 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-Nearest Neighbor Classification Using Anatomized Data
Oct 19, 2016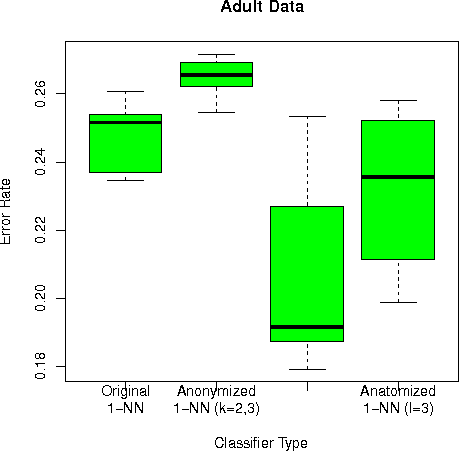
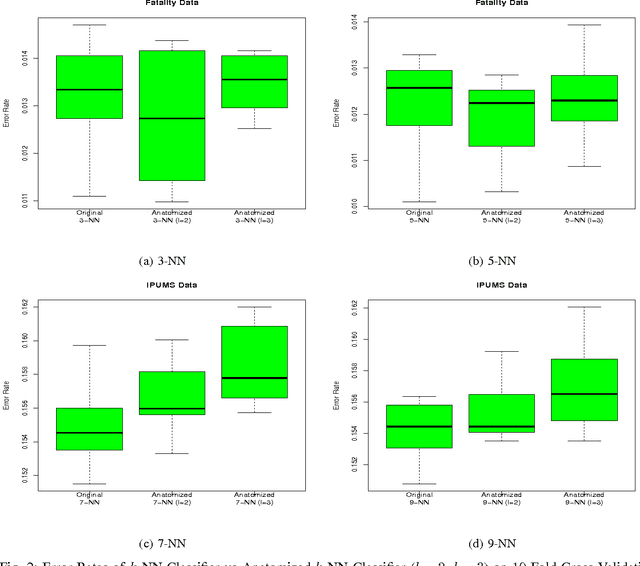
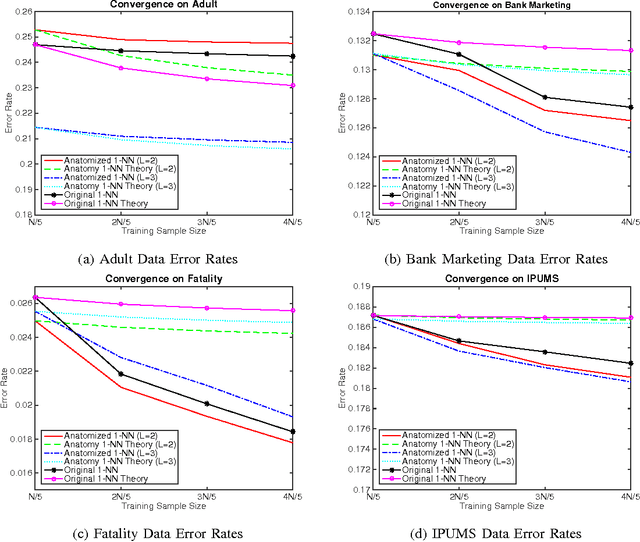
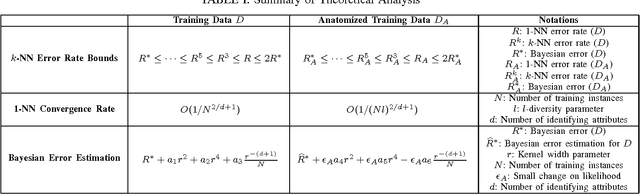
This paper analyzes k nearest neighbor classification with training data anonymized using anatomy. Anatomy preserves all data values, but introduces uncertainty in the mapping between identifying and sensitive values. We first study the theoretical effect of the anatomized training data on the k nearest neighbor error rate bounds, nearest neighbor convergence rate, and Bayesian error. We then validate the derived bounds empirically. We show that 1) Learning from anatomized data approaches the limits of learning through the unprotected data (although requiring larger training data), and 2) nearest neighbor using anatomized data outperforms nearest neighbor on generalization-based anonymization.
