 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning elementary structures for 3D shape generation and matching
Aug 14, 2019

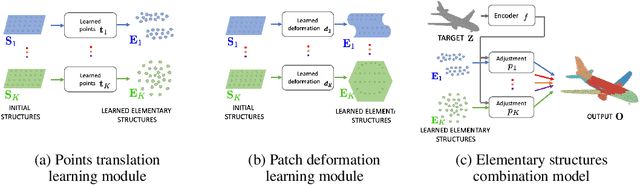

We propose to represent shapes as the deformation and combination of learnable elementary 3D structures, which are primitives resulting from training over a collection of shape. We demonstrate that the learned elementary 3D structures lead to clear improvements in 3D shape generation and matching. More precisely, we present two complementary approaches for learning elementary structures: (i) patch deformation learning and (ii) point translation learning. Both approaches can be extended to abstract structures of higher dimensions for improved results. We evaluate our method on two tasks: reconstructing ShapeNet objects and estimating dense correspondences between human scans (FAUST inter challenge). We show 16% improvement over surface deformation approaches for shape reconstruction and outperform FAUST inter challenge state of the art by 6%.
Unsupervised cycle-consistent deformation for shape matching
Jul 06, 2019


We propose a self-supervised approach to deep surface deformation. Given a pair of shapes, our algorithm directly predicts a parametric transformation from one shape to the other respecting correspondences. Our insight is to use cycle-consistency to define a notion of good correspondences in groups of objects and use it as a supervisory signal to train our network. Our method does not rely on a template, assume near isometric deformations or rely on point-correspondence supervision. We demonstrate the efficacy of our approach by using it to transfer segmentation across shapes. We show, on Shapenet, that our approach is competitive with comparable state-of-the-art methods when annotated training data is readily available, but outperforms them by a large margin in the few-shot segmentation scenario.
Photometric Mesh Optimization for Video-Aligned 3D Object Reconstruction
Mar 20, 2019


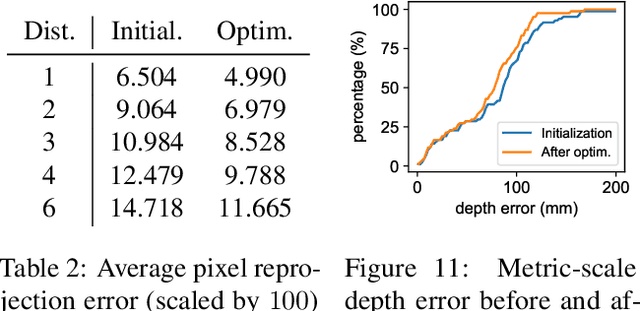
In this paper, we address the problem of 3D object mesh reconstruction from RGB videos. Our approach combines the best of multi-view geometric and data-driven methods for 3D reconstruction by optimizing object meshes for multi-view photometric consistency while constraining mesh deformations with a shape prior. We pose this as a piecewise image alignment problem for each mesh face projection. Our approach allows us to update shape parameters from the photometric error without any depth or mask information. Moreover, we show how to avoid a degeneracy of zero photometric gradients via rasterizing from a virtual viewpoint. We demonstrate 3D object mesh reconstruction results from both synthetic and real-world videos with our photometric mesh optimization, which is unachievable with either na\"ive mesh generation networks or traditional pipelines of surface reconstruction without heavy manual post-processing.
3D-CODED : 3D Correspondences by Deep Deformation
Jul 27, 2018

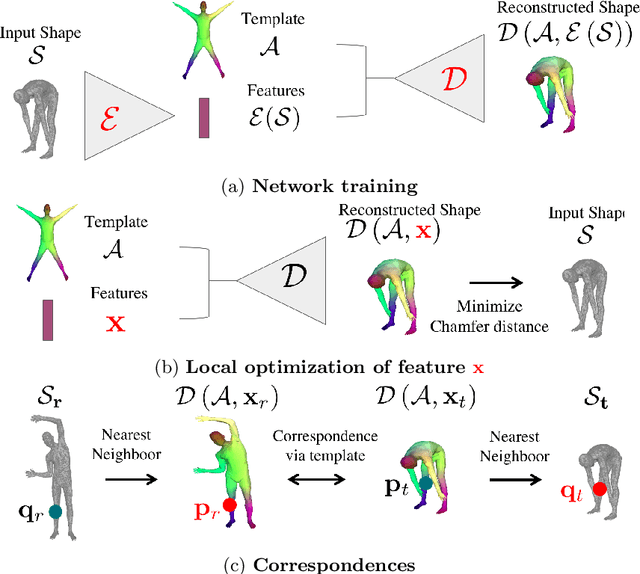

We present a new deep learning approach for matching deformable shapes by introducing {\it Shape Deformation Networks} which jointly encode 3D shapes and correspondences. This is achieved by factoring the surface representation into (i) a template, that parameterizes the surface, and (ii) a learnt global feature vector that parameterizes the transformation of the template into the input surface. By predicting this feature for a new shape, we implicitly predict correspondences between this shape and the template. We show that these correspondences can be improved by an additional step which improves the shape feature by minimizing the Chamfer distance between the input and transformed template. We demonstrate that our simple approach improves on state-of-the-art results on the difficult FAUST-inter challenge, with an average correspondence error of 2.88cm. We show, on the TOSCA dataset, that our method is robust to many types of perturbations, and generalizes to non-human shapes. This robustness allows it to perform well on real unclean, meshes from the the SCAPE dataset.
AtlasNet: A Papier-Mâché Approach to Learning 3D Surface Generation
Jul 20, 2018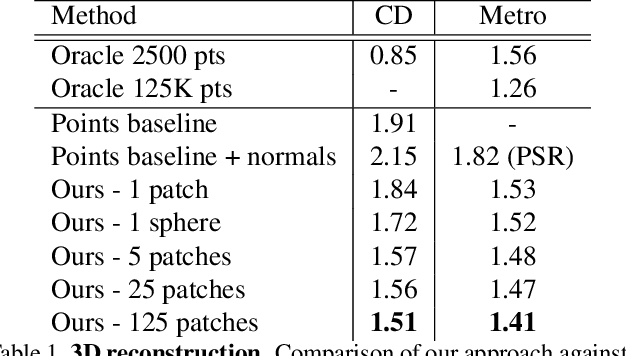


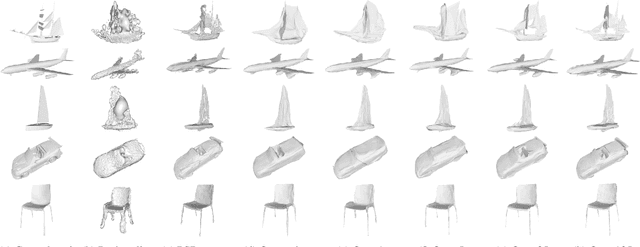
We introduce a method for learning to generate the surface of 3D shapes. Our approach represents a 3D shape as a collection of parametric surface elements and, in contrast to methods generating voxel grids or point clouds, naturally infers a surface representation of the shape. Beyond its novelty, our new shape generation framework, AtlasNet, comes with significant advantages, such as improved precision and generalization capabilities, and the possibility to generate a shape of arbitrary resolution without memory issues. We demonstrate these benefits and compare to strong baselines on the ShapeNet benchmark for two applications: (i) auto-encoding shapes, and (ii) single-view reconstruction from a still image. We also provide results showing its potential for other applications, such as morphing, parametrization, super-resolution, matching, and co-segmentation.