 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust M-Estimation Based Bayesian Cluster Enumeration for Real Elliptically Symmetric Distributions
Paper and Code
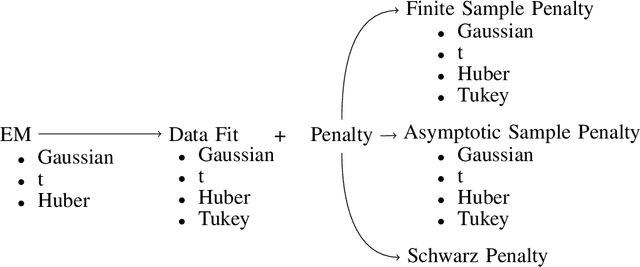
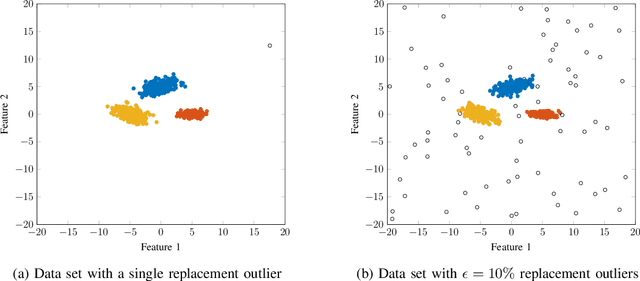
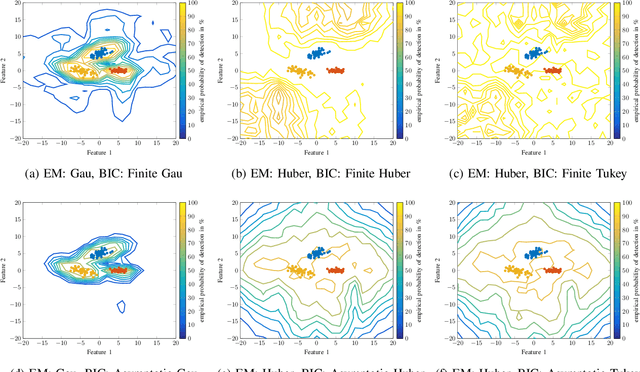
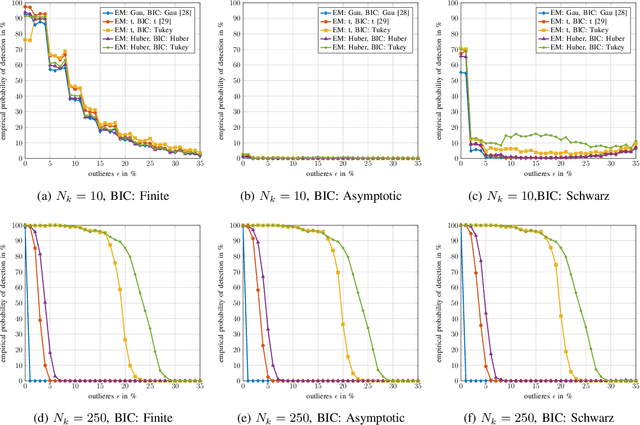
Robustly determining the optimal number of clusters in a data set is an essential factor in a wide range of applications. Cluster enumeration becomes challenging when the true underlying structure in the observed data is corrupted by heavy-tailed noise and outliers. Recently, Bayesian cluster enumeration criteria have been derived by formulating cluster enumeration as maximization of the posterior probability of candidate models. This article generalizes robust Bayesian cluster enumeration so that it can be used with any arbitrary Real Elliptically Symmetric (RES) distributed mixture model. Our framework also covers the case of M-estimators that allow for mixture models, which are decoupled from a specific probability distribution. Examples of Huber's and Tukey's M-estimators are discussed. We derive a robust criterion for for data sets with finite sample size, and also provide an asymptotic approximation to reduce the computational cost at large sample sizes. The algorithms are applied to simulated and real-world data sets, including radar-based person identification, and show a significant robustness improvement in comparison to existing methods.