 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Fairness of AI Systems with Lossless De-biasing
Paper and Code
May 10, 2021

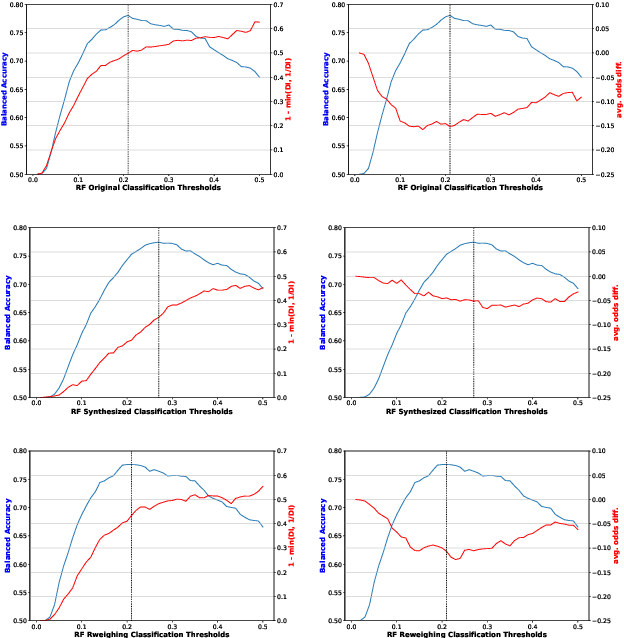
In today's society, AI systems are increasingly used to make critical decisions such as credit scoring and patient triage. However, great convenience brought by AI systems comes with troubling prevalence of bias against underrepresented groups. Mitigating bias in AI systems to increase overall fairness has emerged as an important challenge. Existing studies on mitigating bias in AI systems focus on eliminating sensitive demographic information embedded in data. Given the temporal and contextual complexity of conceptualizing fairness, lossy treatment of demographic information may contribute to an unnecessary trade-off between accuracy and fairness, especially when demographic attributes and class labels are correlated. In this paper, we present an information-lossless de-biasing technique that targets the scarcity of data in the disadvantaged group. Unlike the existing work, we demonstrate, both theoretically and empirically, that oversampling underrepresented groups can not only mitigate algorithmic bias in AI systems that consistently predict a favorable outcome for a certain group, but improve overall accuracy by mitigating class imbalance within data that leads to a bias towards the majority class. We demonstrate the effectiveness of our technique on real datasets using a variety of fairness metrics.