 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuMaMi28: Real-Time Millimeter-Wave Massive MIMO Systems with Antenna Selection
Sep 07, 2021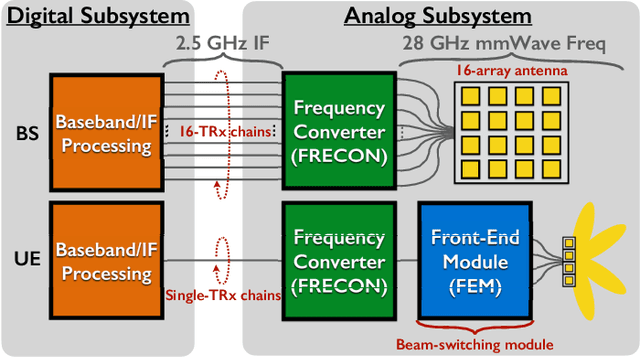
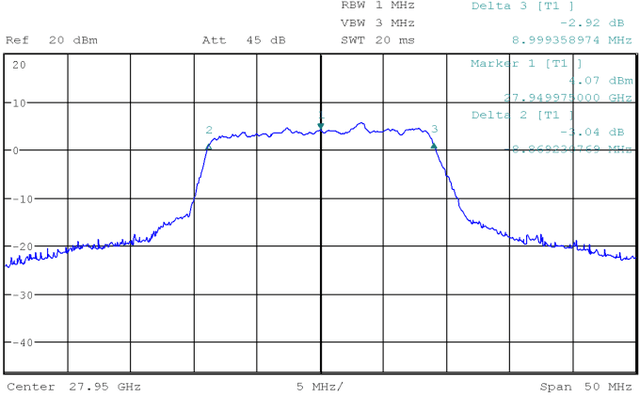
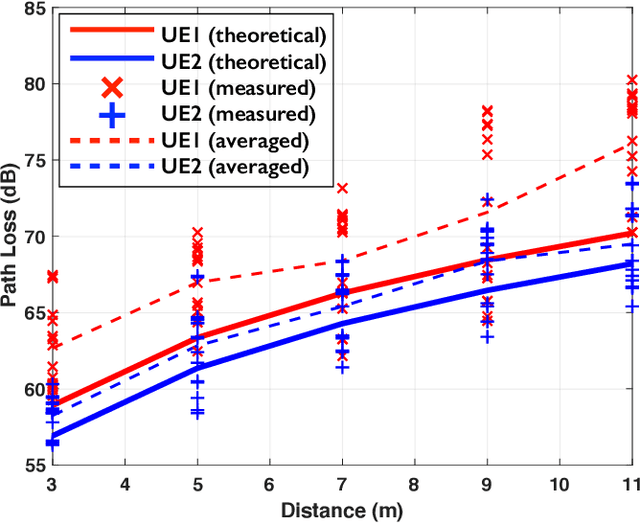
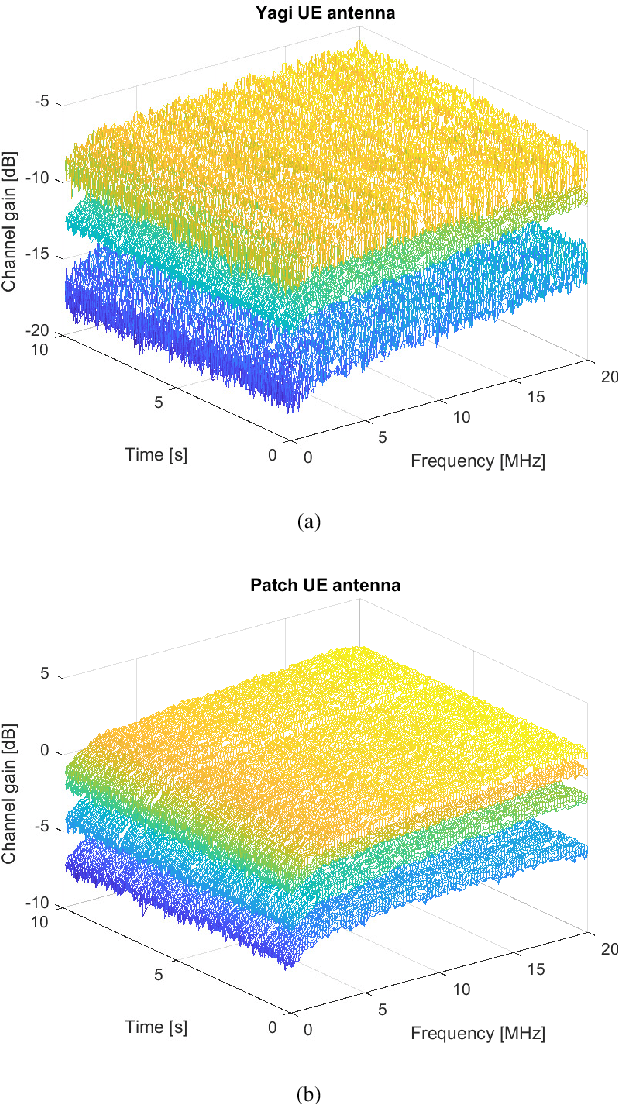
This paper presents LuMaMi28, a real-time 28 GHz massive multiple-input multiple-output (MIMO) testbed. In this testbed, the base station has 16 transceiver chains with a fully-digital beamforming architecture (with different pre-coding algorithms) and simultaneously supports multiple user equipments (UEs) with spatial multiplexing. The UEs are equipped with a beam-switchable antenna array for real-time antenna selection where the one with the highest channel magnitude, out of four pre-defined beams, is selected. For the beam-switchable antenna array, we consider two kinds of UE antennas, with different beam-width and different peak-gain. Based on this testbed, we provide measurement results for millimeter-wave (mmWave) massive MIMO performance in different real-life scenarios with static and mobile UEs. We explore the potential benefit of the mmWave massive MIMO systems with antenna selection based on measured channel data, and discuss the performance results through real-time measurements.
Improving Fairness of AI Systems with Lossless De-biasing
May 10, 2021
