 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Terrorist Attacks in the United States using Localized News Data
Jan 14, 2022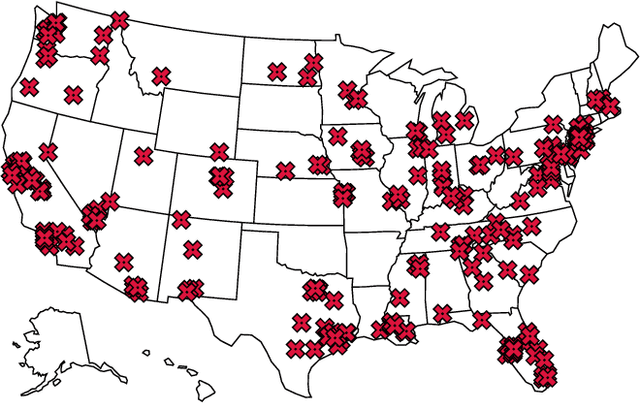
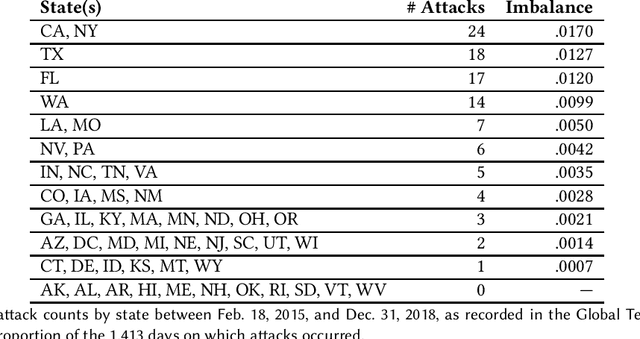

Terrorism is a major problem worldwide, causing thousands of fatalities and billions of dollars in damage every year. Toward the end of better understanding and mitigating these attacks, we present a set of machine learning models that learn from localized news data in order to predict whether a terrorist attack will occur on a given calendar date and in a given state. The best model--a Random Forest that learns from a novel variable-length moving average representation of the feature space--achieves area under the receiver operating characteristic scores $> .667$ on four of the five states that were impacted most by terrorism between 2015 and 2018. Our key findings include that modeling terrorism as a set of independent events, rather than as a continuous process, is a fruitful approach--especially when the events are sparse and dissimilar. Additionally, our results highlight the need for localized models that account for differences between locations. From a machine learning perspective, we found that the Random Forest model outperformed several deep models on our multimodal, noisy, and imbalanced data set, thus demonstrating the efficacy of our novel feature representation method in such a context. We also show that its predictions are relatively robust to time gaps between attacks and observed characteristics of the attacks. Finally, we analyze factors that limit model performance, which include a noisy feature space and small amount of available data. These contributions provide an important foundation for the use of machine learning in efforts against terrorism in the United States and beyond.
A data-driven approach to sampling matrix selection for compressive sensing
