 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaZeroES: Direct score maximization outperforms planning loss minimization
Jun 12, 2024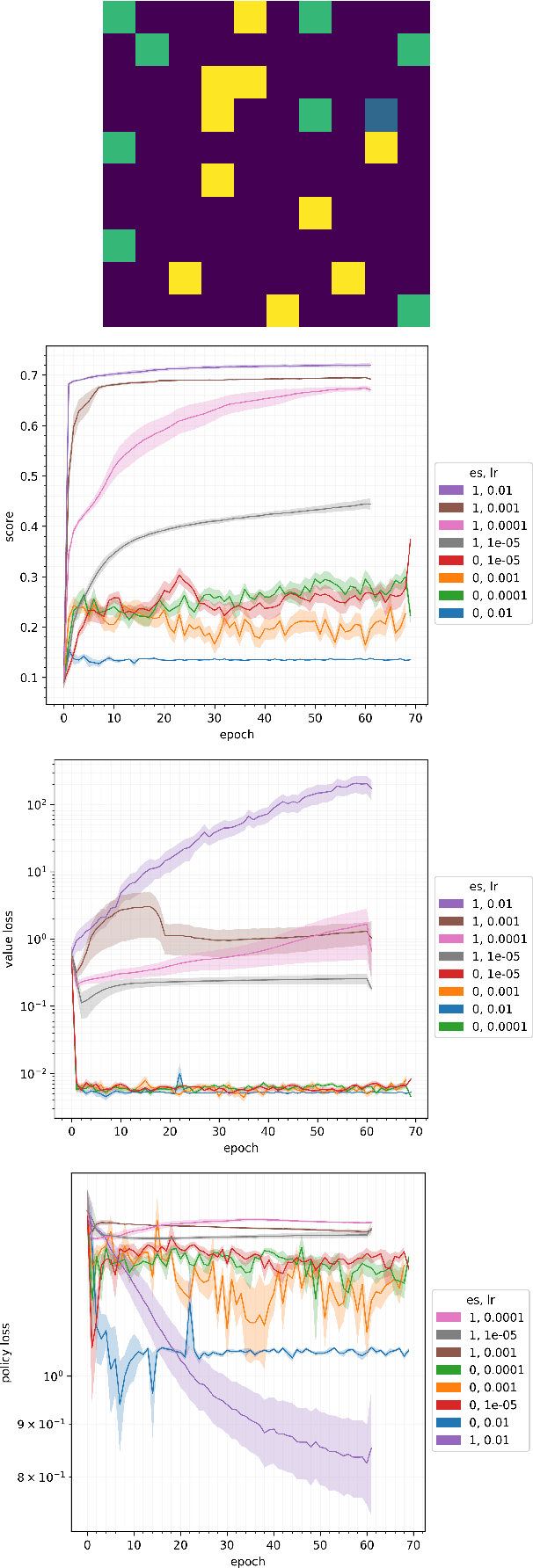
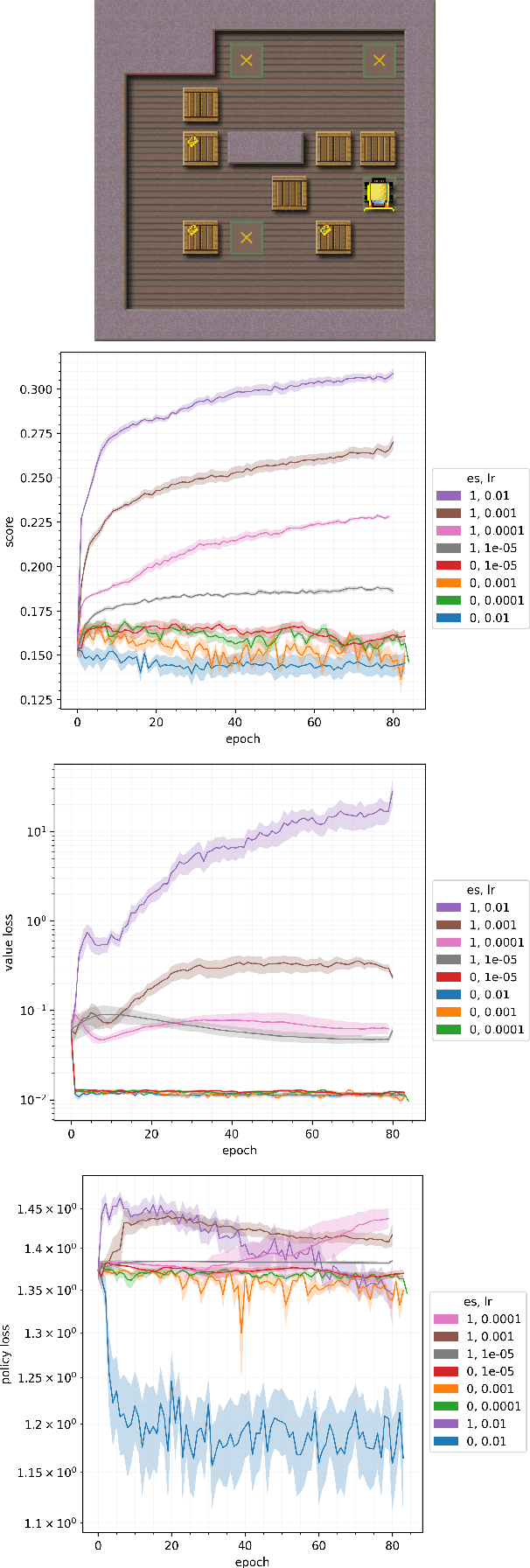
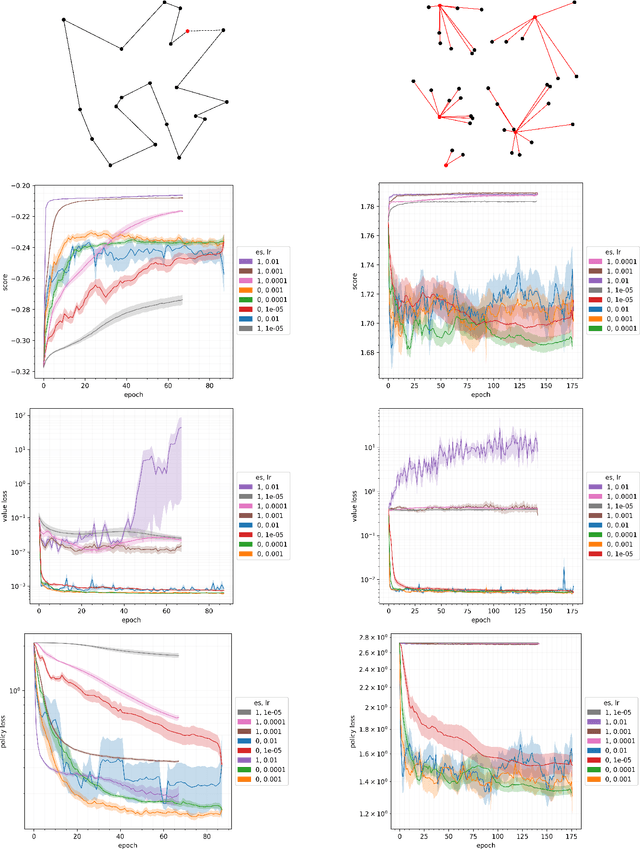
Planning at execution time has been shown to dramatically improve performance for agents in both single-agent and multi-agent settings. A well-known family of approaches to planning at execution time are AlphaZero and its variants, which use Monte Carlo Tree Search together with a neural network that guides the search by predicting state values and action probabilities. AlphaZero trains these networks by minimizing a planning loss that makes the value prediction match the episode return, and the policy prediction at the root of the search tree match the output of the full tree expansion. AlphaZero has been applied to both single-agent environments (such as Sokoban) and multi-agent environments (such as chess and Go) with great success. In this paper, we explore an intriguing question: In single-agent environments, can we outperform AlphaZero by directly maximizing the episode score instead of minimizing this planning loss, while leaving the MCTS algorithm and neural architecture unchanged? To directly maximize the episode score, we use evolution strategies, a family of algorithms for zeroth-order blackbox optimization. Our experiments indicate that, across multiple environments, directly maximizing the episode score outperforms minimizing the planning loss.
AERIAL-CORE: AI-Powered Aerial Robots for Inspection and Maintenance of Electrical Power Infrastructures
Jan 04, 2024Large-scale infrastructures are prone to deterioration due to age, environmental influences, and heavy usage. Ensuring their safety through regular inspections and maintenance is crucial to prevent incidents that can significantly affect public safety and the environment. This is especially pertinent in the context of electrical power networks, which, while essential for energy provision, can