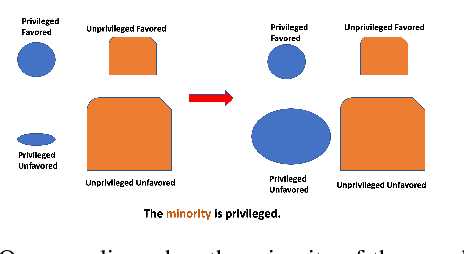

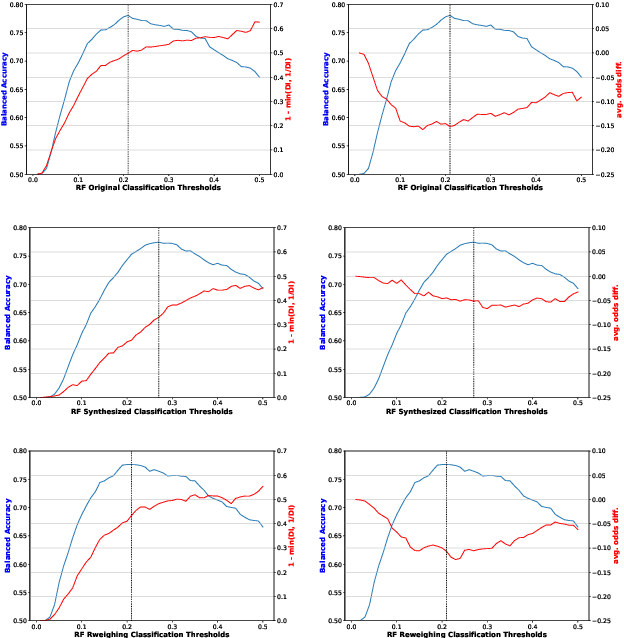
In today's society, AI systems are increasingly used to make critical decisions such as credit scoring and patient triage. However, great convenience brought by AI systems comes with troubling prevalence of bias against underrepresented groups. Mitigating bias in AI systems to increase overall fairness has emerged as an important challenge. Existing studies on mitigating bias in AI systems focus on eliminating sensitive demographic information embedded in data. Given the temporal and contextual complexity of conceptualizing fairness, lossy treatment of demographic information may contribute to an unnecessary trade-off between accuracy and fairness, especially when demographic attributes and class labels are correlated. In this paper, we present an information-lossless de-biasing technique that targets the scarcity of data in the disadvantaged group. Unlike the existing work, we demonstrate, both theoretically and empirically, that oversampling underrepresented groups can not only mitigate algorithmic bias in AI systems that consistently predict a favorable outcome for a certain group, but improve overall accuracy by mitigating class imbalance within data that leads to a bias towards the majority class. We demonstrate the effectiveness of our technique on real datasets using a variety of fairness metrics.
