 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Approximate Uniform Facility Location via Graph Neural Networks
Feb 13, 2026There has been a growing interest in using neural networks, especially message-passing neural networks (MPNNs), to solve hard combinatorial optimization problems heuristically. However, existing learning-based approaches for hard combinatorial optimization tasks often rely on supervised training data, reinforcement learning, or gradient estimators, leading to significant computational overhead, unstable training, or a lack of provable performance guarantees. In contrast, classical approximation algorithms offer such performance guarantees under worst-case inputs but are non-differentiable and unable to adaptively exploit structural regularities in natural input distributions. We address this dichotomy with the fundamental example of Uniform Facility Location (UniFL), a variant of the combinatorial facility location problem with applications in clustering, data summarization, logistics, and supply chain design. We develop a fully differentiable MPNN model that embeds approximation-algorithmic principles while avoiding the need for solver supervision or discrete relaxations. Our approach admits provable approximation and size generalization guarantees to much larger instances than seen during training. Empirically, we show that our approach outperforms standard non-learned approximation algorithms in terms of solution quality, closing the gap with computationally intensive integer linear programming approaches. Overall, this work provides a step toward bridging learning-based methods and approximation algorithms for discrete optimization.
Constant Approximation for Normalized Modularity and Associations Clustering
Dec 29, 2022We study the problem of graph clustering under a broad class of objectives in which the quality of a cluster is defined based on the ratio between the number of edges in the cluster, and the total weight of vertices in the cluster. We show that our definition is closely related to popular clustering measures, namely normalized associations, which is a dual of the normalized cut objective, and normalized modularity. We give a linear time constant-approximate algorithm for our objective, which implies the first constant-factor approximation algorithms for normalized modularity and normalized associations.
Fast and Accurate $k$-means++ via Rejection Sampling
Dec 22, 2020



$k$-means++ \cite{arthur2007k} is a widely used clustering algorithm that is easy to implement, has nice theoretical guarantees and strong empirical performance. Despite its wide adoption, $k$-means++ sometimes suffers from being slow on large data-sets so a natural question has been to obtain more efficient algorithms with similar guarantees. In this paper, we present a near linear time algorithm for $k$-means++ seeding. Interestingly our algorithm obtains the same theoretical guarantees as $k$-means++ and significantly improves earlier results on fast $k$-means++ seeding. Moreover, we show empirically that our algorithm is significantly faster than $k$-means++ and obtains solutions of equivalent quality.
On Coresets for Logistic Regression
Sep 13, 2018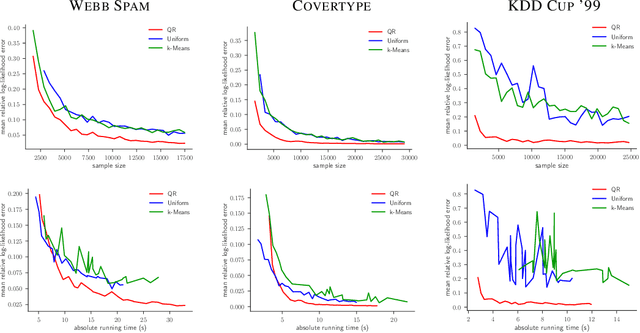
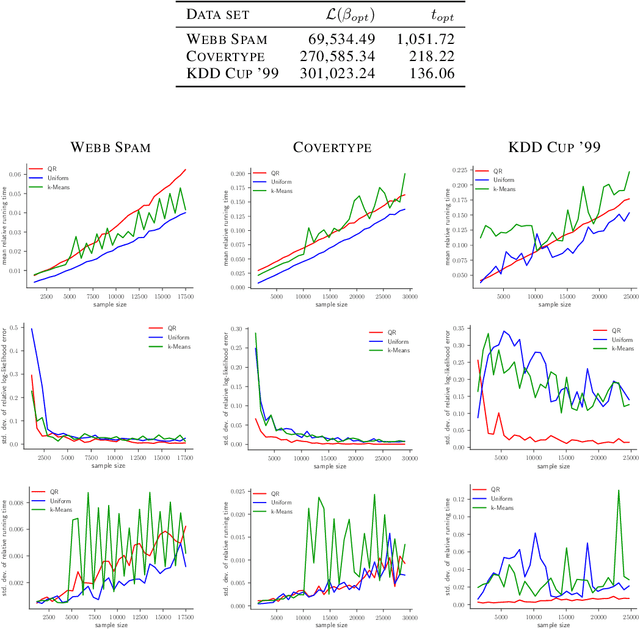
Coresets are one of the central methods to facilitate the analysis of large data sets. We continue a recent line of research applying the theory of coresets to logistic regression. First, we show a negative result, namely, that no strongly sublinear sized coresets exist for logistic regression. To deal with intractable worst-case instances we introduce a complexity measure $\mu(X)$, which quantifies the hardness of compressing a data set for logistic regression. $\mu(X)$ has an intuitive statistical interpretation that may be of independent interest. For data sets with bounded $\mu(X)$-complexity, we show that a novel sensitivity sampling scheme produces the first provably sublinear $(1\pm\varepsilon)$-coreset. We illustrate the performance of our method by comparing to uniform sampling as well as to state of the art methods in the area. The experiments are conducted on real world benchmark data for logistic regression.
Theoretical Analysis of the $k$-Means Algorithm - A Survey
Feb 26, 2016



The $k$-means algorithm is one of the most widely used clustering heuristics. Despite its simplicity, analyzing its running time and quality of approximation is surprisingly difficult and can lead to deep insights that can be used to improve the algorithm. In this paper we survey the recent results in this direction as well as several extension of the basic $k$-means method.
Analysis of Agglomerative Clustering
Mar 07, 2014



The diameter $k$-clustering problem is the problem of partitioning a finite subset of $\mathbb{R}^d$ into $k$ subsets called clusters such that the maximum diameter of the clusters is minimized. One early clustering algorithm that computes a hierarchy of approximate solutions to this problem (for all values of $k$) is the agglomerative clustering algorithm with the complete linkage strategy. For decades, this algorithm has been widely used by practitioners. However, it is not well studied theoretically. In this paper, we analyze the agglomerative complete linkage clustering algorithm. Assuming that the dimension $d$ is a constant, we show that for any $k$ the solution computed by this algorithm is an $O(\log k)$-approximation to the diameter $k$-clustering problem. Our analysis does not only hold for the Euclidean distance but for any metric that is based on a norm. Furthermore, we analyze the closely related $k$-center and discrete $k$-center problem. For the corresponding agglomerative algorithms, we deduce an approximation factor of $O(\log k)$ as well.
* A preliminary version of this article appeared in Proceedings of the 28th International Symposium on Theoretical Aspects of Computer Science (STACS '11), March 2011, pp. 308-319. This article also appeared in Algorithmica. The final publication is available at http://link.springer.com/article/10.1007/s00453-012-9717-4