 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal MPPI and Active Inference for Reactive Task and Motion Planning
Dec 04, 2023Task and Motion Planning (TAMP) has made strides in complex manipulation tasks, yet the execution robustness of the planned solutions remains overlooked. In this work, we propose a method for reactive TAMP to cope with runtime uncertainties and disturbances. We combine an Active Inference planner (AIP) for adaptive high-level action selection and a novel Multi-Modal Model Predictive Path Integral controller (M3P2I) for low-level control. This results in a scheme that simultaneously adapts both high-level actions and low-level motions. The AIP generates alternative symbolic plans, each linked to a cost function for M3P2I. The latter employs a physics simulator for diverse trajectory rollouts, deriving optimal control by weighing the different samples according to their cost. This idea enables blending different robot skills for fluid and reactive plan execution, accommodating plan adjustments at both the high and low levels to cope, for instance, with dynamic obstacles or disturbances that invalidate the current plan. We have tested our approach in simulations and real-world scenarios.
Sampling-based Model Predictive Control Leveraging Parallelizable Physics Simulations
Jul 18, 2023We present a method for sampling-based model predictive control that makes use of a generic physics simulator as the dynamical model. In particular, we propose a Model Predictive Path Integral controller (MPPI), that uses the GPU-parallelizable IsaacGym simulator to compute the forward dynamics of a problem. By doing so, we eliminate the need for manual encoding of robot dynamics and interactions among objects and allow one to effortlessly solve complex navigation and contact-rich tasks. Since no explicit dynamic modeling is required, the method is easily extendable to different objects and robots. We demonstrate the effectiveness of this method in several simulated and real-world settings, among which mobile navigation with collision avoidance, non-prehensile manipulation, and whole-body control for high-dimensional configuration spaces. This method is a powerful and accessible tool to solve a large variety of contact-rich motion planning tasks.
Local Planner Bench: Benchmarking for Local Motion Planning
Oct 12, 2022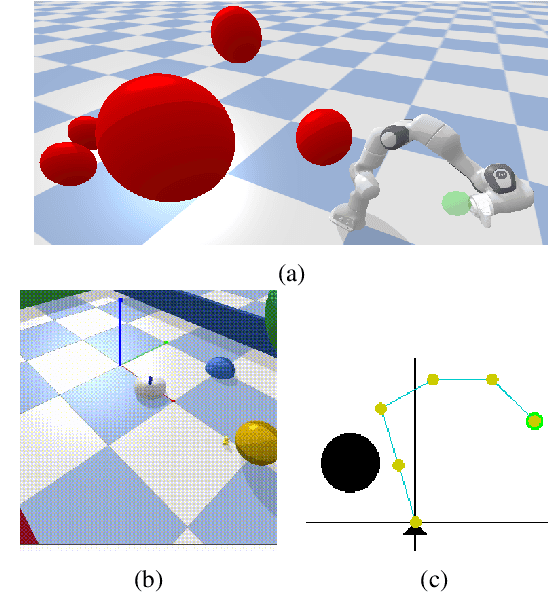
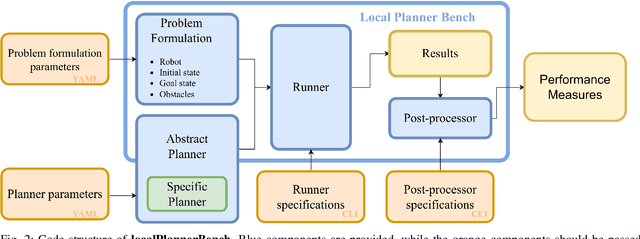
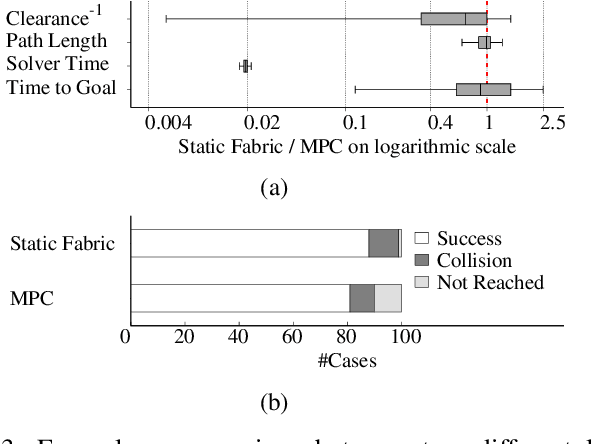

Local motion planning is a heavily researched topic in the field of robotics with many promising algorithms being published every year. However, it is difficult and time-consuming to compare different methods in the field. In this paper, we present localPlannerBench, a new benchmarking suite that allows quick and seamless comparison between local motion planning algorithms. The key focus of the project lies in the extensibility of the environment and the simulation cases. Out-of-the-box, localPlannerBench already supports many simulation cases ranging from a simple 2D point mass to full-fledged 3D 7DoF manipulators, and it is straightforward to add your own custom robot using a URDF file. A post-processor is built-in that can be extended with custom metrics and plots. To integrate your own motion planner, simply create a wrapper that derives from the provided base class. Ultimately we aim to improve the reproducibility of local motion planning algorithms and encourage standardized open-source comparison.
