 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Being Difficult: Combining Human and AI Strengths to Find Adversarial Instances for Heuristics
Jan 23, 2026We demonstrate the power of human-LLM collaboration in tackling open problems in theoretical computer science. Focusing on combinatorial optimization, we refine outputs from the FunSearch algorithm [Romera-Paredes et al., Nature 2023] to derive state-of-the-art lower bounds for standard heuristics. Specifically, we target the generation of adversarial instances where these heuristics perform poorly. By iterating on FunSearch's outputs, we identify improved constructions for hierarchical $k$-median clustering, bin packing, the knapsack problem, and a generalization of Lovász's gasoline problem - some of these have not seen much improvement for over a decade, despite intermittent attention. These results illustrate how expert oversight can effectively extrapolate algorithmic insights from LLM-based evolutionary methods to break long-standing barriers. Our findings demonstrate that while LLMs provide critical initial patterns, human expertise is essential for transforming these patterns into mathematically rigorous and insightful constructions. This work highlights that LLMs are a strong collaborative tool in mathematics and computer science research.
Noisy, Greedy and Not So Greedy k-means++
Dec 02, 2019
The k-means++ algorithm due to Arthur and Vassilvitskii has become the most popular seeding method for Lloyd's algorithm. It samples the first center uniformly at random from the data set and the other $k-1$ centers iteratively according to $D^2$-sampling where the probability that a data point becomes the next center is proportional to its squared distance to the closest center chosen so far. k-means++ is known to achieve an approximation factor of $O(\log k)$ in expectation. Already in the original paper on k-means++, Arthur and Vassilvitskii suggested a variation called greedy k-means++ algorithm in which in each iteration multiple possible centers are sampled according to $D^2$-sampling and only the one that decreases the objective the most is chosen as a center for that iteration. It is stated as an open question whether this also leads to an $O(\log k)$-approximation (or even better). We show that this is not the case by presenting a family of instances on which greedy k-means++ yields only an $\Omega(\ell\cdot \log k)$-approximation in expectation where $\ell$ is the number of possible centers that are sampled in each iteration. We also study a variation, which we call noisy k-means++ algorithm. In this variation only one center is sampled in every iteration but not exactly by $D^2$-sampling anymore. Instead in each iteration an adversary is allowed to change the probabilities arising from $D^2$-sampling individually for each point by a factor between $1-\epsilon_1$ and $1+\epsilon_2$ for parameters $\epsilon_1 \in [0,1)$ and $\epsilon_2 \ge 0$. We prove that noisy k-means++ compute an $O(\log^2 k)$-approximation in expectation. We also discuss some applications of this result.
Analysis of Ward's Method
Jul 11, 2019

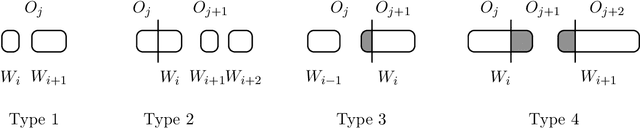
We study Ward's method for the hierarchical $k$-means problem. This popular greedy heuristic is based on the \emph{complete linkage} paradigm: Starting with all data points as singleton clusters, it successively merges two clusters to form a clustering with one cluster less. The pair of clusters is chosen to (locally) minimize the $k$-means cost of the clustering in the next step. Complete linkage algorithms are very popular for hierarchical clustering problems, yet their theoretical properties have been studied relatively little. For the Euclidean $k$-center problem, Ackermann et al. show that the $k$-clustering in the hierarchy computed by complete linkage has a worst-case approximation ratio of $\Theta(\log k)$. If the data lies in $\mathbb{R}^d$ for constant dimension $d$, the guarantee improves to $\mathcal{O}(1)$, but the $\mathcal{O}$-notation hides a linear dependence on $d$. Complete linkage for $k$-median or $k$-means has not been analyzed so far. In this paper, we show that Ward's method computes a $2$-approximation with respect to the $k$-means objective function if the optimal $k$-clustering is well separated. If additionally the optimal clustering also satisfies a balance condition, then Ward's method fully recovers the optimum solution. These results hold in arbitrary dimension. We accompany our positive results with a lower bound of $\Omega((3/2)^d)$ for data sets in $\mathbb{R}^d$ that holds if no separation is guaranteed, and with lower bounds when the guaranteed separation is not sufficiently strong. Finally, we show that Ward produces an $\mathcal{O}(1)$-approximative clustering for one-dimensional data sets.