Jun 20, 2019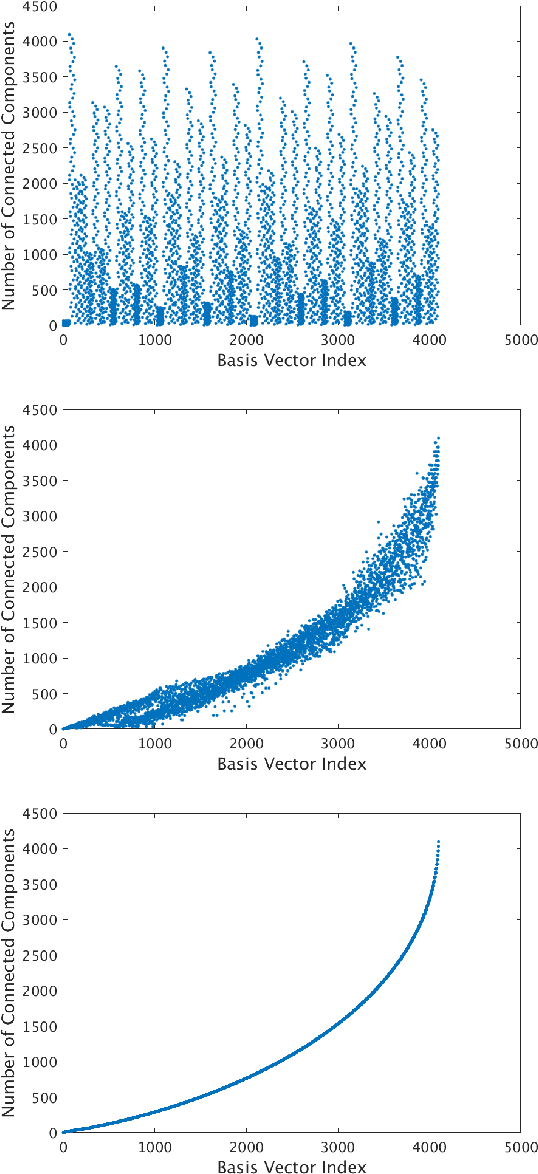
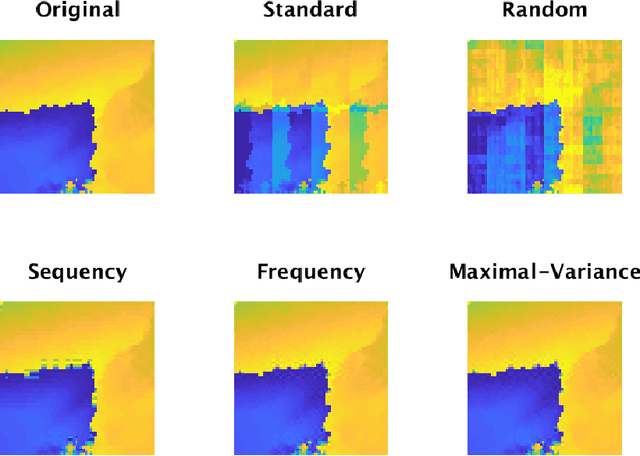
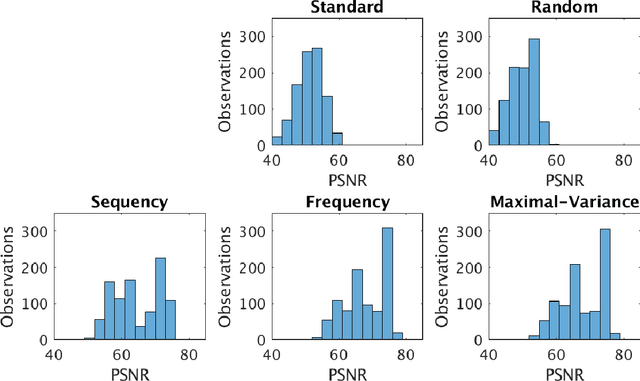
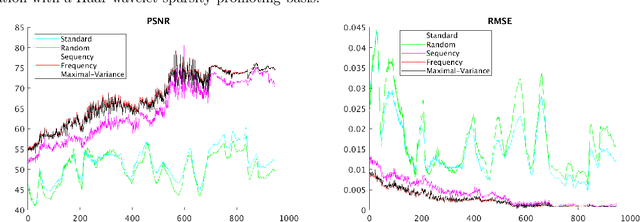
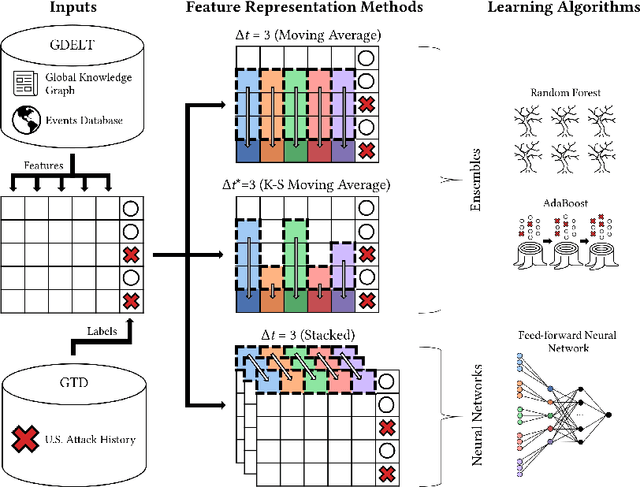
Sampling is a fundamental aspect of any implementation of compressive sensing. Typically, the choice of sampling method is guided by the reconstruction basis. However, this approach can be problematic with respect to certain hardware constraints and is not responsive to domain-specific context. We propose a method for defining an order for a sampling basis that is optimal with respect to capturing variance in data, thus allowing for meaningful sensing at any desired level of compression. We focus on the Walsh-Hadamard sampling basis for its relevance to hardware constraints, but our approach applies to any sampling basis of interest. We illustrate the effectiveness of our method on the Physical Sciences Inc. Fabry-P\'{e}rot interferometer sensor multispectral dataset, the Johns Hopkins Applied Physics Lab FTIR-based longwave infrared sensor hyperspectral dataset, and a Colorado State University Swiss Ranger depth image dataset. The spectral datasets consist of simulant experiments, including releases of chemicals such as GAA and SF6. We combine our sampling and reconstruction with the adaptive coherence estimator (ACE) and bulk coherence for chemical detection and we incorporate an algorithmic threshold for ACE values to determine the presence or absence of a chemical. We compare results across sampling methods in this context. We have successful chemical detection at a compression rate of 90%. For all three datasets, we compare our sampling approach to standard orderings of sampling basis such as random, sequency, and an analog of sequency that we term `frequency.' In one instance, the peak signal to noise ratio was improved by over 30% across a test set of depth images.