 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Out-of-Distribution Detection with Outlier Label Exposure
Jun 03, 2024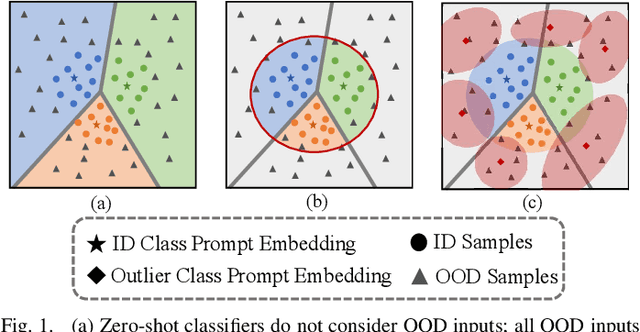

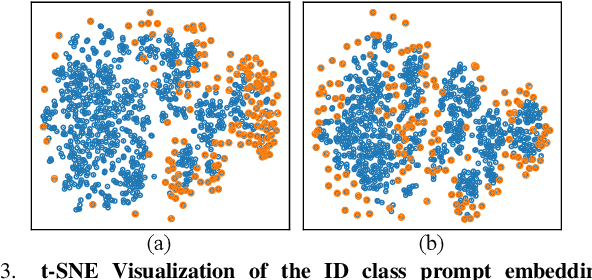

As vision-language models like CLIP are widely applied to zero-shot tasks and gain remarkable performance on in-distribution (ID) data, detecting and rejecting out-of-distribution (OOD) inputs in the zero-shot setting have become crucial for ensuring the safety of using such models on the fly. Most existing zero-shot OOD detectors rely on ID class label-based prompts to guide CLIP in classifying ID images and rejecting OOD images. In this work we instead propose to leverage a large set of diverse auxiliary outlier class labels as pseudo OOD class text prompts to CLIP for enhancing zero-shot OOD detection, an approach we called Outlier Label Exposure (OLE). The key intuition is that ID images are expected to have lower similarity to these outlier class prompts than OOD images. One issue is that raw class labels often include noise labels, e.g., synonyms of ID labels, rendering raw OLE-based detection ineffective. To address this issue, we introduce an outlier prototype learning module that utilizes the prompt embeddings of the outlier labels to learn a small set of pivotal outlier prototypes for an embedding similarity-based OOD scoring. Additionally, the outlier classes and their prototypes can be loosely coupled with the ID classes, leading to an inseparable decision region between them. Thus, we also introduce an outlier label generation module that synthesizes our outlier prototypes and ID class embeddings to generate in-between outlier prototypes to further calibrate the detection in OLE. Despite its simplicity, extensive experiments show that OLE substantially improves detection performance and achieves new state-of-the-art performance in large-scale OOD and hard OOD detection benchmarks.
Anomaly Heterogeneity Learning for Open-set Supervised Anomaly Detection
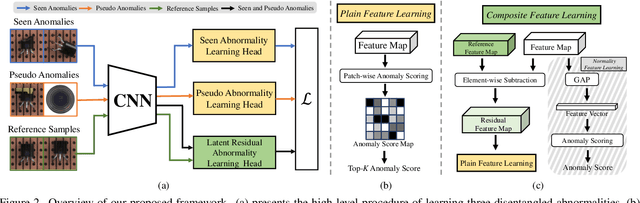
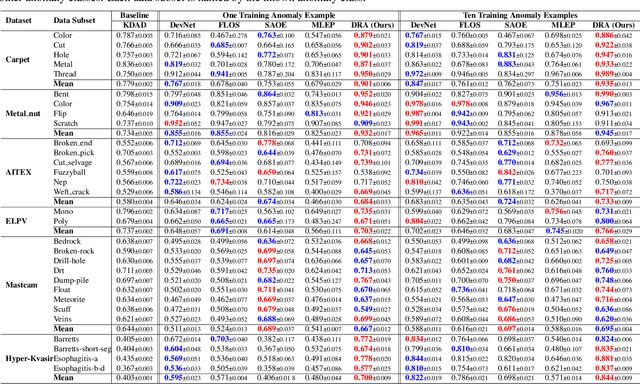
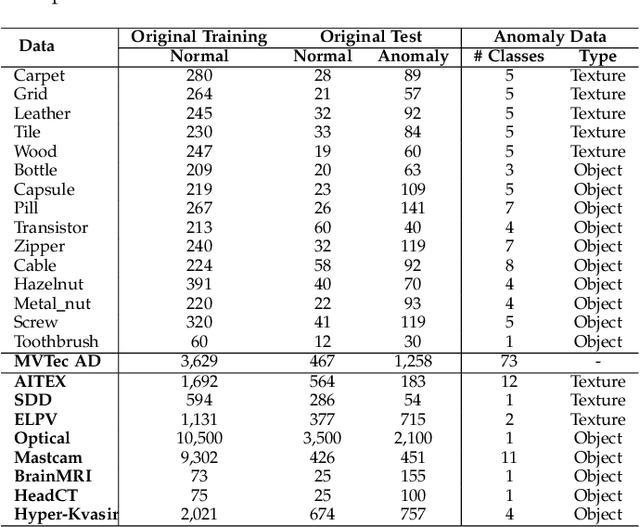
Oct 23, 2023Open-set supervised anomaly detection (OSAD) - a recently emerging anomaly detection area - aims at utilizing a few samples of anomaly classes seen during training to detect unseen anomalies (i.e., samples from open-set anomaly classes), while effectively identifying the seen anomalies. Benefiting from the prior knowledge illustrated by the seen anomalies, current OSAD methods can often largely reduce false