 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriSUD: A Dependency Treebank Collection for Evaluating Models on African Languages
Jun 10, 2026Despite their linguistic diversity and global significance, African languages remain underrepresented in research and resources to support NLP. We aim to bridge this gap by introducing AfriSUD, the first large-scale collection of syntactically annotated treebanks for nine diverse African languages spanning major language families and regions across Sub-Saharan Africa. Using the Surface-Syntactic Universal Dependencies (SUD) framework, our community-led effort provides high-quality, native-speaker verified data that capture typological key features such as agglutination and tone. We evaluate a range of models on AfriSUD for part-of-speech tagging and dependency parsing including non-transformer baselines, multilingual pretrained encoders, and LLMs. Our results reveal a significant syntax gap, where models still show clear limitations across the nine languages, suggesting that existing architectures may not fully capture the structural diversity of African-language syntax.
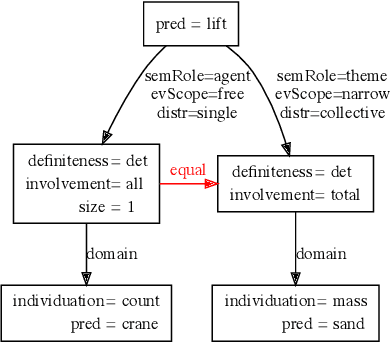
Coconstructions in spoken data: UD annotation guidelines and first results
Mar 30, 2026The paper proposes annotation guidelines for syntactic dependencies that span across speaker turns - including collaborative coconstructions proper, wh-question answers, and backchannels - in spoken language treebanks within the Universal Dependencies framework. Two representations are proposed: a speaker-based representation following the segmentation into speech turns, and a dependency-based representation with dependencies across speech turns. New propositions are also put forward to distinguish between reformulations and repairs, and to promote elements in unfinished phrases.
How much of UCCA can be predicted from AMR?
Jul 25, 2022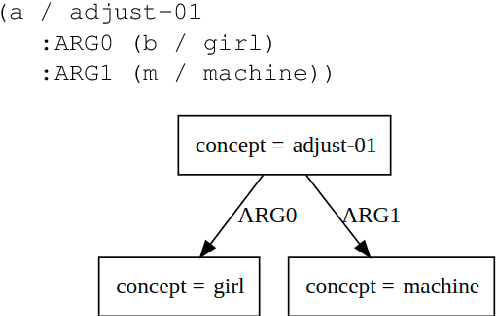
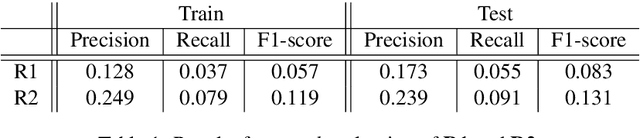


In this paper, we consider two of the currently popular semantic frameworks: Abstract Meaning Representation (AMR)a more abstract framework, and Universal Conceptual Cognitive Annotation (UCCA)-an anchored framework. We use a corpus-based approach to build two graph rewriting systems, a deterministic and a non-deterministic one, from the former to the latter framework. We present their evaluation and a number of ambiguities that we discovered while building our rules. Finally, we provide a discussion and some future work directions in relation to comparing semantic frameworks of different flavors.
Graph Querying for Semantic Annotations
