 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Research for Recommender Systems
Mar 08, 2026The technical foundations of recommender systems have progressed from collaborative filtering to complex neural models and, more recently, large language models. Despite these technological advances, deployed systems often underserve their users by simply presenting a list of items, leaving the burden of exploration, comparison, and synthesis entirely on the user. This paper argues that this traditional "tool-based" paradigm fundamentally limits user experience, as the system acts as a passive filter rather than an active assistant. To address this limitation, we propose a novel deep research paradigm for recommendation, which replaces conventional item lists with comprehensive, user-centric reports. We instantiate this paradigm through RecPilot, a multi-agent framework comprising two core components: a user trajectory simulation agent that autonomously explores the item space, and a self-evolving report generation agent that synthesizes the findings into a coherent, interpretable report tailored to support user decisions. This approach reframes recommendation as a proactive, agent-driven service. Extensive experiments on public datasets demonstrate that RecPilot not only achieves strong performance in modeling user behaviors but also generates highly persuasive reports that substantially reduce user effort in item evaluation, validating the potential of this new interaction paradigm.
STARec: An Efficient Agent Framework for Recommender Systems via Autonomous Deliberate Reasoning
Aug 26, 2025While modern recommender systems are instrumental in navigating information abundance, they remain fundamentally limited by static user modeling and reactive decision-making paradigms. Current large language model (LLM)-based agents inherit these shortcomings through their overreliance on heuristic pattern matching, yielding recommendations prone to shallow correlation bias, limited causal inference, and brittleness in sparse-data scenarios. We introduce STARec, a slow-thinking augmented agent framework that endows recommender systems with autonomous deliberative reasoning capabilities. Each user is modeled as an agent with parallel cognitions: fast response for immediate interactions and slow reasoning that performs chain-of-thought rationales. To cultivate intrinsic slow thinking, we develop anchored reinforcement training - a two-stage paradigm combining structured knowledge distillation from advanced reasoning models with preference-aligned reward shaping. This hybrid approach scaffolds agents in acquiring foundational capabilities (preference summarization, rationale generation) while enabling dynamic policy adaptation through simulated feedback loops. Experiments on MovieLens 1M and Amazon CDs benchmarks demonstrate that STARec achieves substantial performance gains compared with state-of-the-art baselines, despite using only 0.4% of the full training data.
Learning to Rasterize Differentiable
Nov 23, 2022Differentiable rasterization changes the common formulation of primitive rasterization -- which has zero gradients almost everywhere, due to discontinuous edges and occlusion -- to an alternative one, which is not subject to this limitation and has similar optima. These alternative versions in general are ''soft'' versions of the original one. Unfortunately, it is not clear, what exact way of softening will provide the best performance in terms of converging the most reliability to a desired goal. Previous work has analyzed and compared several combinations of softening. In this work, we take it a step further and, instead of making a combinatorical choice of softening operations, parametrize the continuous space of all softening operations. We study meta-learning a parametric S-shape curve as well as an MLP over a set of inverse rendering tasks, so that it generalizes to new and unseen differentiable rendering tasks with optimal softness.
U3E: Unsupervised and Erasure-based Evidence Extraction for Machine Reading Comprehension
Oct 11, 2022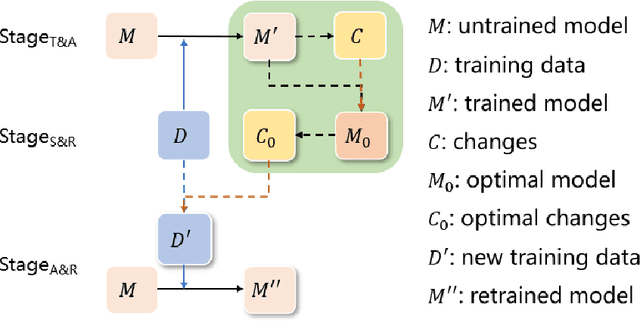
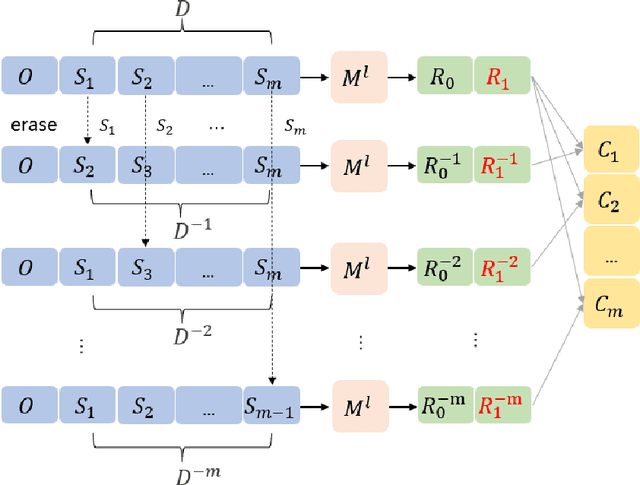
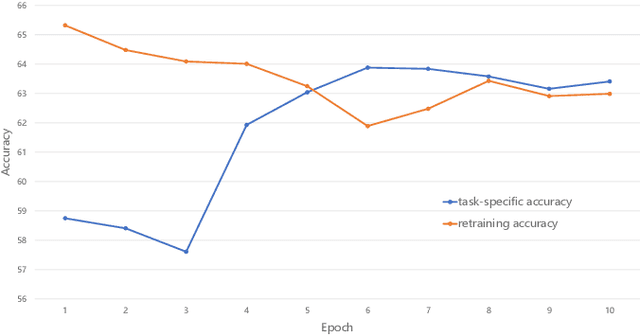
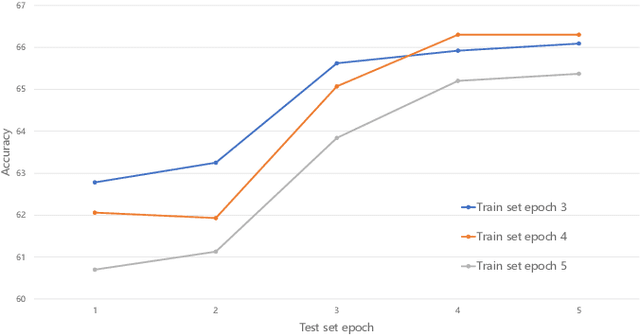
More tasks in Machine Reading Comprehension(MRC) require, in addition to answer prediction, the extraction of evidence sentences that support the answer. However, the annotation of supporting evidence sentences is usually time-consuming and labor-intensive. In this paper, to address this issue and considering that most of the existing extraction methods are semi-supervised, we propose an unsupervised evidence extraction method (U3E). U3E takes the changes after sentence-level feature erasure in the document as input, simulating the decline in problem-solving ability caused by human memory decline. In order to make selections on the basis of fully understanding the semantics of the original text, we also propose metrics to quickly select the optimal memory model for this input changes. To compare U3E with typical evidence extraction methods and investigate its effectiveness in evidence extraction, we conduct experiments on different datasets. Experimental results show that U3E is simple but effective, not only extracting evidence more accurately, but also significantly improving model performance.