 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRI Scan Synthesis Methods based on Clustering and Pix2Pix
Dec 08, 2023We consider a missing data problem in the context of automatic segmentation methods for Magnetic Resonance Imaging (MRI) brain scans. Usually, automated MRI scan segmentation is based on multiple scans (e.g., T1-weighted, T2-weighted, T1CE, FLAIR). However, quite often a scan is blurry, missing or otherwise unusable. We investigate the question whether a missing scan can be synthesized. We exemplify that this is in principle possible by synthesizing a T2-weighted scan from a given T1-weighted scan. Our first aim is to compute a picture that resembles the missing scan closely, measured by average mean squared error (MSE). We develop/use several methods for this, including a random baseline approach, a clustering-based method and pixel-to-pixel translation method by (Pix2Pix) which is based on conditional GANs. The lowest MSE is achieved by our clustering-based method. Our second aim is to compare the methods with respect to the affect that using the synthesized scan has on the segmentation process. For this, we use a DeepMedic model trained with the four input scan modalities named above. We replace the T2-weighted scan by the synthesized picture and evaluate the segmentations with respect to the tumor identification, using Dice scores as numerical evaluation. The evaluation shows that the segmentation works well with synthesized scans (in particular, with Pix2Pix methods) in many cases.
Approximating Fair $k$-Min-Sum-Radii in $\mathbb{R}^d$
Sep 02, 2023The $k$-center problem is a classical clustering problem in which one is asked to find a partitioning of a point set $P$ into $k$ clusters such that the maximum radius of any cluster is minimized. It is well-studied. But what if we add up the radii of the clusters instead of only considering the cluster with maximum radius? This natural variant is called the $k$-min-sum-radii problem. It has become the subject of more and more interest in recent years, inspiring the development of approximation algorithms for the $k$-min-sum-radii problem in its plain version as well as in constrained settings. We study the problem for Euclidean spaces $\mathbb{R}^d$ of arbitrary dimension but assume the number $k$ of clusters to be constant. In this case, a PTAS for the problem is known (see Bandyapadhyay, Lochet and Saurabh, SoCG, 2023). Our aim is to extend the knowledge base for $k$-min-sum-radii to the domain of fair clustering. We study several group fairness constraints, such as the one introduced by Chierichetti et al. (NeurIPS, 2017). In this model, input points have an additional attribute (e.g., colors such as red and blue), and clusters have to preserve the ratio between different attribute values (e.g., have the same fraction of red and blue points as the ground set). Different variants of this general idea have been studied in the literature. To the best of our knowledge, no approximative results for the fair $k$-min-sum-radii problem are known, despite the immense amount of work on the related fair $k$-center problem. We propose a PTAS for the fair $k$-min-sum-radii problem in Euclidean spaces of arbitrary dimension for the case of constant $k$. To the best of our knowledge, this is the first PTAS for the problem. It works for different notions of group fairness.
Coresets for constrained k-median and k-means clustering in low dimensional Euclidean space
Jun 14, 2021We study (Euclidean) $k$-median and $k$-means with constraints in the streaming model. There have been recent efforts to design unified algorithms to solve constrained $k$-means problems without using knowledge of the specific constraint at hand aside from mild assumptions like the polynomial computability of feasibility under the constraint (compute if a clustering satisfies the constraint) or the presence of an efficient assignment oracle (given a set of centers, produce an optimal assignment of points to the centers which satisfies the constraint). These algorithms have a running time exponential in $k$, but can be applied to a wide range of constraints. We demonstrate that a technique proposed in 2019 for solving a specific constrained streaming $k$-means problem, namely fair $k$-means clustering, actually implies streaming algorithms for all these constraints. These work for low dimensional Euclidean space. [Note that there are more algorithms for streaming fair $k$-means today, in particular they exist for high dimensional spaces now as well.]
Noisy, Greedy and Not So Greedy k-means++
Dec 02, 2019
The k-means++ algorithm due to Arthur and Vassilvitskii has become the most popular seeding method for Lloyd's algorithm. It samples the first center uniformly at random from the data set and the other $k-1$ centers iteratively according to $D^2$-sampling where the probability that a data point becomes the next center is proportional to its squared distance to the closest center chosen so far. k-means++ is known to achieve an approximation factor of $O(\log k)$ in expectation. Already in the original paper on k-means++, Arthur and Vassilvitskii suggested a variation called greedy k-means++ algorithm in which in each iteration multiple possible centers are sampled according to $D^2$-sampling and only the one that decreases the objective the most is chosen as a center for that iteration. It is stated as an open question whether this also leads to an $O(\log k)$-approximation (or even better). We show that this is not the case by presenting a family of instances on which greedy k-means++ yields only an $\Omega(\ell\cdot \log k)$-approximation in expectation where $\ell$ is the number of possible centers that are sampled in each iteration. We also study a variation, which we call noisy k-means++ algorithm. In this variation only one center is sampled in every iteration but not exactly by $D^2$-sampling anymore. Instead in each iteration an adversary is allowed to change the probabilities arising from $D^2$-sampling individually for each point by a factor between $1-\epsilon_1$ and $1+\epsilon_2$ for parameters $\epsilon_1 \in [0,1)$ and $\epsilon_2 \ge 0$. We prove that noisy k-means++ compute an $O(\log^2 k)$-approximation in expectation. We also discuss some applications of this result.
Analysis of Ward's Method
Jul 11, 2019

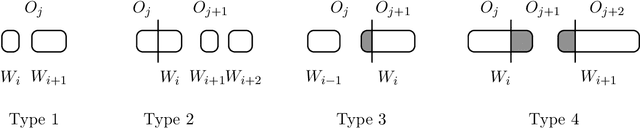
We study Ward's method for the hierarchical $k$-means problem. This popular greedy heuristic is based on the \emph{complete linkage} paradigm: Starting with all data points as singleton clusters, it successively merges two clusters to form a clustering with one cluster less. The pair of clusters is chosen to (locally) minimize the $k$-means cost of the clustering in the next step. Complete linkage algorithms are very popular for hierarchical clustering problems, yet their theoretical properties have been studied relatively little. For the Euclidean $k$-center problem, Ackermann et al. show that the $k$-clustering in the hierarchy computed by complete linkage has a worst-case approximation ratio of $\Theta(\log k)$. If the data lies in $\mathbb{R}^d$ for constant dimension $d$, the guarantee improves to $\mathcal{O}(1)$, but the $\mathcal{O}$-notation hides a linear dependence on $d$. Complete linkage for $k$-median or $k$-means has not been analyzed so far. In this paper, we show that Ward's method computes a $2$-approximation with respect to the $k$-means objective function if the optimal $k$-clustering is well separated. If additionally the optimal clustering also satisfies a balance condition, then Ward's method fully recovers the optimum solution. These results hold in arbitrary dimension. We accompany our positive results with a lower bound of $\Omega((3/2)^d)$ for data sets in $\mathbb{R}^d$ that holds if no separation is guaranteed, and with lower bounds when the guaranteed separation is not sufficiently strong. Finally, we show that Ward produces an $\mathcal{O}(1)$-approximative clustering for one-dimensional data sets.
Theoretical Analysis of the $k$-Means Algorithm - A Survey
Feb 26, 2016



The $k$-means algorithm is one of the most widely used clustering heuristics. Despite its simplicity, analyzing its running time and quality of approximation is surprisingly difficult and can lead to deep insights that can be used to improve the algorithm. In this paper we survey the recent results in this direction as well as several extension of the basic $k$-means method.