 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSODAWideNet++: Combining Attention and Convolutions for Salient Object Detection
Aug 29, 2024



Salient Object Detection (SOD) has traditionally relied on feature refinement modules that utilize the features of an ImageNet pre-trained backbone. However, this approach limits the possibility of pre-training the entire network because of the distinct nature of SOD and image classification. Additionally, the architecture of these backbones originally built for Image classification is sub-optimal for a dense prediction task like SOD. To address these issues, we propose a novel encoder-decoder-style neural network called SODAWideNet++ that is designed explicitly for SOD. Inspired by the vision transformers ability to attain a global receptive field from the initial stages, we introduce the Attention Guided Long Range Feature Extraction (AGLRFE) module, which combines large dilated convolutions and self-attention. Specifically, we use attention features to guide long-range information extracted by multiple dilated convolutions, thus taking advantage of the inductive biases of a convolution operation and the input dependency brought by self-attention. In contrast to the current paradigm of ImageNet pre-training, we modify 118K annotated images from the COCO semantic segmentation dataset by binarizing the annotations to pre-train the proposed model end-to-end. Further, we supervise the background predictions along with the foreground to push our model to generate accurate saliency predictions. SODAWideNet++ performs competitively on five different datasets while only containing 35% of the trainable parameters compared to the state-of-the-art models. The code and pre-computed saliency maps are provided at https://github.com/VimsLab/SODAWideNetPlusPlus.
A Benchmark Grocery Dataset of Realworld Point Clouds From Single View
Feb 12, 2024Fine-grained grocery object recognition is an important computer vision problem with broad applications in automatic checkout, in-store robotic navigation, and assistive technologies for the visually impaired. Existing datasets on groceries are mainly 2D images. Models trained on these datasets are limited to learning features from the regular 2D grids. While portable 3D sensors such as Kinect were commonly available for mobile phones, sensors such as LiDAR and TrueDepth, have recently been integrated into mobile phones. Despite the availability of mobile 3D sensors, there are currently no dedicated real-world large-scale benchmark 3D datasets for grocery. In addition, existing 3D datasets lack fine-grained grocery categories and have limited training samples. Furthermore, collecting data by going around the object versus the traditional photo capture makes data collection cumbersome. Thus, we introduce a large-scale grocery dataset called 3DGrocery100. It constitutes 100 classes, with a total of 87,898 3D point clouds created from 10,755 RGB-D single-view images. We benchmark our dataset on six recent state-of-the-art 3D point cloud classification models. Additionally, we also benchmark the dataset on few-shot and continual learning point cloud classification tasks. Project Page: https://bigdatavision.org/3DGrocery100/.
Improving Normalization with the James-Stein Estimator
Dec 01, 2023



Stein's paradox holds considerable sway in high-dimensional statistics, highlighting that the sample mean, traditionally considered the de facto estimator, might not be the most efficacious in higher dimensions. To address this, the James-Stein estimator proposes an enhancement by steering the sample means toward a more centralized mean vector. In this paper, first, we establish that normalization layers in deep learning use inadmissible estimators for mean and variance. Next, we introduce a novel method to employ the James-Stein estimator to improve the estimation of mean and variance within normalization layers. We evaluate our method on different computer vision tasks: image classification, semantic segmentation, and 3D object classification. Through these evaluations, it is evident that our improved normalization layers consistently yield superior accuracy across all tasks without extra computational burden. Moreover, recognizing that a plethora of shrinkage estimators surpass the traditional estimator in performance, we study two other prominent shrinkage estimators: Ridge and LASSO. Additionally, we provide visual representations to intuitively demonstrate the impact of shrinkage on the estimated layer statistics. Finally, we study the effect of regularization and batch size on our modified batch normalization. The studies show that our method is less sensitive to batch size and regularization, improving accuracy under various setups.
SODAWideNet -- Salient Object Detection with an Attention augmented Wide Encoder Decoder network without ImageNet pre-training
Nov 09, 2023Developing a new Salient Object Detection (SOD) model involves selecting an ImageNet pre-trained backbone and creating novel feature refinement modules to use backbone features. However, adding new components to a pre-trained backbone needs retraining the whole network on the ImageNet dataset, which requires significant time. Hence, we explore developing a neural network from scratch directly trained on SOD without ImageNet pre-training. Such a formulation offers full autonomy to design task-specific components. To that end, we propose SODAWideNet, an encoder-decoder-style network for Salient Object Detection. We deviate from the commonly practiced paradigm of narrow and deep convolutional models to a wide and shallow architecture, resulting in a parameter-efficient deep neural network. To achieve a shallower network, we increase the receptive field from the beginning of the network using a combination of dilated convolutions and self-attention. Therefore, we propose Multi Receptive Field Feature Aggregation Module (MRFFAM) that efficiently obtains discriminative features from farther regions at higher resolutions using dilated convolutions. Next, we propose Multi-Scale Attention (MSA), which creates a feature pyramid and efficiently computes attention across multiple resolutions to extract global features from larger feature maps. Finally, we propose two variants, SODAWideNet-S (3.03M) and SODAWideNet (9.03M), that achieve competitive performance against state-of-the-art models on five datasets.
Sentence Attention Blocks for Answer Grounding
Sep 20, 2023