also be sources of forest fires. Intelligent drones have the potential to revolutionize inspection and maintenance, eliminating the risks for human operators, increasing productivity, reducing inspection time, and improving data collection quality. However, most of the current methods and technologies in aerial robotics have been trialed primarily in indoor testbeds or outdoor settings under strictly controlled conditions, always within the line of sight of human operators. Additionally, these methods and technologies have typically been evaluated in isolation, lacking comprehensive integration. This paper introduces the first autonomous system that combines various innovative aerial robots. This system is designed for extended-range inspections beyond the visual line of sight, features aerial manipulators for maintenance tasks, and includes support mechanisms for human operators working at elevated heights. The paper further discusses the successful validation of this system on numerous electrical power lines, with aerial robots executing flights over 10 kilometers away from their ground control stations.
Planning in the imagination: High-level planning on learned abstract search spaces
Aug 16, 2023We propose a new method, called PiZero, that gives an agent the ability to plan in an abstract search space of its own creation that is completely decoupled from the real environment. Unlike prior approaches, this enables the agent to perform high-level planning at arbitrary timescales and reason in terms of compound or temporally-extended actions, which can be useful in environments where large numbers of base-level micro-actions are needed to perform relevant macro-actions. In addition, our method is more general than comparable prior methods because it handles settings with continuous action spaces and partial observability. We evaluate our method on multiple domains, including navigation tasks and Sokoban. Experimentally, it outperforms comparable prior methods without assuming access to an environment simulator.
