images to evaluate the GANetic loss in medical image generation, resulting in improved image quality compared to the baseline models. The GANetic Loss used for polyp and glaucoma images showed a strong improvement in the detection of anomalies. In summary, the GANetic loss function was evaluated on multiple datasets and applications where it consistently outperforms alternative loss functions. Moreover, GANetic loss leads to stable training and reproducible results, a known weak spot of GANs.
Next Generation Loss Function for Image Classification
Apr 19, 2024



Neural networks are trained by minimizing a loss function that defines the discrepancy between the predicted model output and the target value. The selection of the loss function is crucial to achieve task-specific behaviour and highly influences the capability of the model. A variety of loss functions have been proposed for a wide range of tasks affecting training and model performance. For classification tasks, the cross entropy is the de-facto standard and usually the first choice. Here, we try to experimentally challenge the well-known loss functions, including cross entropy (CE) loss, by utilizing the genetic programming (GP) approach, a population-based evolutionary algorithm. GP constructs loss functions from a set of operators and leaf nodes and these functions are repeatedly recombined and mutated to find an optimal structure. Experiments were carried out on different small-sized datasets CIFAR-10, CIFAR-100 and Fashion-MNIST using an Inception model. The 5 best functions found were evaluated for different model architectures on a set of standard datasets ranging from 2 to 102 classes and very different sizes. One function, denoted as Next Generation Loss (NGL), clearly stood out showing same or better performance for all tested datasets compared to CE. To evaluate the NGL function on a large-scale dataset, we tested its performance on the Imagenet-1k dataset where it showed improved top-1 accuracy compared to models trained with identical settings and other losses. Finally, the NGL was trained on a segmentation downstream task for Pascal VOC 2012 and COCO-Stuff164k datasets improving the underlying model performance.
Parameter-Free Average Attention Improves Convolutional Neural Network Performance (Almost) Free of Charge
Oct 14, 2022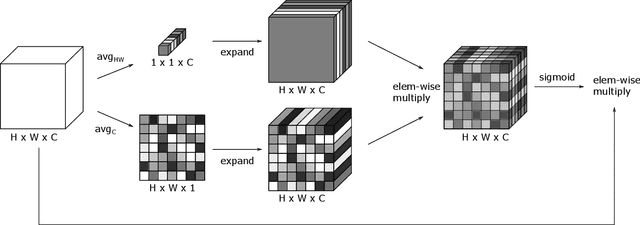

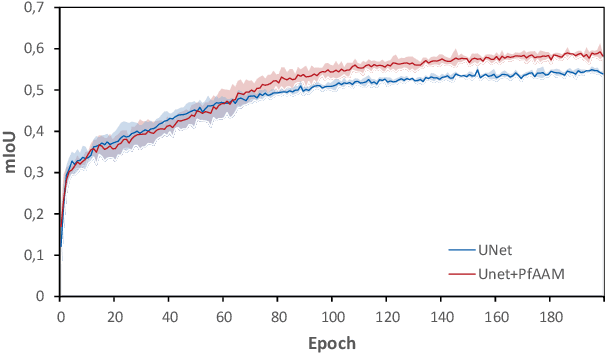
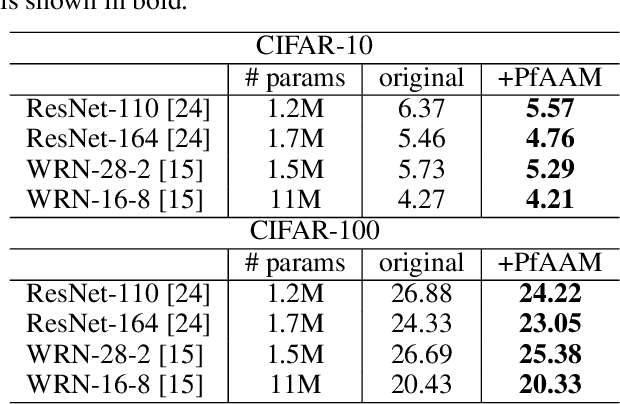
Visual perception is driven by the focus on relevant aspects in the surrounding world. To transfer this observation to the digital information processing of computers, attention mechanisms have been introduced to highlight salient image regions. Here, we introduce a parameter-free attention mechanism called PfAAM, that is a simple yet effective module. It can be plugged into various convolutional neural network architectures with a little computational overhead and without affecting model size. PfAAM was tested on multiple architectures for classification and segmentic segmentation leading to improved model performance for all tested cases. This demonstrates its wide applicability as a general easy-to-use module for computer vision tasks. The implementation of PfAAM can be found on https://github.com/nkoerb/pfaam.