Answer grounding is the task of locating relevant visual evidence for the Visual Question Answering task. While a wide variety of attention methods have been introduced for this task, they suffer from the following three problems: designs that do not allow the usage of pre-trained networks and do not benefit from large data pre-training, custom designs that are not based on well-grounded previous designs, therefore limiting the learning power of the network, or complicated designs that make it challenging to re-implement or improve them. In this paper, we propose a novel architectural block, which we term Sentence Attention Block, to solve these problems. The proposed block re-calibrates channel-wise image feature-maps by explicitly modeling inter-dependencies between the image feature-maps and sentence embedding. We visually demonstrate how this block filters out irrelevant feature-maps channels based on sentence embedding. We start our design with a well-known attention method, and by making minor modifications, we improve the results to achieve state-of-the-art accuracy. The flexibility of our method makes it easy to use different pre-trained backbone networks, and its simplicity makes it easy to understand and be re-implemented. We demonstrate the effectiveness of our method on the TextVQA-X, VQS, VQA-X, and VizWiz-VQA-Grounding datasets. We perform multiple ablation studies to show the effectiveness of our design choices.
Empowering Visually Impaired Individuals: A Novel Use of Apple Live Photos and Android Motion Photos
Sep 14, 2023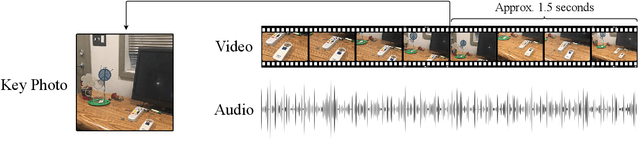



Numerous applications have been developed to assist visually impaired individuals that employ a machine learning unit to process visual input. However, a critical challenge with these applications is the sub-optimal quality of images captured by the users. Given the complexity of operating a camera for visually impaired individuals, we advocate for the use of Apple Live Photos and Android Motion Photos technologies. In this study, we introduce a straightforward methodology to evaluate and contrast the efficacy of Live/Motion Photos against traditional image-based approaches. Our findings reveal that both Live Photos and Motion Photos outperform single-frame images in common visual assisting tasks, specifically in object classification and VideoQA. We validate our results through extensive experiments on the ORBIT dataset, which consists of videos collected by visually impaired individuals. Furthermore, we conduct a series of ablation studies to delve deeper into the impact of deblurring and longer temporal crops.
Local Neighborhood Features for 3D Classification
Dec 09, 2022



With advances in deep learning model training strategies, the training of Point cloud classification methods is significantly improving. For example, PointNeXt, which adopts prominent training techniques and InvResNet layers into PointNet++, achieves over 7% improvement on the real-world ScanObjectNN dataset. However, most of these models use point coordinates features of neighborhood points mapped to higher dimensional space while ignoring the neighborhood point features computed before feeding to the network layers. In this paper, we revisit the PointNeXt model to study the usage and benefit of such neighborhood point features. We train and evaluate PointNeXt on ModelNet40 (synthetic), ScanObjectNN (real-world), and a recent large-scale, real-world grocery dataset, i.e., 3DGrocery100. In addition, we provide an additional inference strategy of weight averaging the top two checkpoints of PointNeXt to improve classification accuracy. Together with the abovementioned ideas, we gain 0.5%, 1%, 4.8%, 3.4%, and 1.6% overall accuracy on the PointNeXt model with real-world datasets, ScanObjectNN (hardest variant), 3DGrocery100's Apple10, Fruits, Vegetables, and Packages subsets, respectively. We also achieve a comparable 0.2% accuracy gain on ModelNet40.
Semantic Segmentation using Neural Ordinary Differential Equations
Sep 18, 2022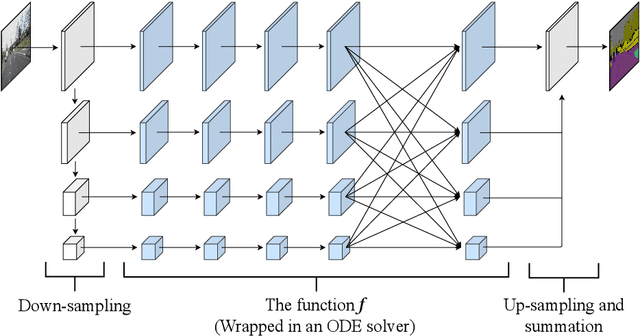
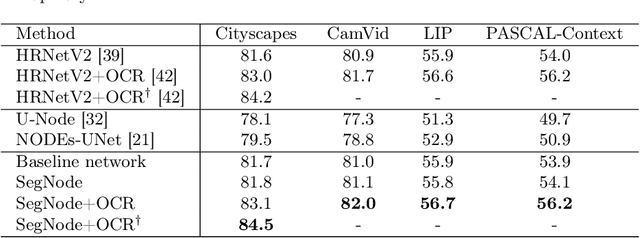