Computing equilibria by minimizing exploitability with best-response ensembles
Jan 20, 2023In this paper, we study the problem of computing an approximate Nash equilibrium of a continuous game. Such games naturally model many situations involving space, time, money, and other fine-grained resources or quantities. The standard measure of the closeness of a strategy profile to Nash equilibrium is exploitability, which measures how much utility players can gain from changing their strategy unilaterally. We introduce a new equilibrium-finding method that minimizes an approximation of the exploitability. This approximation employs a best-response ensemble for each player that maintains multiple candidate best responses for that player. In each iteration, the best-performing element of each ensemble is used in a gradient-based scheme to update the current strategy profile. The strategy profile and best-response ensembles are simultaneously trained to minimize and maximize the approximate exploitability, respectively. Experiments on a suite of benchmark games show that it outperforms previous methods.
Finding mixed-strategy equilibria of continuous-action games without gradients using randomized policy networks
Nov 29, 2022We study the problem of computing an approximate Nash equilibrium of continuous-action game without access to gradients. Such game access is common in reinforcement learning settings, where the environment is typically treated as a black box. To tackle this problem, we apply zeroth-order optimization techniques that combine smoothed gradient estimators with equilibrium-finding dynamics. We model players' strategies using artificial neural networks. In particular, we use randomized policy networks to model mixed strategies. These take noise in addition to an observation as input and can flexibly represent arbitrary observation-dependent, continuous-action distributions. Being able to model such mixed strategies is crucial for tackling continuous-action games that lack pure-strategy equilibria. We evaluate the performance of our method using an approximation of the Nash convergence metric from game theory, which measures how much players can benefit from unilaterally changing their strategy. We apply our method to continuous Colonel Blotto games, single-item and multi-item auctions, and a visibility game. The experiments show that our method can quickly find high-quality approximate equilibria. Furthermore, they show that the dimensionality of the input noise is crucial for performance. To our knowledge, this paper is the first to solve general continuous-action games with unrestricted mixed strategies and without any gradient information.
Efficient exploration of zero-sum stochastic games
Feb 24, 2020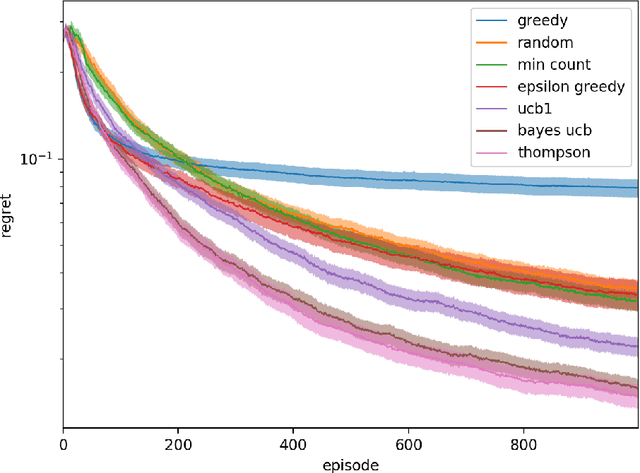
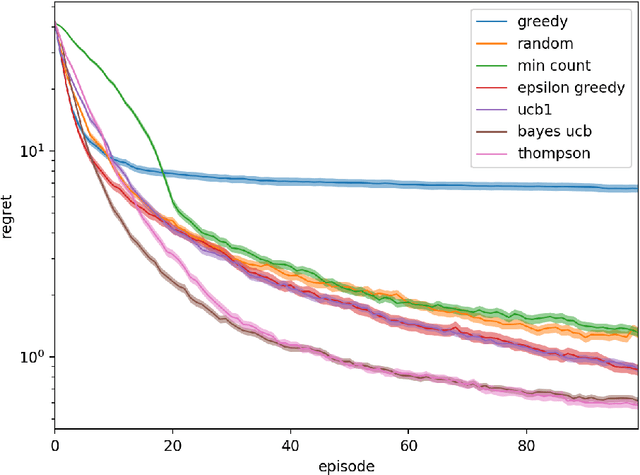
We investigate the increasingly important and common game-solving setting where we do not have an explicit description of the game but only oracle access to it through gameplay, such as in financial or military simulations and computer games. During a limited-duration learning phase, the algorithm can control the actions of both players in order to try to learn the game and how to play it well. After that, the algorithm has to produce a strategy that has low exploitability. Our motivation is to quickly learn strategies that have low exploitability in situations where evaluating the payoffs of a queried strategy profile is costly. For the stochastic game setting, we propose using the distribution of state-action value functions induced by a belief distribution over possible environments. We compare the performance of various exploration strategies for this task, including generalizations of Thompson sampling and Bayes-UCB to this new setting. These two consistently outperform other strategies.