 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Cross Domain Adaptation under Extreme Label Scarcity
Sep 04, 2022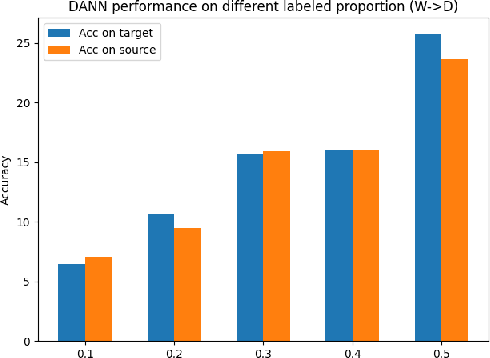
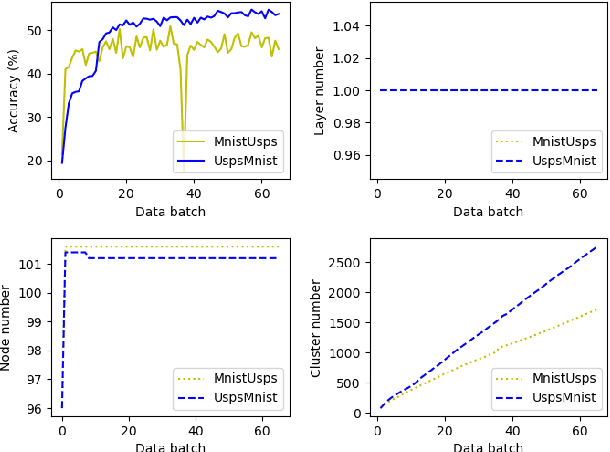
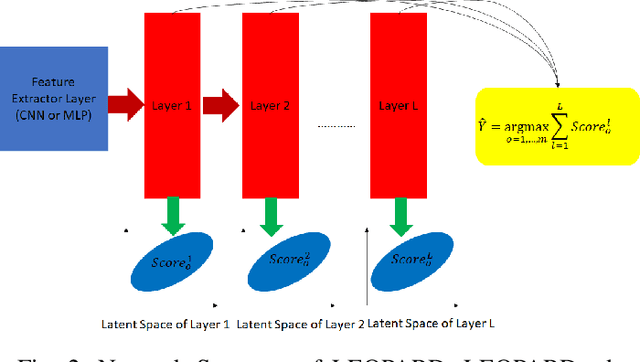
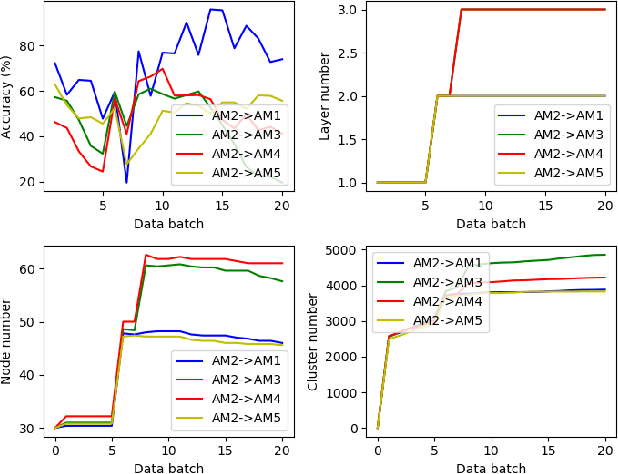
A cross domain multistream classification is a challenging problem calling for fast domain adaptations to handle different but related streams in never-ending and rapidly changing environments. Notwithstanding that existing multistream classifiers assume no labelled samples in the target stream, they still incur expensive labelling cost since they require fully labelled samples of the source stream. This paper aims to attack the problem of extreme label shortage in the cross domain multistream classification problems where only very few labelled samples of the source stream are provided before process runs. Our solution, namely Learning Streaming Process from Partial Ground Truth (LEOPARD), is built upon a flexible deep clustering network where its hidden nodes, layers and clusters are added and removed dynamically in respect to varying data distributions. A deep clustering strategy is underpinned by a simultaneous feature learning and clustering technique leading to clustering-friendly latent spaces. A domain adaptation strategy relies on the adversarial domain adaptation technique where a feature extractor is trained to fool a domain classifier classifying source and target streams. Our numerical study demonstrates the efficacy of LEOPARD where it delivers improved performances compared to prominent algorithms in 15 of 24 cases. Source codes of LEOPARD are shared in \url{https://github.com/wengweng001/LEOPARD.git} to enable further study.