positive errors. However, these methods treat the anomaly examples as from a homogeneous distribution, rendering them less effective in generalizing to unseen anomalies that can be drawn from any distribution. In this paper, we propose to learn heterogeneous anomaly distributions using the limited anomaly examples to address this issue. To this end, we introduce a novel approach, namely Anomaly Heterogeneity Learning (AHL), that simulates a diverse set of heterogeneous (seen and unseen) anomaly distributions and then utilizes them to learn a unified heterogeneous abnormality model. Further, AHL is a generic framework that existing OSAD models can plug and play for enhancing their abnormality modeling. Extensive experiments on nine real-world anomaly detection datasets show that AHL can 1) substantially enhance different state-of-the-art (SOTA) OSAD models in detecting both seen and unseen anomalies, achieving new SOTA performance on a large set of datasets, and 2) effectively generalize to unseen anomalies in new target domains.
Background Matters: Enhancing Out-of-distribution Detection with Domain Features
Mar 15, 2023Detecting out-of-distribution (OOD) inputs is a principal task for ensuring the safety of deploying deep-neural-network classifiers in open-world scenarios. OOD samples can be drawn from arbitrary distributions and exhibit deviations from in-distribution (ID) data in various dimensions, such as foreground semantic features (e.g., vehicle images vs. ID samples in fruit classification) and background domain features (e.g., textural images vs. ID samples in object recognition). Existing methods focus on detecting OOD samples based on the semantic features, while neglecting the other dimensions such as the domain features. This paper considers the importance of the domain features in OOD detection and proposes to leverage them to enhance the semantic-feature-based OOD detection methods. To this end, we propose a novel generic framework that can learn the domain features from the ID training samples by a dense prediction approach, with which different existing semantic-feature-based OOD detection methods can be seamlessly combined to jointly learn the in-distribution features from both the semantic and domain dimensions. Extensive experiments show that our approach 1) can substantially enhance the performance of four different state-of-the-art (SotA) OOD detection methods on multiple widely-used OOD datasets with diverse domain features, and 2) achieves new SotA performance on these benchmarks.
