 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity Curve Maximization: Attacking Robust Aggregators in Distributed Learning
Dec 23, 2024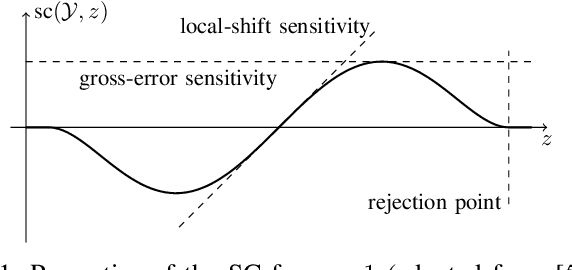
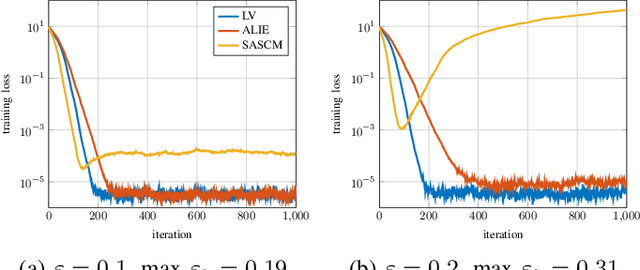
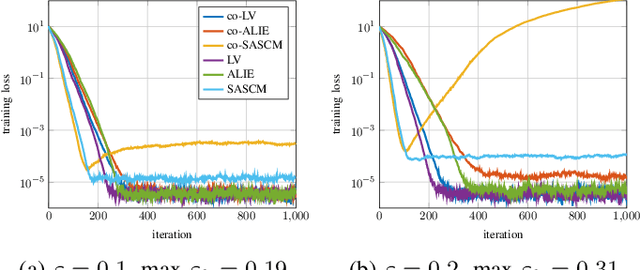
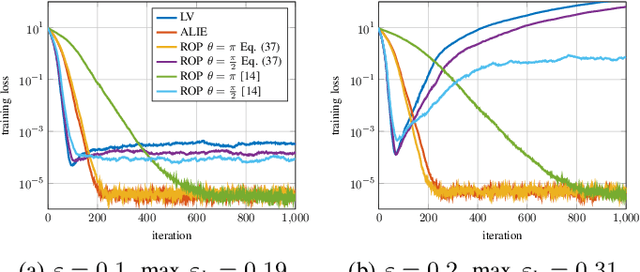
In distributed learning agents aim at collaboratively solving a global learning problem. It becomes more and more likely that individual agents are malicious or faulty with an increasing size of the network. This leads to a degeneration or complete breakdown of the learning process. Classical aggregation schemes are prone to breakdown at small contamination rates, therefore robust aggregation schemes are sought for. While robust aggregation schemes can generally tolerate larger contamination rates, many have been shown to be susceptible to carefully crafted malicious attacks. In this work, we show how the sensitivity curve (SC), a classical tool from robust statistics, can be used to systematically derive optimal attack patterns against arbitrary robust aggregators, in most cases rendering them ineffective. We show the effectiveness of the proposed attack in multiple simulations.
Emergency Response Person Localization and Vital Sign Estimation Using a Semi-Autonomous Robot Mounted SFCW Radar
May 25, 2023



The large number and scale of natural and man-made disasters have led to an urgent demand for technologies that enhance the safety and efficiency of search and rescue teams. Semi-autonomous rescue robots are beneficial, especially when searching inaccessible terrains, or dangerous environments, such as collapsed infrastructures. For search and rescue missions in degraded visual conditions or non-line of sight scenarios, radar-based approaches may contribute to acquire valuable, and otherwise unavailable information. This article presents a complete signal processing chain for radar-based multi-person detection, 2D-MUSIC localization and breathing frequency estimation. The proposed method shows promising results on a challenging emergency response dataset that we collected using a semi-autonomous robot equipped with a commercially available through-wall radar system. The dataset is composed of 62 scenarios of various difficulty levels with up to five persons captured in different postures, angles and ranges including wooden and stone obstacles that block the radar line of sight. Ground truth data for reference locations, respiration, electrocardiogram, and acceleration signals are included. The full emergency response benchmark data set as well as all codes to reproduce our results, are publicly available at https://doi.org/10.21227/4bzd-jm32.