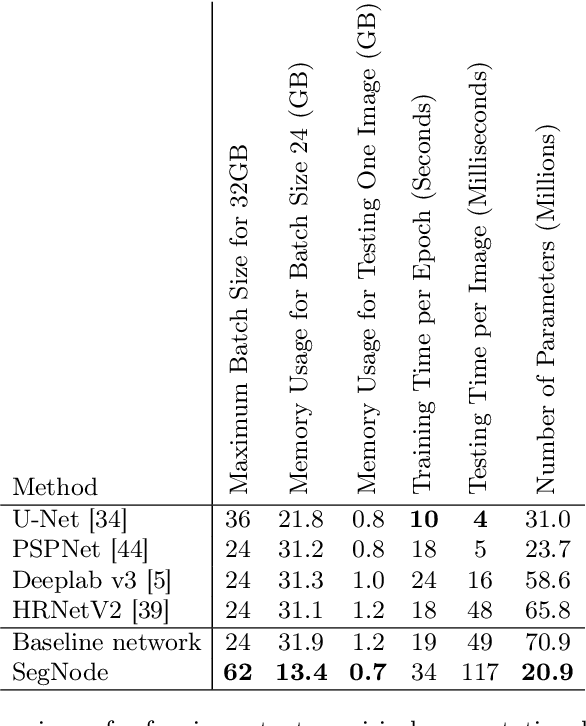
The idea of neural Ordinary Differential Equations (ODE) is to approximate the derivative of a function (data model) instead of the function itself. In residual networks, instead of having a discrete sequence of hidden layers, the derivative of the continuous dynamics of hidden state can be parameterized by an ODE. It has been shown that this type of neural network is able to produce the same results as an equivalent residual network for image classification. In this paper, we design a novel neural ODE for the semantic segmentation task. We start by a baseline network that consists of residual modules, then we use the modules to build our neural ODE network. We show that our neural ODE is able to achieve the state-of-the-art results using 57% less memory for training, 42% less memory for testing, and 68% less number of parameters. We evaluate our model on the Cityscapes, CamVid, LIP, and PASCAL-Context datasets.
Learning Dense Stereo Matching for Digital Surface Models from Satellite Imagery
Dec 11, 2018