Improving Pedestrian Prediction Models with Self-Supervised Continual Learning
Feb 15, 2022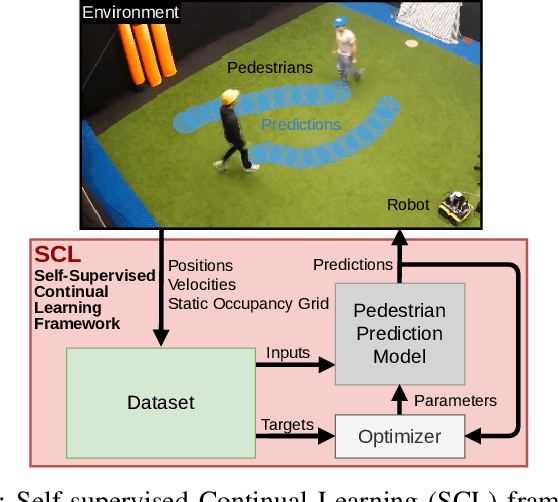
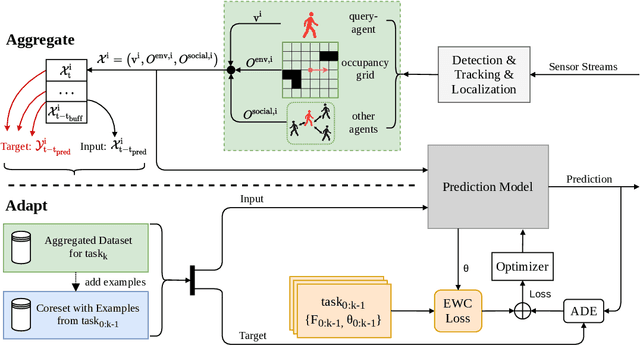
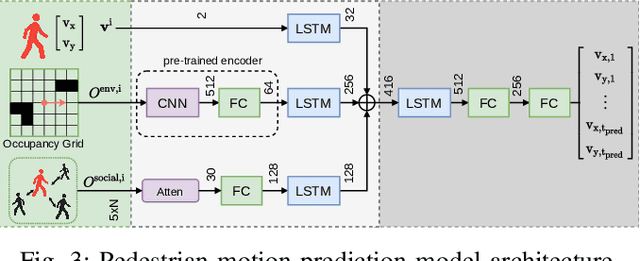
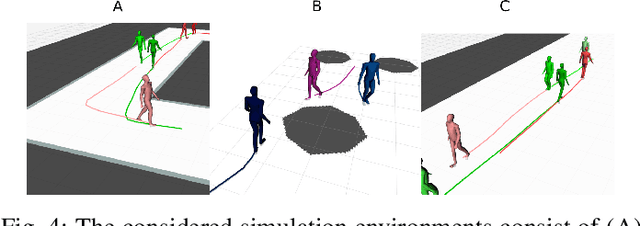
Autonomous mobile robots require accurate human motion predictions to safely and efficiently navigate among pedestrians, whose behavior may adapt to environmental changes. This paper introduces a self-supervised continual learning framework to improve data-driven pedestrian prediction models online across various scenarios continuously. In particular, we exploit online streams of pedestrian data, commonly available from the robot's detection and tracking pipeline, to refine the prediction model and its performance in unseen scenarios. To avoid the forgetting of previously learned concepts, a problem known as catastrophic forgetting, our framework includes a regularization loss to penalize changes of model parameters that are important for previous scenarios and retrains on a set of previous examples to retain past knowledge. Experimental results on real and simulation data show that our approach can improve prediction performance in unseen scenarios while retaining knowledge from seen scenarios when compared to naively training the prediction model online.