Attacks on Robust Distributed Learning Schemes via Sensitivity Curve Maximization
Apr 27, 2023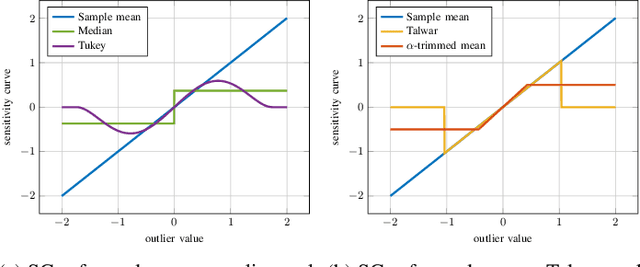
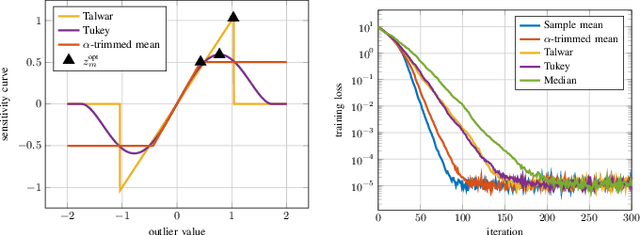
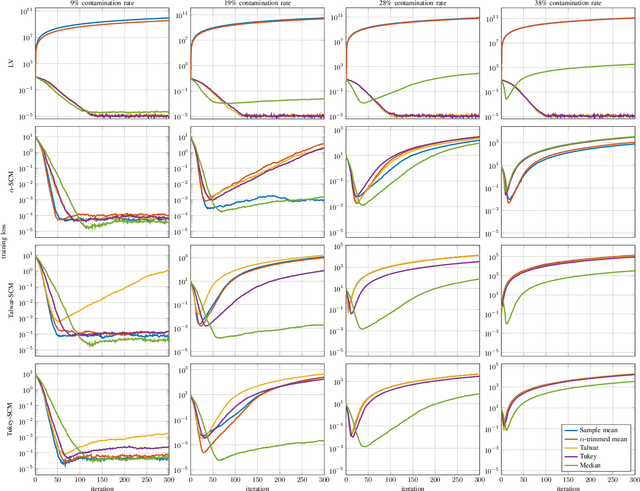
Distributed learning paradigms, such as federated or decentralized learning, allow a collection of agents to solve global learning and optimization problems through limited local interactions. Most such strategies rely on a mixture of local adaptation and aggregation steps, either among peers or at a central fusion center. Classically, aggregation in distributed learning is based on averaging, which is statistically efficient, but susceptible to attacks by even a small number of malicious agents. This observation has motivated a number of recent works, which develop robust aggregation schemes by employing robust variations of the mean. We present a new attack based on sensitivity curve maximization (SCM), and demonstrate that it is able to disrupt existing robust aggregation schemes by injecting small, but effective perturbations.
