 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Outcome-driven Higher-order Dependencies in Graphs of Disease Trajectories
Dec 23, 2023



The widespread application of machine learning techniques to biomedical data has produced many new insights into disease progression and improving clinical care. Inspired by the flexibility and interpretability of graphs (networks), as well as the potency of sequence models like transformers and higher-order networks (HONs), we propose a method that identifies combinations of risk factors for a given outcome and accurately encodes these higher-order relationships in a graph. Using historical data from 913,475 type 2 diabetes (T2D) patients, we found that, compared to other approaches, the proposed networks encode significantly more information about the progression of T2D toward a variety of outcomes. We additionally demonstrate how structural information from the proposed graph can be used to augment the performance of transformer-based models on predictive tasks, especially when the data are noisy. By increasing the order, or memory, of the graph, we show how the proposed method illuminates key risk factors while successfully ignoring noisy elements, which facilitates analysis that is simultaneously accurate and interpretable.
Deep Ensembles for Graphs with Higher-order Dependencies
May 27, 2022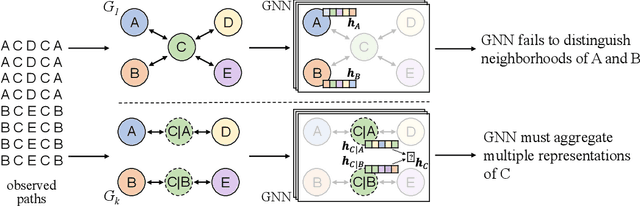

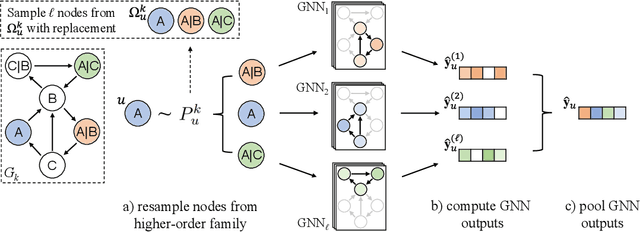
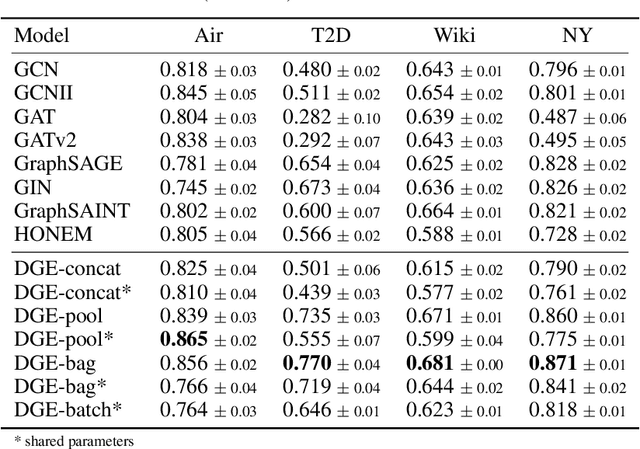
Graph neural networks (GNNs) continue to achieve state-of-the-art performance on many graph learning tasks, but rely on the assumption that a given graph is a sufficient approximation of the true neighborhood structure. In the presence of higher-order sequential dependencies, we show that the tendency of traditional graph representations to underfit each node's neighborhood causes existing GNNs to generalize poorly. To address this, we propose a novel Deep Graph Ensemble (DGE), which captures neighborhood variance by training an ensemble of GNNs on different neighborhood subspaces of the same node within a higher-order network structure. We show that DGE consistently outperforms existing GNNs on semisupervised and supervised tasks on four real-world data sets with known higher-order dependencies, even under a similar parameter budget. We demonstrate that learning diverse and accurate base classifiers is central to DGE's success, and discuss the implications of these findings for future work on GNNs.
Predicting Terrorist Attacks in the United States using Localized News Data
Jan 14, 2022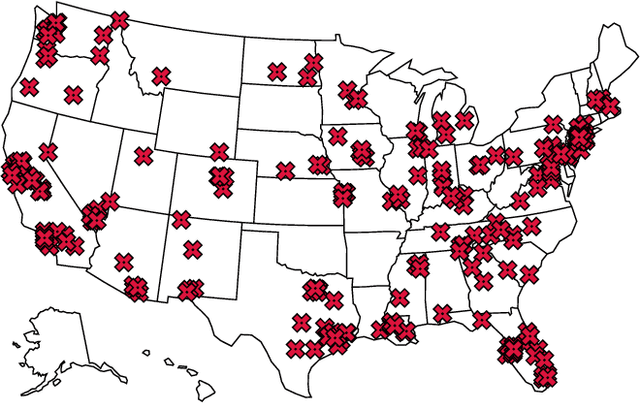
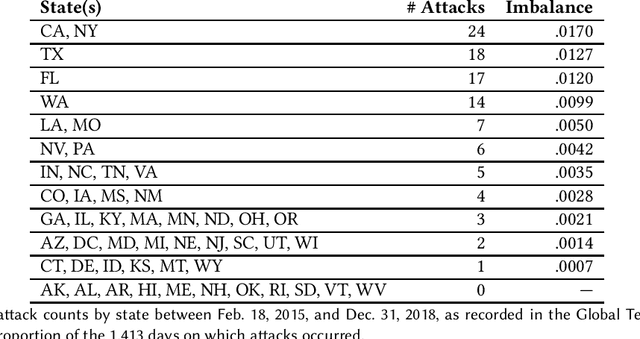
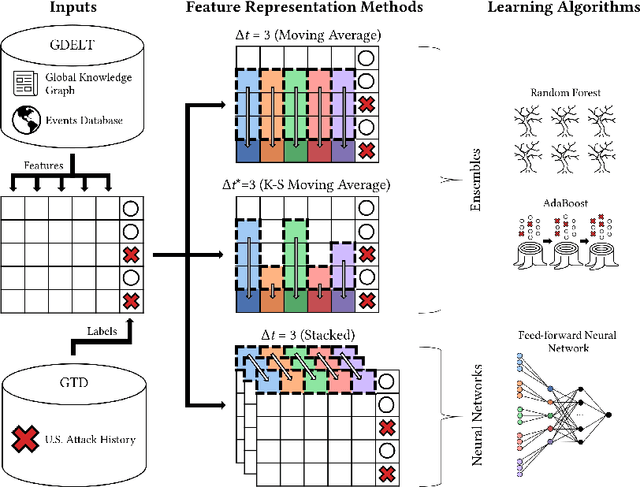

Terrorism is a major problem worldwide, causing thousands of fatalities and billions of dollars in damage every year. Toward the end of better understanding and mitigating these attacks, we present a set of machine learning models that learn from localized news data in order to predict whether a terrorist attack will occur on a given calendar date and in a given state. The best model--a Random Forest that learns from a novel variable-length moving average representation of the feature space--achieves area under the receiver operating characteristic scores $> .667$ on four of the five states that were impacted most by terrorism between 2015 and 2018. Our key findings include that modeling terrorism as a set of independent events, rather than as a continuous process, is a fruitful approach--especially when the events are sparse and dissimilar. Additionally, our results highlight the need for localized models that account for differences between locations. From a machine learning perspective, we found that the Random Forest model outperformed several deep models on our multimodal, noisy, and imbalanced data set, thus demonstrating the efficacy of our novel feature representation method in such a context. We also show that its predictions are relatively robust to time gaps between attacks and observed characteristics of the attacks. Finally, we analyze factors that limit model performance, which include a noisy feature space and small amount of available data. These contributions provide an important foundation for the use of machine learning in efforts against terrorism in the United States and beyond.