Statistical Learning Theory Approach for Data Classification with l-diversity
Oct 18, 2016
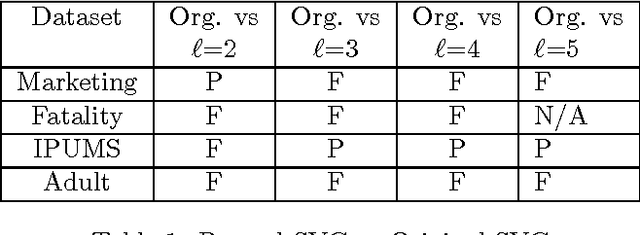
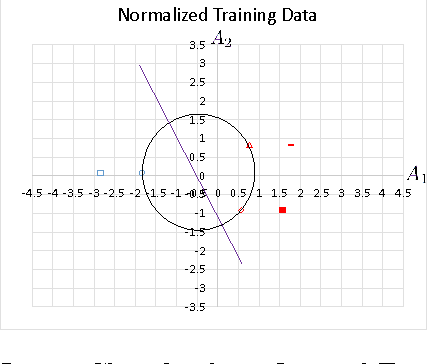
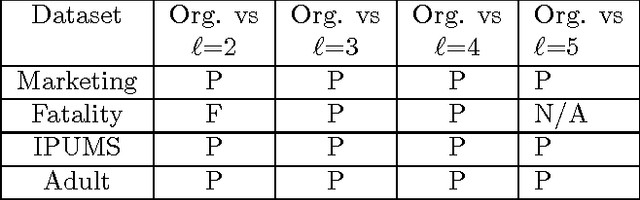
Corporations are retaining ever-larger corpuses of personal data; the frequency or breaches and corresponding privacy impact have been rising accordingly. One way to mitigate this risk is through use of anonymized data, limiting the exposure of individual data to only where it is absolutely needed. This would seem particularly appropriate for data mining, where the goal is generalizable knowledge rather than data on specific individuals. In practice, corporate data miners often insist on original data, for fear that they might "miss something" with anonymized or differentially private approaches. This paper provides a theoretical justification for the use of anonymized data. Specifically, we show that a support vector classifier trained on anatomized data satisfying l-diversity should be expected to do as well as on the original data. Anatomy preserves all data values, but introduces uncertainty in the mapping between identifying and sensitive values, thus satisfying l-diversity. The theoretical effectiveness of the proposed approach is validated using several publicly available datasets, showing that we outperform the state of the art for support vector classification using training data protected by k-anonymity, and are comparable to learning on the original data.
Decision Tree Classification on Outsourced Data
Oct 18, 2016
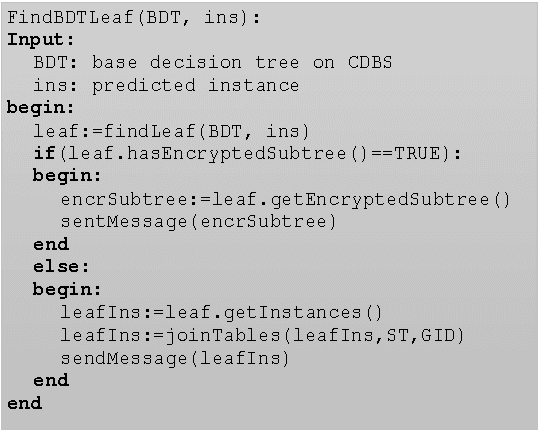

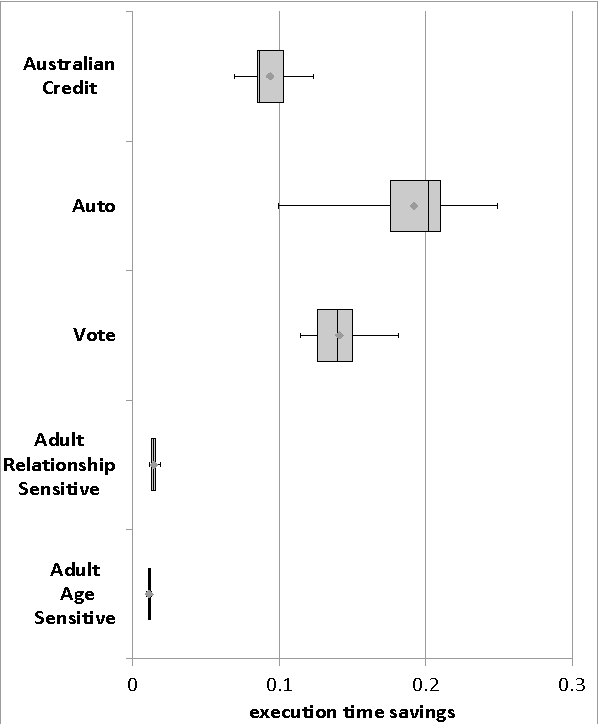
This paper proposes a client-server decision tree learning method for outsourced private data. The privacy model is anatomization/fragmentation: the server sees data values, but the link between sensitive and identifying information is encrypted with a key known only to clients. Clients have limited processing and storage capability. Both sensitive and identifying information thus are stored on the server. The approach presented also retains most processing at the server, and client-side processing is amortized over predictions made by the clients. Experiments on various datasets show that the method produces decision trees approaching the accuracy of a non-private decision tree, while substantially reducing the client's computing resource requirements.