Residual Pattern Learning for Pixel-wise Out-of-Distribution Detection in Semantic Segmentation
Nov 26, 2022



Semantic segmentation models classify pixels into a set of known (``in-distribution'') visual classes. When deployed in an open world, the reliability of these models depends on their ability not only to classify in-distribution pixels but also to detect out-of-distribution (OoD) pixels. Historically, the poor OoD detection performance of these models has motivated the design of methods based on model re-training using synthetic training images that include OoD visual objects. Although successful, these re-trained methods have two issues: 1) their in-distribution segmentation accuracy may drop during re-training, and 2) their OoD detection accuracy does not generalise well to new contexts (e.g., country surroundings) outside the training set (e.g., city surroundings). In this paper, we mitigate these issues with: (i) a new residual pattern learning (RPL) module that assists the segmentation model to detect OoD pixels without affecting the inlier segmentation performance; and (ii) a novel context-robust contrastive learning (CoroCL) that enforces RPL to robustly detect OoD pixels among various contexts. Our approach improves by around 10\% FPR and 7\% AuPRC the previous state-of-the-art in Fishyscapes, Segment-Me-If-You-Can, and RoadAnomaly datasets. Our code is available at: https://github.com/yyliu01/RPL.
Catching Both Gray and Black Swans: Open-set Supervised Anomaly Detection
Mar 28, 2022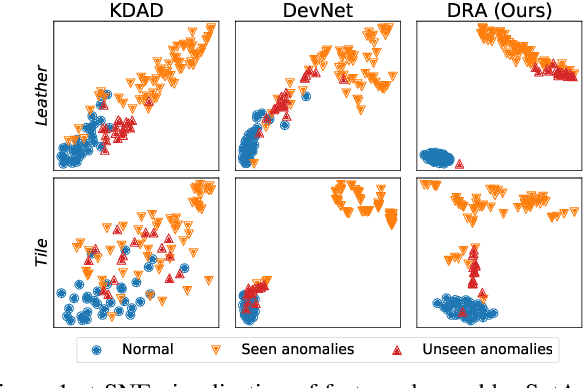
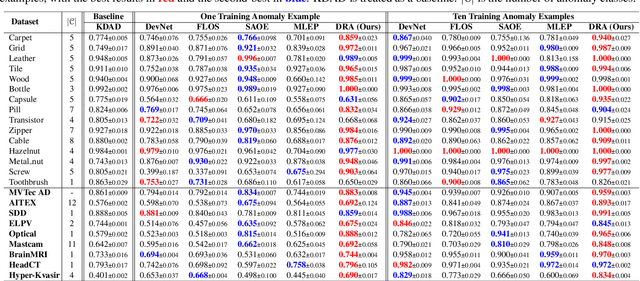
Despite most existing anomaly detection studies assume the availability of normal training samples only, a few labeled anomaly examples are often available in many real-world applications, such as defect samples identified during random quality inspection, lesion images confirmed by radiologists in daily medical screening, etc. These anomaly examples provide valuable knowledge about the application-specific abnormality, enabling significantly improved detection of similar anomalies in some recent models. However, those anomalies seen during training often do not illustrate every possible class of anomaly, rendering these models ineffective in generalizing to unseen anomaly classes. This paper tackles open-set supervised anomaly detection, in which we learn detection models using the anomaly examples with the objective to detect both seen anomalies (`gray swans') and unseen anomalies (`black swans'). We propose a novel approach that learns disentangled representations of abnormalities illustrated by seen anomalies, pseudo anomalies, and latent residual anomalies (i.e., samples that have unusual residuals compared to the normal data in a latent space), with the last two abnormalities designed to detect unseen anomalies. Extensive experiments on nine real-world anomaly detection datasets show superior performance of our model in detecting seen and unseen anomalies under diverse settings. Code and data are available at: https://github.com/choubo/DRA.