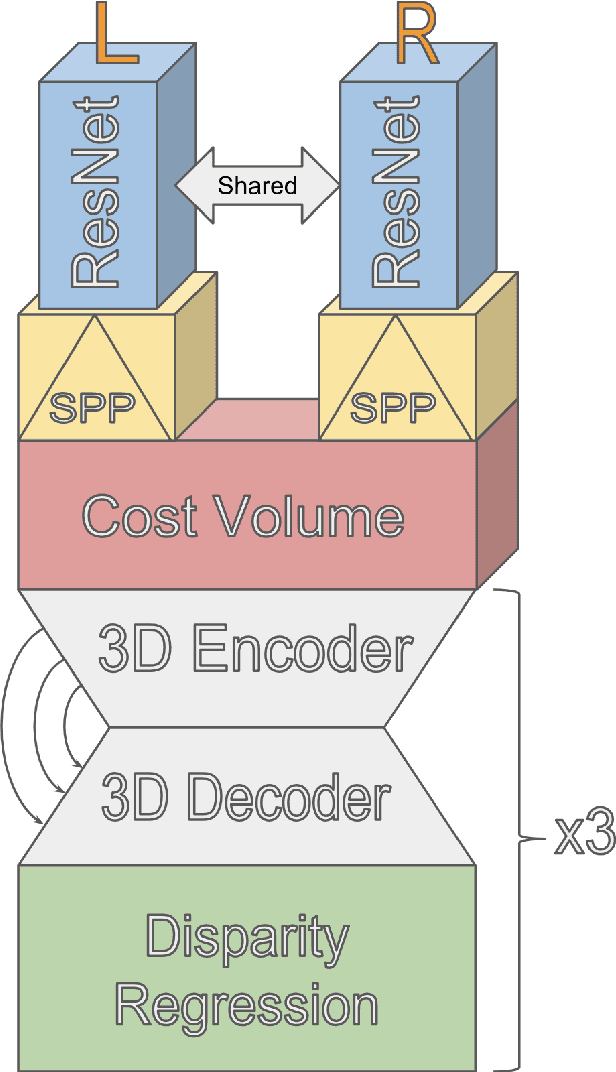

Digital Surface Model generation from satellite imagery is a difficult task that has been largely overlooked by the deep learning community. Stereo reconstruction techniques developed for terrestrial systems including self driving cars do not translate well to satellite imagery where image pairs vary considerably. In this work we present neural network tailored for Digital Surface Model generation, a ground truthing and training scheme which maximizes available hardware, and we present a comparison to existing methods. The resulting models are smooth, preserve boundaries, and enable further processing. This represents one of the first attempts at leveraging deep learning in this domain.
Robust Shape Registration using Fuzzy Correspondences
Feb 18, 2017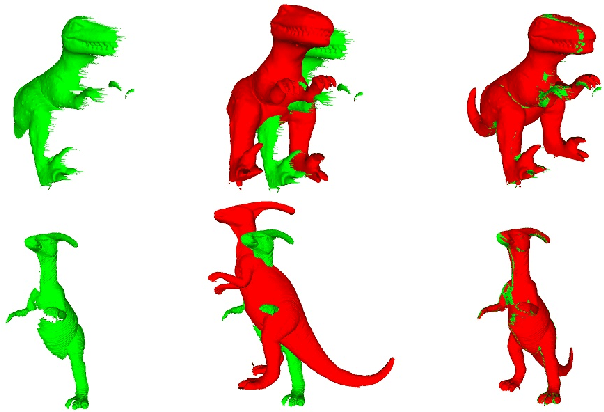
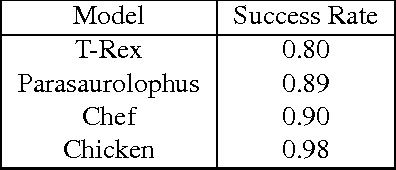
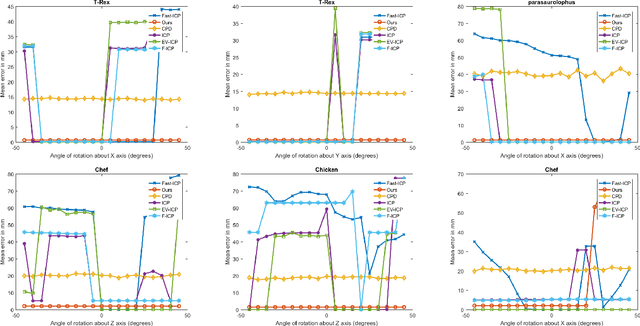
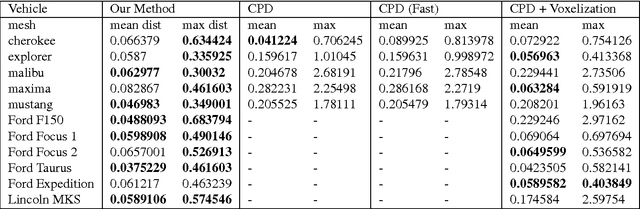
Shape registration is the process of aligning one 3D model to another. Most previous methods to align shapes with no known correspondences attempt to solve for both the transformation and correspondences iteratively. We present a shape registration approach that solves for the transformation using fuzzy correspondences to maximize the overlap between the given shape and the target shape. A coarse to fine approach with Levenberg-Marquardt method is used for optimization. Real and synthetic experiments show our approach is robust and outperforms other state of the art methods when point clouds are noisy, sparse, and have non-uniform density. Experiments show our method is more robust to initialization and can handle larger scale changes and rotation than other methods. We also show that the approach can be used for 2D-3D alignment via ray-point alignment.