Differentially Private Imaging via Latent Space Manipulation
Mar 08, 2021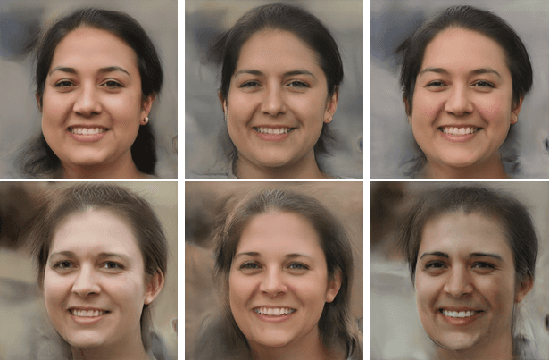


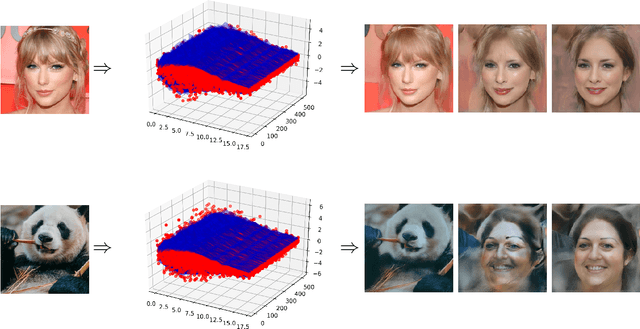
There is growing concern about image privacy due to the popularity of social media and photo devices, along with increasing use of face recognition systems. However, established image de-identification techniques are either too subject to re-identification, produce photos that are insufficiently realistic, or both. To tackle this, we present a novel approach for image obfuscation by manipulating latent spaces of an unconditionally trained generative model that is able to synthesize photo-realistic facial images of high resolution. This manipulation is done in a way that satisfies the formal privacy standard of local differential privacy. To our knowledge, this is the first approach to image privacy that satisfies $\varepsilon$-differential privacy \emph{for the person.}
Differentially Private Naïve Bayes Classifier using Smooth Sensitivity
Mar 31, 2020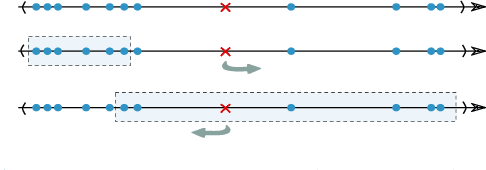
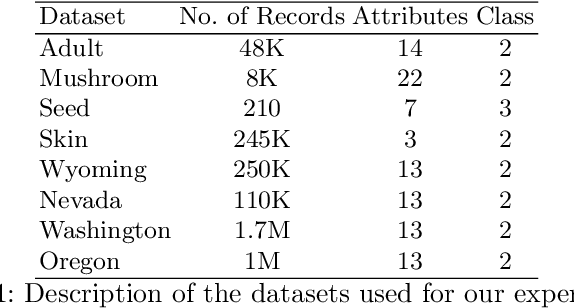
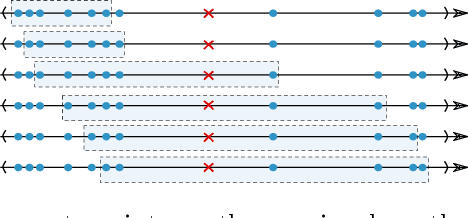
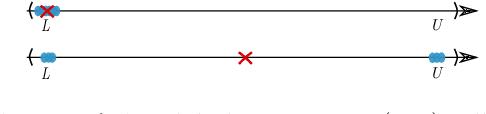
With the increasing collection of users' data, protecting individual privacy has gained more interest. Differential Privacy is a strong concept of protecting individuals. Na\"ive Bayes is one of the popular machine learning algorithm, used as a baseline for many tasks. In this work, we have provided a differentially private Na\"ive Bayes classifier that adds noise proportional to the Smooth Sensitivity of its parameters. We have compared our result to Vaidya, Shafiq, Basu, and Hong in which they have scaled the noise to the global sensitivity of the parameters. Our experiment results on the real-world datasets show that the accuracy of our method has improved significantly while still preserving $\varepsilon$-differential privacy.