Real Elliptically Skewed Distributions and Their Application to Robust Cluster Analysis
Jun 30, 2020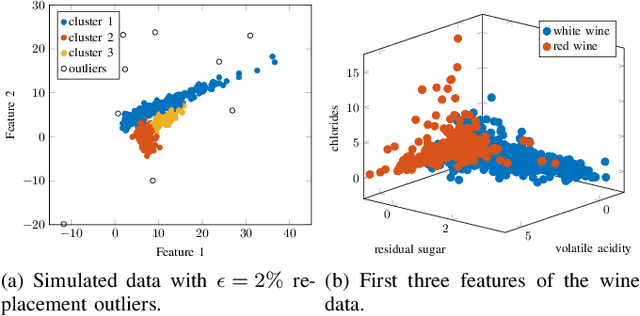
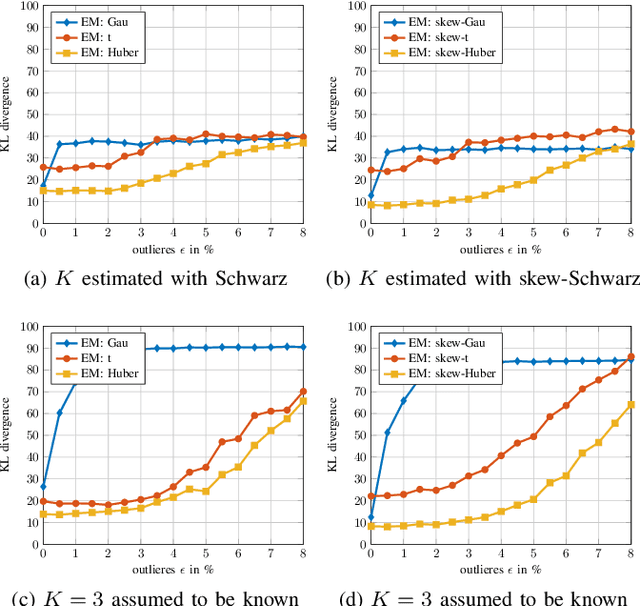
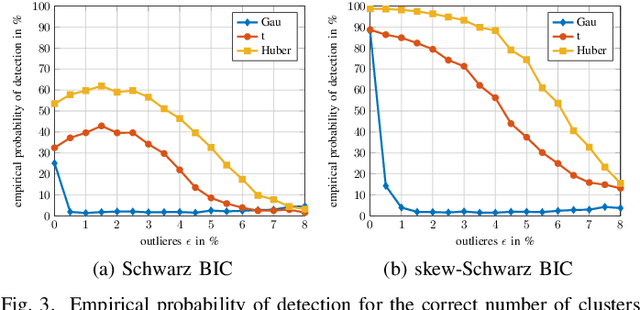
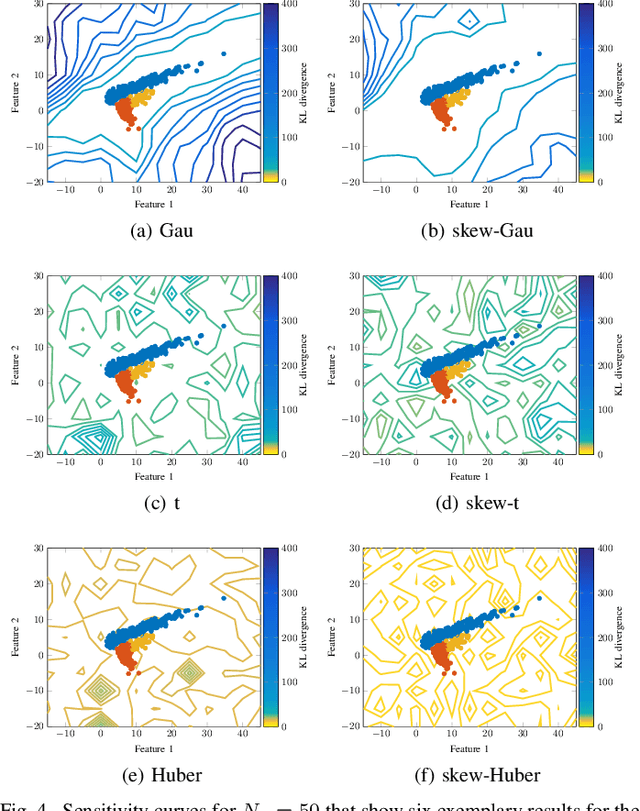
This article proposes a new class of Real Elliptically Skewed (RESK) distributions and associated clustering algorithms that allow for integrating robustness and skewness into a single unified cluster analysis framework. Non-symmetrically distributed and heavy-tailed data clusters have been reported in a variety of real-world applications. Robustness is essential because a few outlying observations can severely obscure the cluster structure. The RESK distributions are a generalization of the Real Elliptically Symmetric (RES) distributions. To estimate the cluster parameters and memberships, we derive an expectation maximization (EM) algorithm for arbitrary RESK distributions. Special attention is given to a new robust skew-Huber M-estimator, which is also the maximum likelihood estimator (MLE) for the skew-Huber distribution that belongs to the RESK class. Numerical experiments on simulated and real-world data confirm the usefulness of the proposed methods for skewed and heavy-tailed data sets.