Scalable Teacher Forcing Network for Semi-Supervised Large Scale Data Streams
Jun 26, 2021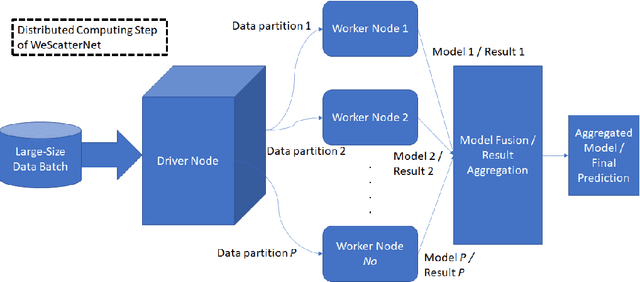
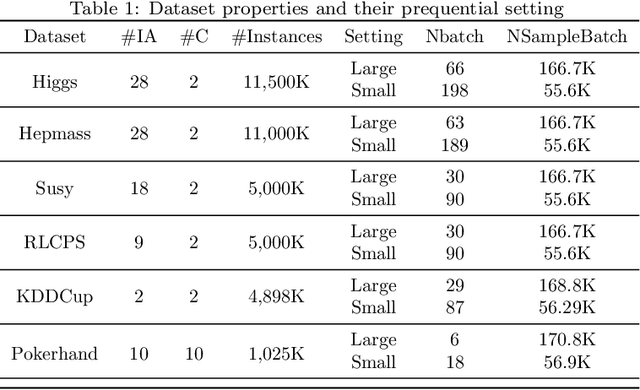
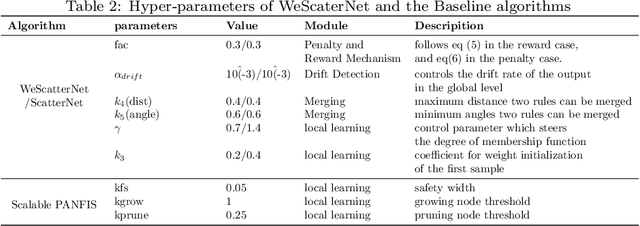
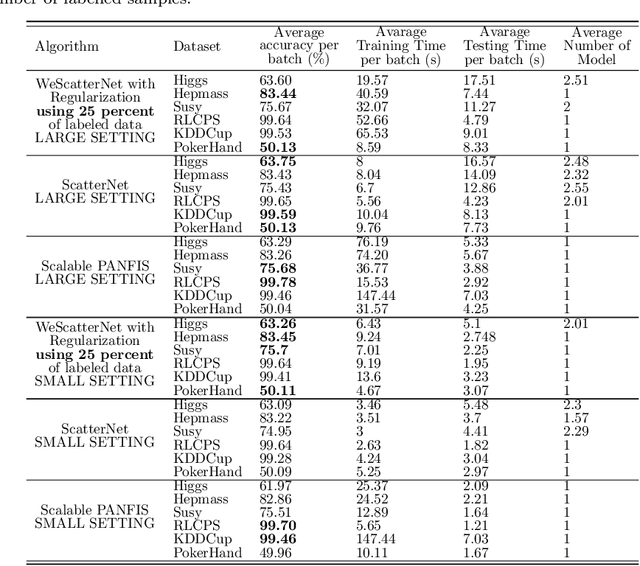
The large-scale data stream problem refers to high-speed information flow which cannot be processed in scalable manner under a traditional computing platform. This problem also imposes expensive labelling cost making the deployment of fully supervised algorithms unfeasible. On the other hand, the problem of semi-supervised large-scale data streams is little explored in the literature because most works are designed in the traditional single-node computing environments while also being fully supervised approaches. This paper offers Weakly Supervised Scalable Teacher Forcing Network (WeScatterNet) to cope with the scarcity of labelled samples and the large-scale data streams simultaneously. WeScatterNet is crafted under distributed computing platform of Apache Spark with a data-free model fusion strategy for model compression after parallel computing stage. It features an open network structure to address the global and local drift problems while integrating a data augmentation, annotation and auto-correction ($DA^3$) method for handling partially labelled data streams. The performance of WeScatterNet is numerically evaluated in the six large-scale data stream problems with only $25\%$ label proportions. It shows highly competitive performance even if compared with fully supervised learners with $100\%$ label proportions.