K-Nearest Neighbor Classification Using Anatomized Data
Oct 19, 2016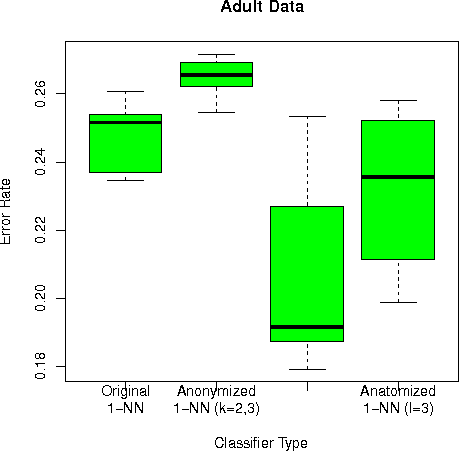
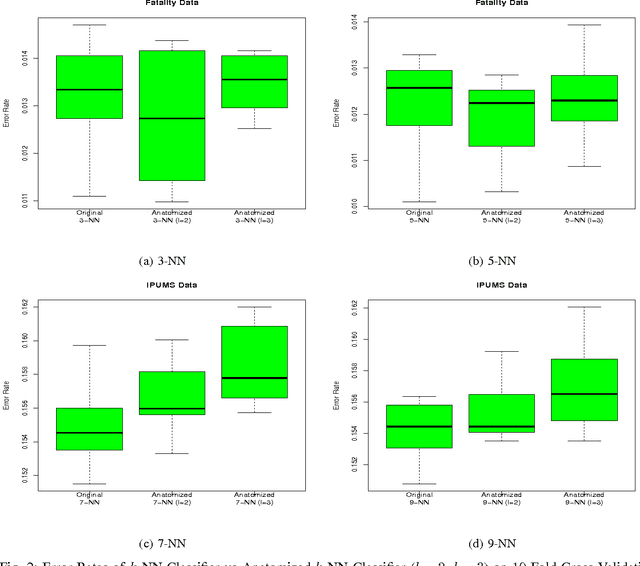
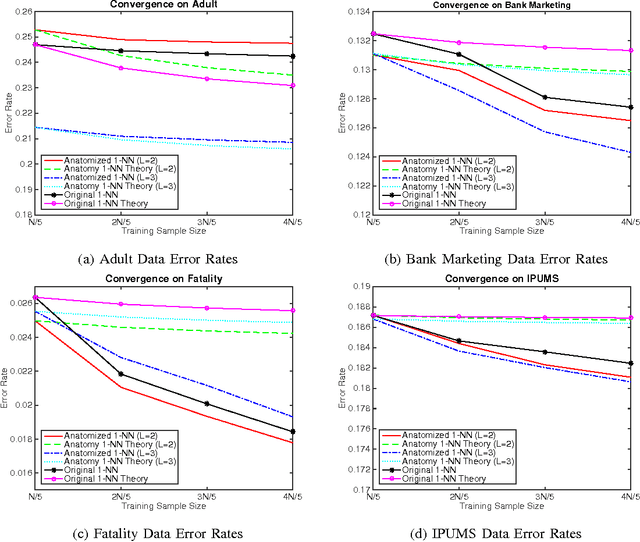
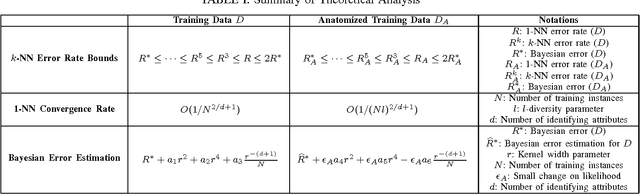
This paper analyzes k nearest neighbor classification with training data anonymized using anatomy. Anatomy preserves all data values, but introduces uncertainty in the mapping between identifying and sensitive values. We first study the theoretical effect of the anatomized training data on the k nearest neighbor error rate bounds, nearest neighbor convergence rate, and Bayesian error. We then validate the derived bounds empirically. We show that 1) Learning from anatomized data approaches the limits of learning through the unprotected data (although requiring larger training data), and 2) nearest neighbor using anatomized data outperforms nearest neighbor on generalization-based anonymization.
