 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Normalization with the James-Stein Estimator
Dec 01, 2023



Stein's paradox holds considerable sway in high-dimensional statistics, highlighting that the sample mean, traditionally considered the de facto estimator, might not be the most efficacious in higher dimensions. To address this, the James-Stein estimator proposes an enhancement by steering the sample means toward a more centralized mean vector. In this paper, first, we establish that normalization layers in deep learning use inadmissible estimators for mean and variance. Next, we introduce a novel method to employ the James-Stein estimator to improve the estimation of mean and variance within normalization layers. We evaluate our method on different computer vision tasks: image classification, semantic segmentation, and 3D object classification. Through these evaluations, it is evident that our improved normalization layers consistently yield superior accuracy across all tasks without extra computational burden. Moreover, recognizing that a plethora of shrinkage estimators surpass the traditional estimator in performance, we study two other prominent shrinkage estimators: Ridge and LASSO. Additionally, we provide visual representations to intuitively demonstrate the impact of shrinkage on the estimated layer statistics. Finally, we study the effect of regularization and batch size on our modified batch normalization. The studies show that our method is less sensitive to batch size and regularization, improving accuracy under various setups.
Sentence Attention Blocks for Answer Grounding
Sep 20, 2023



Answer grounding is the task of locating relevant visual evidence for the Visual Question Answering task. While a wide variety of attention methods have been introduced for this task, they suffer from the following three problems: designs that do not allow the usage of pre-trained networks and do not benefit from large data pre-training, custom designs that are not based on well-grounded previous designs, therefore limiting the learning power of the network, or complicated designs that make it challenging to re-implement or improve them. In this paper, we propose a novel architectural block, which we term Sentence Attention Block, to solve these problems. The proposed block re-calibrates channel-wise image feature-maps by explicitly modeling inter-dependencies between the image feature-maps and sentence embedding. We visually demonstrate how this block filters out irrelevant feature-maps channels based on sentence embedding. We start our design with a well-known attention method, and by making minor modifications, we improve the results to achieve state-of-the-art accuracy. The flexibility of our method makes it easy to use different pre-trained backbone networks, and its simplicity makes it easy to understand and be re-implemented. We demonstrate the effectiveness of our method on the TextVQA-X, VQS, VQA-X, and VizWiz-VQA-Grounding datasets. We perform multiple ablation studies to show the effectiveness of our design choices.
Empowering Visually Impaired Individuals: A Novel Use of Apple Live Photos and Android Motion Photos
Sep 14, 2023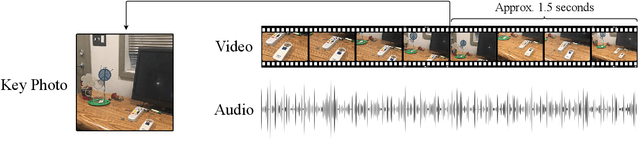



Numerous applications have been developed to assist visually impaired individuals that employ a machine learning unit to process visual input. However, a critical challenge with these applications is the sub-optimal quality of images captured by the users. Given the complexity of operating a camera for visually impaired individuals, we advocate for the use of Apple Live Photos and Android Motion Photos technologies. In this study, we introduce a straightforward methodology to evaluate and contrast the efficacy of Live/Motion Photos against traditional image-based approaches. Our findings reveal that both Live Photos and Motion Photos outperform single-frame images in common visual assisting tasks, specifically in object classification and VideoQA. We validate our results through extensive experiments on the ORBIT dataset, which consists of videos collected by visually impaired individuals. Furthermore, we conduct a series of ablation studies to delve deeper into the impact of deblurring and longer temporal crops.
Semantic Segmentation using Neural Ordinary Differential Equations
Sep 18, 2022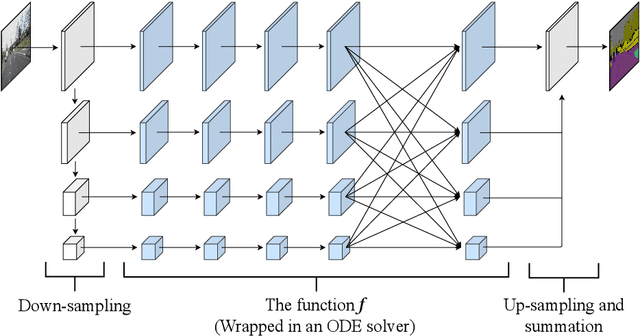
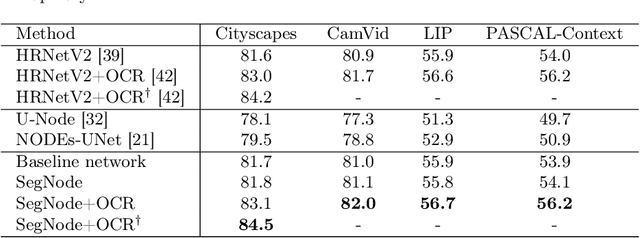

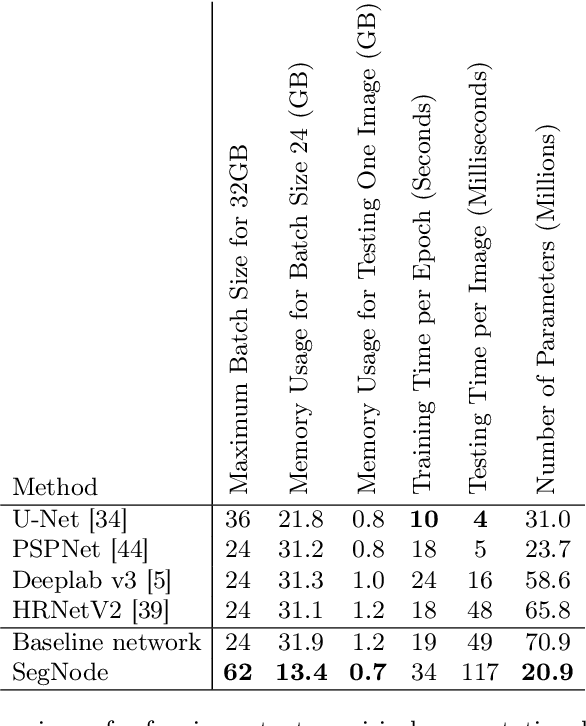
The idea of neural Ordinary Differential Equations (ODE) is to approximate the derivative of a function (data model) instead of the function itself. In residual networks, instead of having a discrete sequence of hidden layers, the derivative of the continuous dynamics of hidden state can be parameterized by an ODE. It has been shown that this type of neural network is able to produce the same results as an equivalent residual network for image classification. In this paper, we design a novel neural ODE for the semantic segmentation task. We start by a baseline network that consists of residual modules, then we use the modules to build our neural ODE network. We show that our neural ODE is able to achieve the state-of-the-art results using 57% less memory for training, 42% less memory for testing, and 68% less number of parameters. We evaluate our model on the Cityscapes, CamVid, LIP, and PASCAL-Context datasets.