* This paper has been accepted for publication in Information Sciences
Automatic Construction of Multi-layer Perceptron Network from Streaming Examples
Oct 08, 2019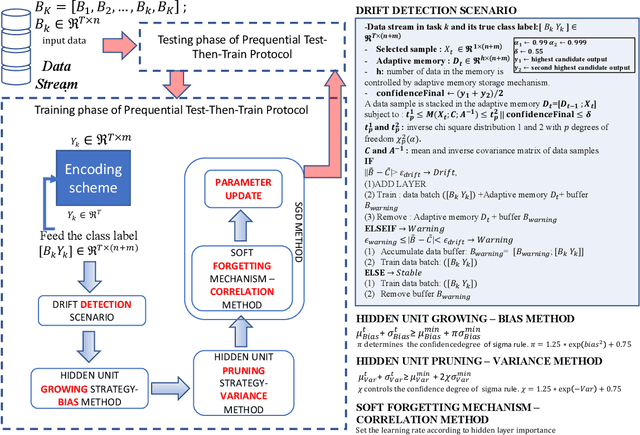
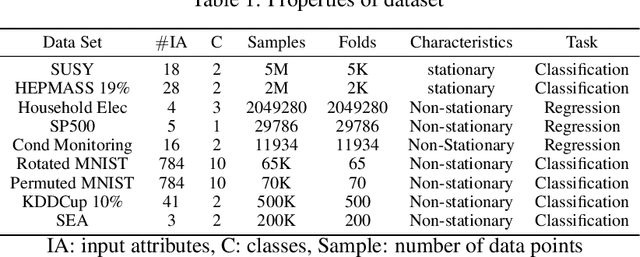
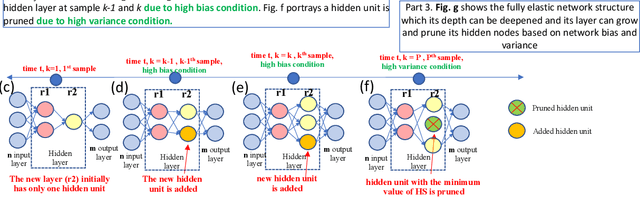
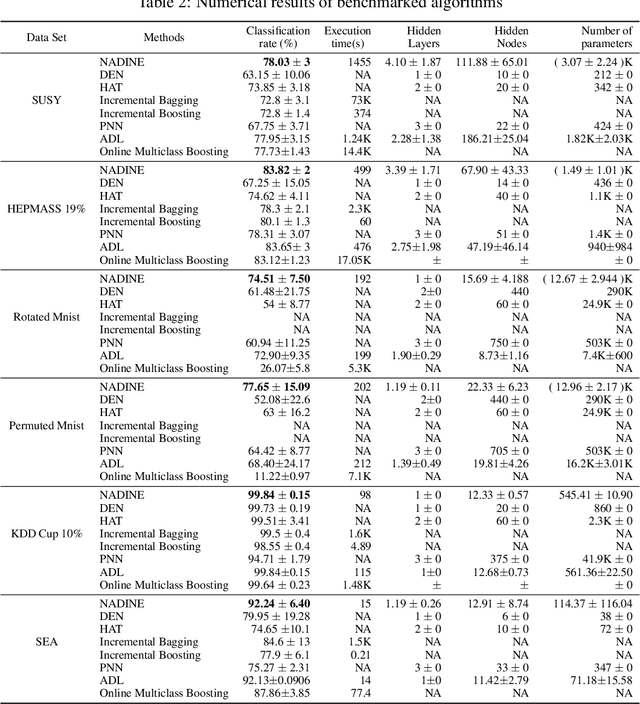
Autonomous construction of deep neural network (DNNs) is desired for data streams because it potentially offers two advantages: proper model's capacity and quick reaction to drift and shift. While the self-organizing mechanism of DNNs remains an open issue, this task is even more challenging to be developed for standard multi-layer DNNs than that using the different-depth structures, because the addition of a new layer results in information loss of previously trained knowledge. A Neural Network with Dynamically Evolved Capacity (NADINE) is proposed in this paper. NADINE features a fully open structure where its network structure, depth and width, can be automatically evolved from scratch in an online manner and without the use of problem-specific thresholds. NADINE is structured under a standard MLP architecture and the catastrophic forgetting issue during the hidden layer addition phase is resolved using the proposal of soft-forgetting and adaptive memory methods. The advantage of NADINE, namely elastic structure and online learning trait, is numerically validated using nine data stream classification and regression problems where it demonstrates performance improvement over prominent algorithms in all problems. In addition, it is capable of dealing with data stream regression and classification problems equally well.