Statistical Learning Theory Approach for Data Classification with l-diversity
Oct 18, 2016
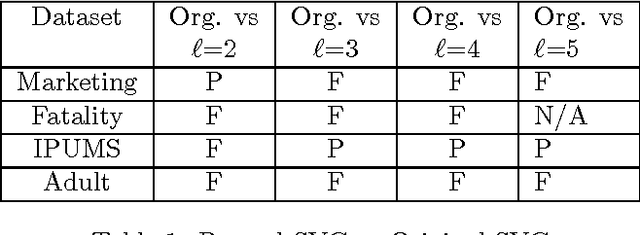
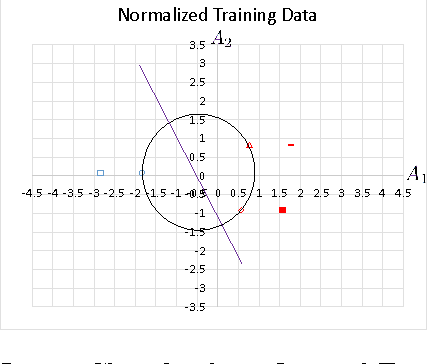
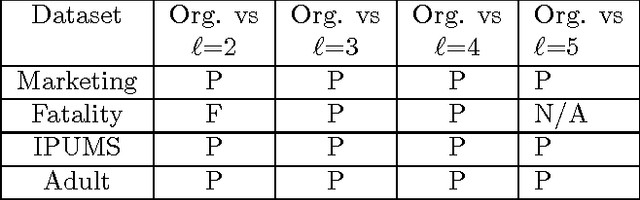
Corporations are retaining ever-larger corpuses of personal data; the frequency or breaches and corresponding privacy impact have been rising accordingly. One way to mitigate this risk is through use of anonymized data, limiting the exposure of individual data to only where it is absolutely needed. This would seem particularly appropriate for data mining, where the goal is generalizable knowledge rather than data on specific individuals. In practice, corporate data miners often insist on original data, for fear that they might "miss something" with anonymized or differentially private approaches. This paper provides a theoretical justification for the use of anonymized data. Specifically, we show that a support vector classifier trained on anatomized data satisfying l-diversity should be expected to do as well as on the original data. Anatomy preserves all data values, but introduces uncertainty in the mapping between identifying and sensitive values, thus satisfying l-diversity. The theoretical effectiveness of the proposed approach is validated using several publicly available datasets, showing that we outperform the state of the art for support vector classification using training data protected by k-anonymity, and are comparable to learning on the original data.
Decision Tree Classification on Outsourced Data
Oct 18, 2016
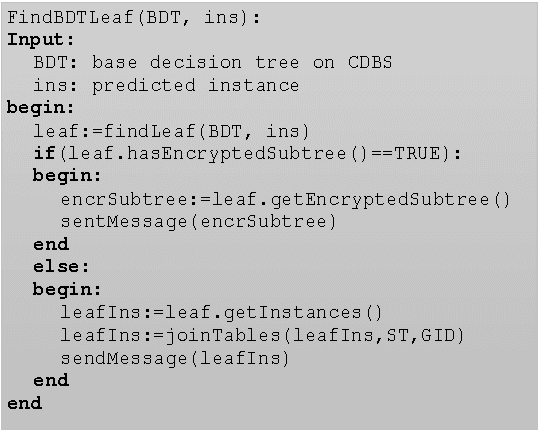

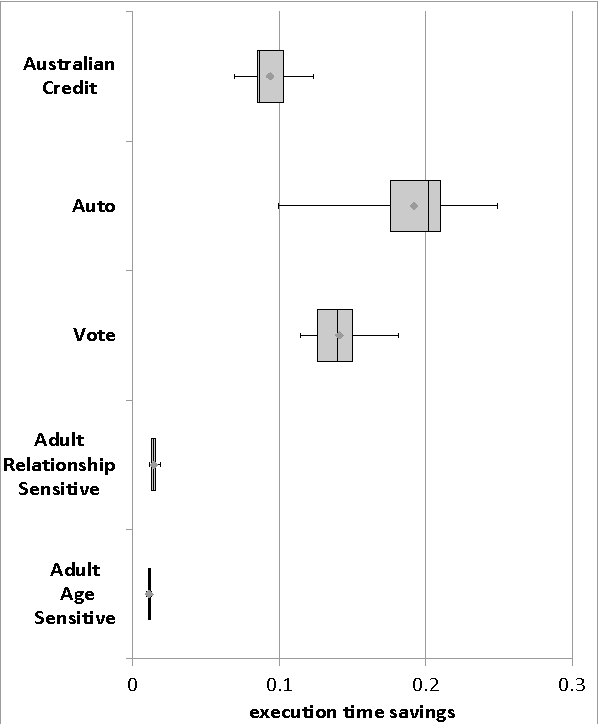
This paper proposes a client-server decision tree learning method for outsourced private data. The privacy model is anatomization/fragmentation: the server sees data values, but the link between sensitive and identifying information is encrypted with a key known only to clients. Clients have limited processing and storage capability. Both sensitive and identifying information thus are stored on the server. The approach presented also retains most processing at the server, and client-side processing is amortized over predictions made by the clients. Experiments on various datasets show that the method produces decision trees approaching the accuracy of a non-private decision tree, while substantially reducing the client's computing resource requirements.