Robust M-Estimation Based Bayesian Cluster Enumeration for Real Elliptically Symmetric Distributions
May 04, 2020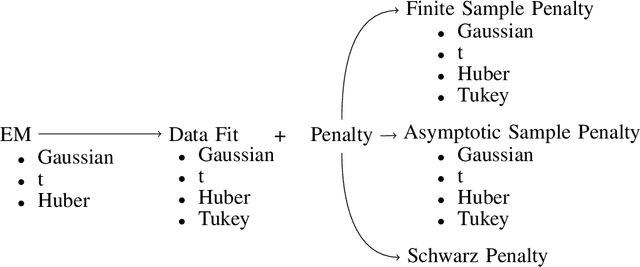
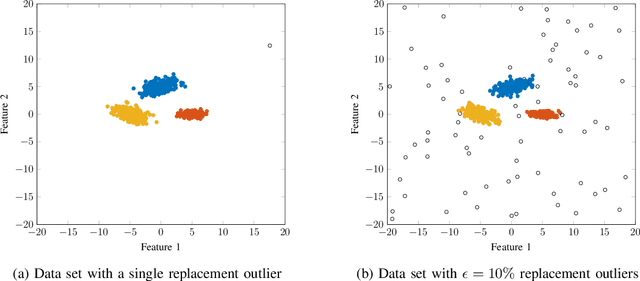
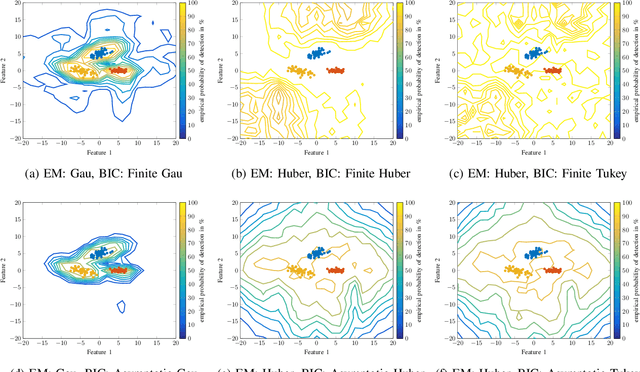
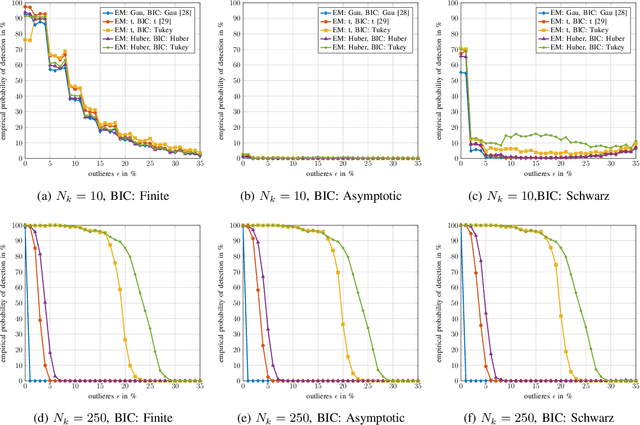
Robustly determining the optimal number of clusters in a data set is an essential factor in a wide range of applications. Cluster enumeration becomes challenging when the true underlying structure in the observed data is corrupted by heavy-tailed noise and outliers. Recently, Bayesian cluster enumeration criteria have been derived by formulating cluster enumeration as maximization of the posterior probability of candidate models. This article generalizes robust Bayesian cluster enumeration so that it can be used with any arbitrary Real Elliptically Symmetric (RES) distributed mixture model. Our framework also covers the case of M-estimators that allow for mixture models, which are decoupled from a specific probability distribution. Examples of Huber's and Tukey's M-estimators are discussed. We derive a robust criterion for for data sets with finite sample size, and also provide an asymptotic approximation to reduce the computational cost at large sample sizes. The algorithms are applied to simulated and real-world data sets, including radar-based person identification, and show a significant robustness improvement in comparison to existing methods.