Explainable Deep Few-shot Anomaly Detection with Deviation Networks
Aug 01, 2021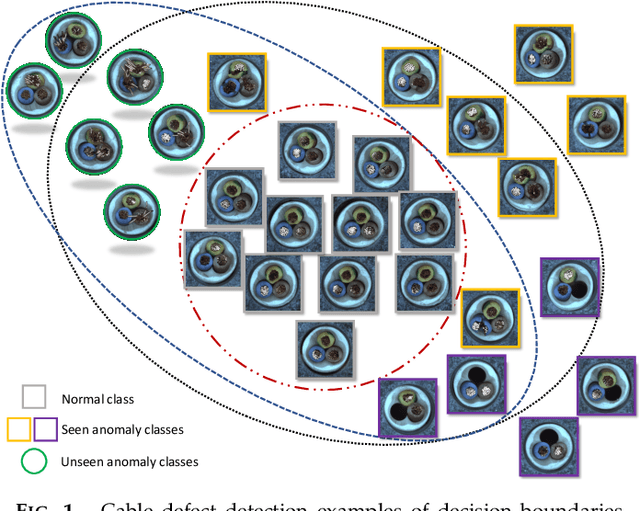
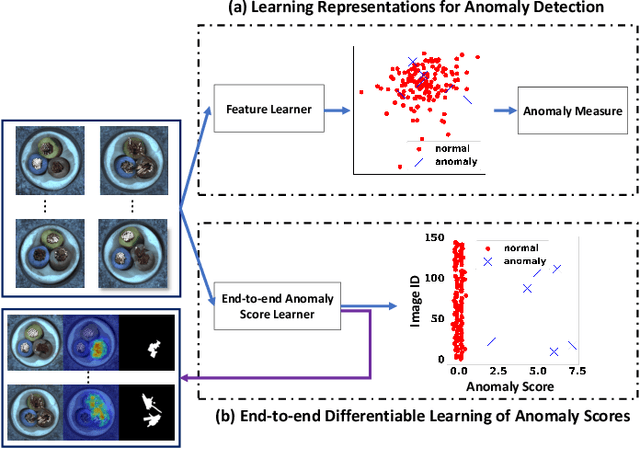
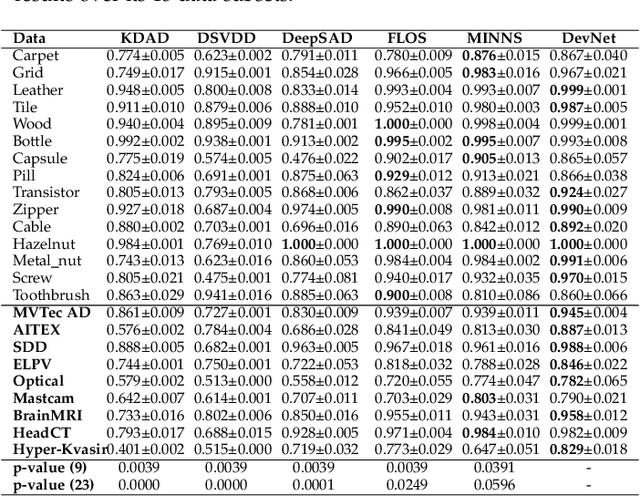
Existing anomaly detection paradigms overwhelmingly focus on training detection models using exclusively normal data or unlabeled data (mostly normal samples). One notorious issue with these approaches is that they are weak in discriminating anomalies from normal samples due to the lack of the knowledge about the anomalies. Here, we study the problem of few-shot anomaly detection, in which we aim at using a few labeled anomaly examples to train sample-efficient discriminative detection models. To address this problem, we introduce a novel weakly-supervised anomaly detection framework to train detection models without assuming the examples illustrating all possible classes of anomaly. Specifically, the proposed approach learns discriminative normality (regularity) by leveraging the labeled anomalies and a prior probability to enforce expressive representations of normality and unbounded deviated representations of abnormality. This is achieved by an end-to-end optimization of anomaly scores with a neural deviation learning, in which the anomaly scores of normal samples are imposed to approximate scalar scores drawn from the prior while that of anomaly examples is enforced to have statistically significant deviations from these sampled scores in the upper tail. Furthermore, our model is optimized to learn fine-grained normality and abnormality by top-K multiple-instance-learning-based feature subspace deviation learning, allowing more generalized representations. Comprehensive experiments on nine real-world image anomaly detection benchmarks show that our model is substantially more sample-efficient and robust, and performs significantly better than state-of-the-art competing methods in both closed-set and open-set settings. Our model can also offer explanation capability as a result of its prior-driven anomaly score learning. Code and datasets are available at: https://git.io/DevNet.