Evolving Large-Scale Data Stream Analytics based on Scalable PANFIS
Jul 18, 2018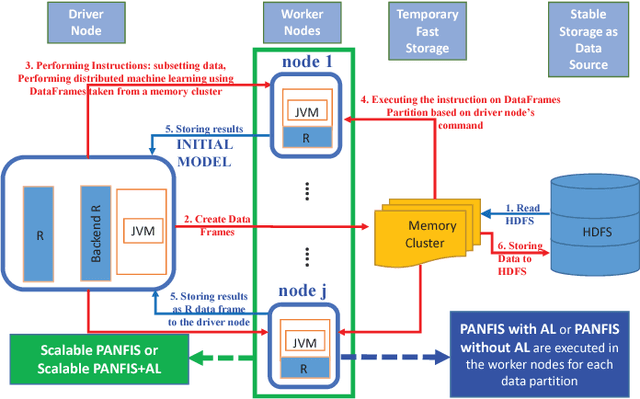
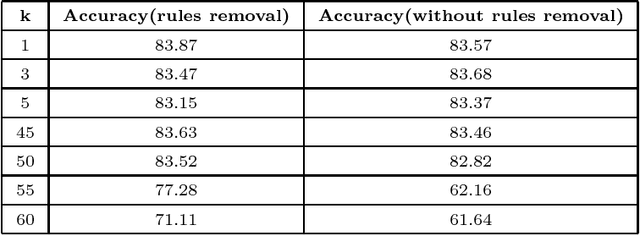
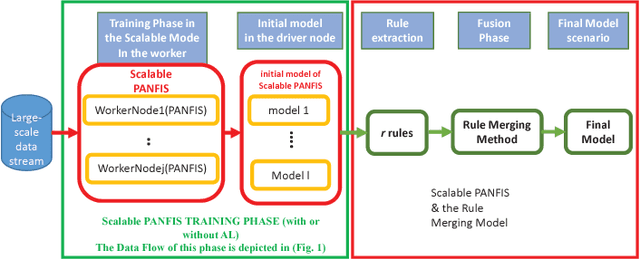
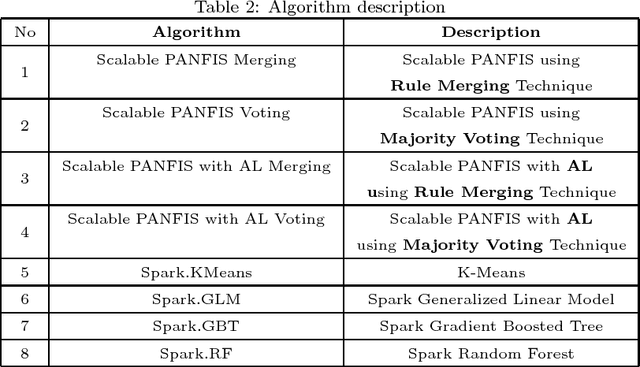
Many distributed machine learning frameworks have recently been built to speed up the large-scale data learning process. However, most distributed machine learning used in these frameworks still uses an offline algorithm model which cannot cope with the data stream problems. In fact, large-scale data are mostly generated by the non-stationary data stream where its pattern evolves over time. To address this problem, we propose a novel Evolving Large-scale Data Stream Analytics framework based on a Scalable Parsimonious Network based on Fuzzy Inference System (Scalable PANFIS), where the PANFIS evolving algorithm is distributed over the worker nodes in the cloud to learn large-scale data stream. Scalable PANFIS framework incorporates the active learning (AL) strategy and two model fusion methods. The AL accelerates the distributed learning process to generate an initial evolving large-scale data stream model (initial model), whereas the two model fusion methods aggregate an initial model to generate the final model. The final model represents the update of current large-scale data knowledge which can be used to infer future data. Extensive experiments on this framework are validated by measuring the accuracy and running time of four combinations of Scalable PANFIS and other Spark-based built in algorithms. The results indicate that Scalable PANFIS with AL improves the training time to be almost two times faster than Scalable PANFIS without AL. The results also show both rule merging and the voting mechanisms yield similar accuracy in general among Scalable PANFIS algorithms and they are generally better than Spark-based algorithms. In terms of running time, the Scalable PANFIS training time outperforms all Spark-based algorithms when classifying numerous benchmark datasets.
* 20 pages, 5 figures