 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMahalanobis k-NN: A Statistical Lens for Robust Point-Cloud Registrations
Sep 10, 2024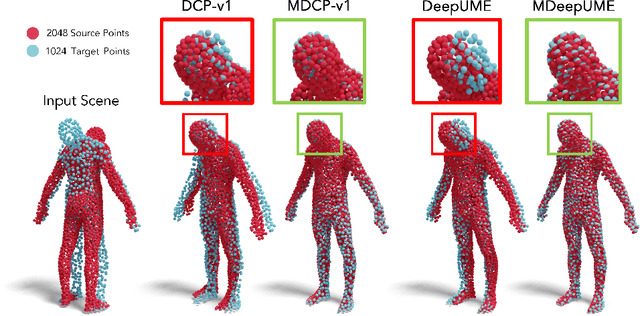
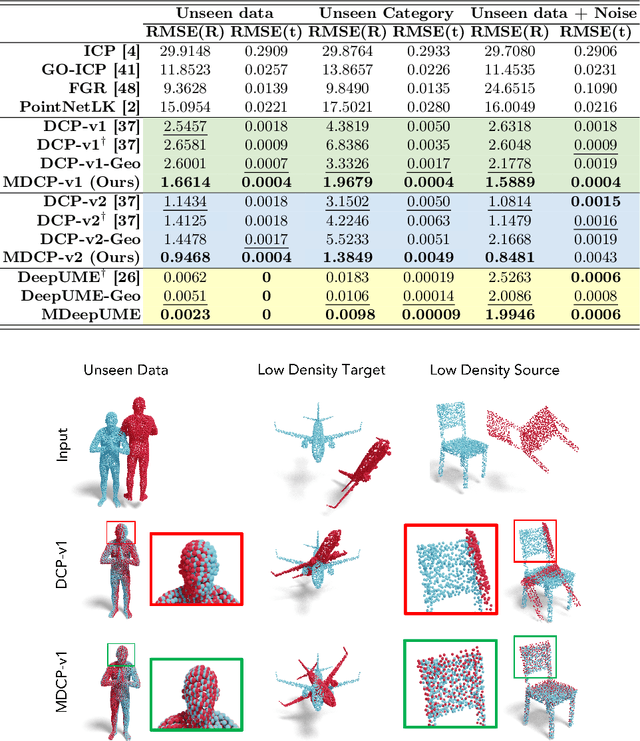

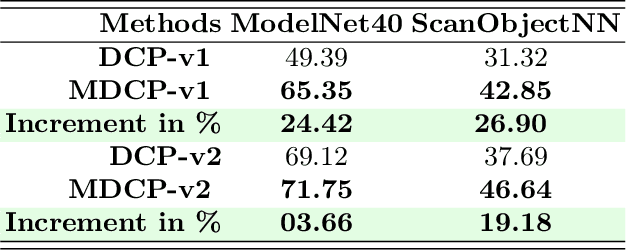
In this paper, we discuss Mahalanobis k-NN: a statistical lens designed to address the challenges of feature matching in learning-based point cloud registration when confronted with an arbitrary density of point clouds, either in the source or target point cloud. We tackle this by adopting Mahalanobis k-NN's inherent property to capture the distribution of the local neighborhood and surficial geometry. Our method can be seamlessly integrated into any local-graph-based point cloud analysis method. In this paper, we focus on two distinct methodologies: Deep Closest Point (DCP) and Deep Universal Manifold Embedding (DeepUME). Our extensive benchmarking on the ModelNet40 and Faust datasets highlights the efficacy of the proposed method in point cloud registration tasks. Moreover, we establish for the first time that the features acquired through point cloud registration inherently can possess discriminative capabilities. This is evident by a substantial improvement of about 20\% in the average accuracy observed in the point cloud few-shot classification task benchmarked on ModelNet40 and ScanObjectNN. The code is publicly available at https://github.com/TejasAnvekar/Mahalanobis-k-NN
EDADepth: Enhanced Data Augmentation for Monocular Depth Estimation
Sep 10, 2024Due to their text-to-image synthesis feature, diffusion models have recently seen a rise in visual perception tasks, such as depth estimation. The lack of good-quality datasets makes the extraction of a fine-grain semantic context challenging for the diffusion models. The semantic context with fewer details further worsens the process of creating effective text embeddings that will be used as input for diffusion models. In this paper, we propose a novel EDADepth, an enhanced data augmentation method to estimate monocular depth without using additional training data. We use Swin2SR, a super-resolution model, to enhance the quality of input images. We employ the BEiT pre-trained semantic segmentation model for better extraction of text embeddings. We introduce BLIP-2 tokenizer to generate tokens from these text embeddings. The novelty of our approach is the introduction of Swin2SR, the BEiT model, and the BLIP-2 tokenizer in the diffusion-based pipeline for the monocular depth estimation. Our model achieves state-of-the-art results (SOTA) on the {\delta}3 metric on NYUv2 and KITTI datasets. It also achieves results comparable to those of the SOTA models in the RMSE and REL metrics. Finally, we also show improvements in the visualization of the estimated depth compared to the SOTA diffusion-based monocular depth estimation models. Code: https://github.com/edadepthmde/EDADepth_ICMLA.
A Benchmark Grocery Dataset of Realworld Point Clouds From Single View
Feb 12, 2024Fine-grained grocery object recognition is an important computer vision problem with broad applications in automatic checkout, in-store robotic navigation, and assistive technologies for the visually impaired. Existing datasets on groceries are mainly 2D images. Models trained on these datasets are limited to learning features from the regular 2D grids. While portable 3D sensors such as Kinect were commonly available for mobile phones, sensors such as LiDAR and TrueDepth, have recently been integrated into mobile phones. Despite the availability of mobile 3D sensors, there are currently no dedicated real-world large-scale benchmark 3D datasets for grocery. In addition, existing 3D datasets lack fine-grained grocery categories and have limited training samples. Furthermore, collecting data by going around the object versus the traditional photo capture makes data collection cumbersome. Thus, we introduce a large-scale grocery dataset called 3DGrocery100. It constitutes 100 classes, with a total of 87,898 3D point clouds created from 10,755 RGB-D single-view images. We benchmark our dataset on six recent state-of-the-art 3D point cloud classification models. Additionally, we also benchmark the dataset on few-shot and continual learning point cloud classification tasks. Project Page: https://bigdatavision.org/3DGrocery100/.
Local Neighborhood Features for 3D Classification
Dec 09, 2022



With advances in deep learning model training strategies, the training of Point cloud classification methods is significantly improving. For example, PointNeXt, which adopts prominent training techniques and InvResNet layers into PointNet++, achieves over 7% improvement on the real-world ScanObjectNN dataset. However, most of these models use point coordinates features of neighborhood points mapped to higher dimensional space while ignoring the neighborhood point features computed before feeding to the network layers. In this paper, we revisit the PointNeXt model to study the usage and benefit of such neighborhood point features. We train and evaluate PointNeXt on ModelNet40 (synthetic), ScanObjectNN (real-world), and a recent large-scale, real-world grocery dataset, i.e., 3DGrocery100. In addition, we provide an additional inference strategy of weight averaging the top two checkpoints of PointNeXt to improve classification accuracy. Together with the abovementioned ideas, we gain 0.5%, 1%, 4.8%, 3.4%, and 1.6% overall accuracy on the PointNeXt model with real-world datasets, ScanObjectNN (hardest variant), 3DGrocery100's Apple10, Fruits, Vegetables, and Packages subsets, respectively. We also achieve a comparable 0.2% accuracy gain on ModelNet40.