 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision Tree Classification on Outsourced Data
Paper and Code
Oct 18, 2016
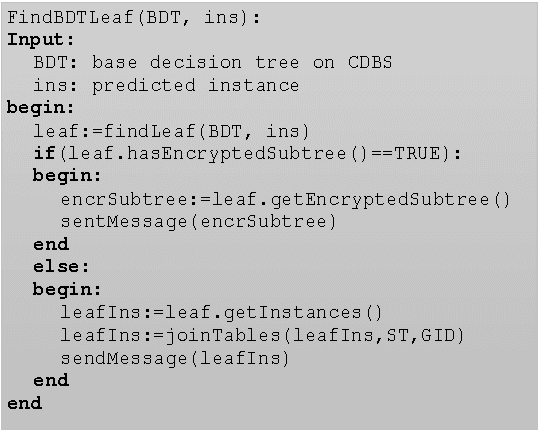

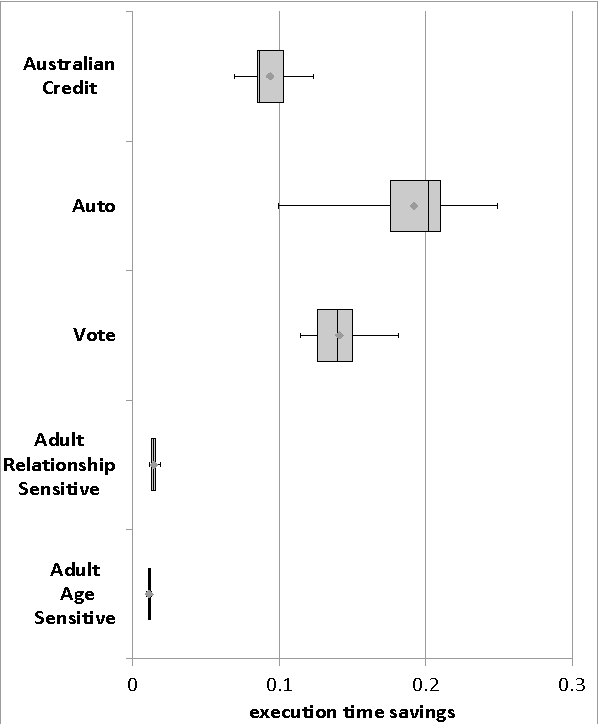
This paper proposes a client-server decision tree learning method for outsourced private data. The privacy model is anatomization/fragmentation: the server sees data values, but the link between sensitive and identifying information is encrypted with a key known only to clients. Clients have limited processing and storage capability. Both sensitive and identifying information thus are stored on the server. The approach presented also retains most processing at the server, and client-side processing is amortized over predictions made by the clients. Experiments on various datasets show that the method produces decision trees approaching the accuracy of a non-private decision tree, while substantially reducing the client's computing resource requirements.