Jul 25, 2022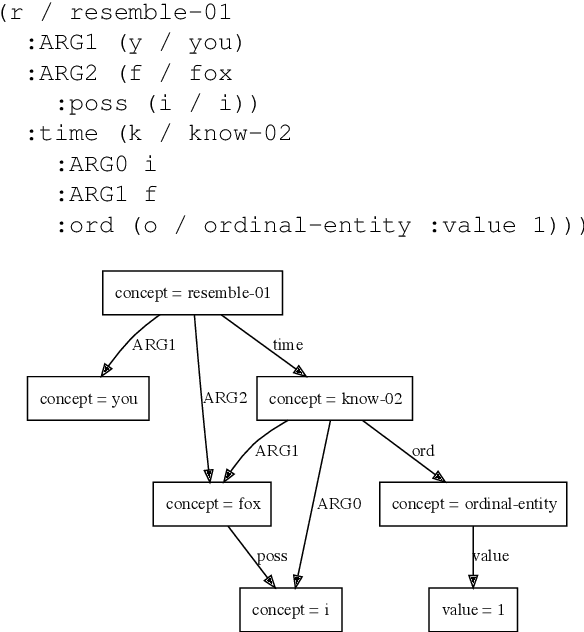
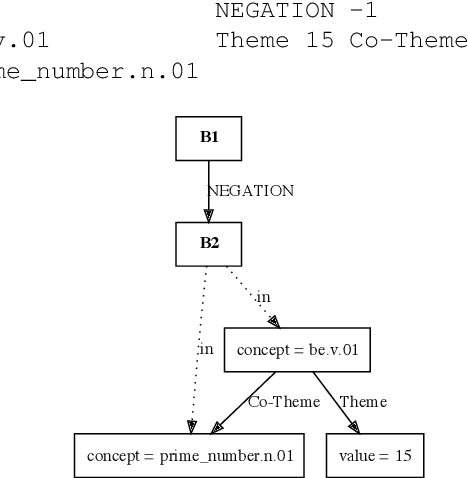
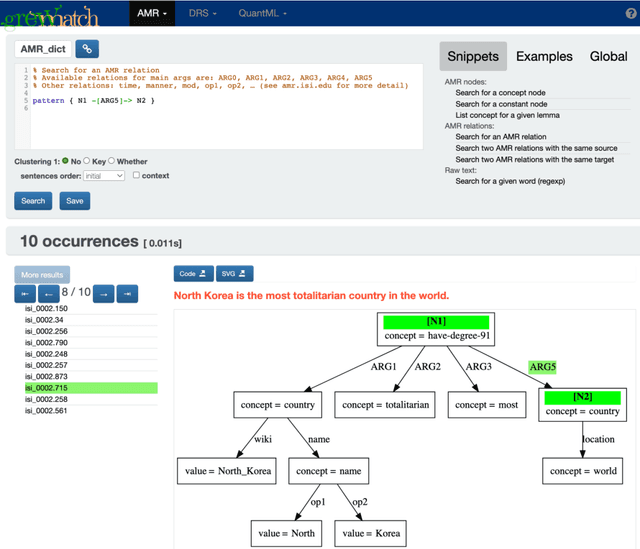
This paper presents how the online tool GREW-MATCH can be used to make queries and visualise data from existing semantically annotated corpora. A dedicated syntax is available to construct simple to complex queries and execute them against a corpus. Such queries give transverse views of the annotated data, these views can help for checking the consistency of annotations in one corpus or across several corpora. GREW-MATCH can then be seen as an error mining tool: when inconsistencies are detected, it helps finding the sentences which should be fixed. Finally, GREW-MATCH can also be used as a side tool to assist annotation tasks helping to find annotation examples in existing corpora to be compared to the data to be annotated.
Non-simplifying Graph Rewriting Termination
Feb 26, 2013
So far, a very large amount of work in Natural Language Processing (NLP) rely on trees as the core mathematical structure to represent linguistic informations (e.g. in Chomsky's work). However, some linguistic phenomena do not cope properly with trees. In a former paper, we showed the benefit of encoding linguistic structures by graphs and of using graph rewriting rules to compute on those structures. Justified by some linguistic considerations, graph rewriting is characterized by two features: first, there is no node creation along computations and second, there are non-local edge modifications. Under these hypotheses, we show that uniform termination is undecidable and that non-uniform termination is decidable. We describe two termination techniques based on weights and we give complexity bound on the derivation length for these rewriting system.
* In Proceedings TERMGRAPH 2013, arXiv:1302.5997
Motifs de graphe pour le calcul de dépendances syntaxiques complètes
Nov 18, 2010
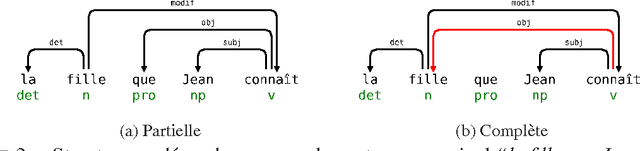
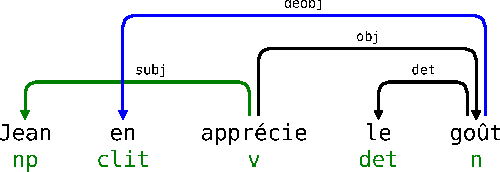
This article describes a method to build syntactical dependencies starting from the phrase structure parsing process. The goal is to obtain all the information needed for a detailled semantical analysis. Interaction Grammars are used for parsing; the saturation of polarities which is the core of this formalism can be mapped to dependency relation. Formally, graph patterns are used to express the set of constraints which control dependency creations.
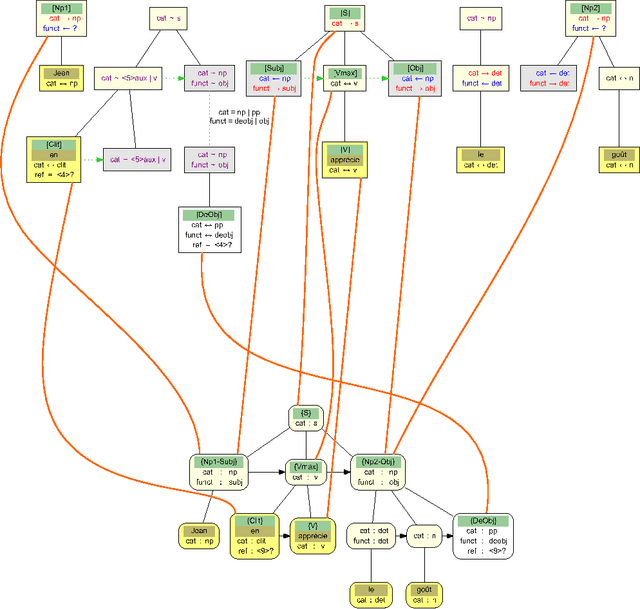
Analyse en dépendances à l'aide des grammaires d'interaction
Sep 18, 2009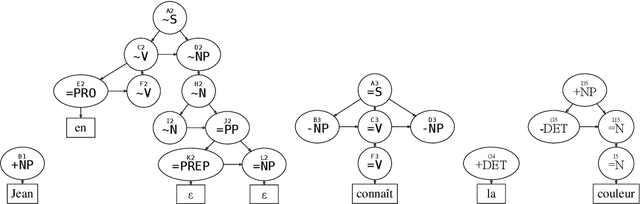
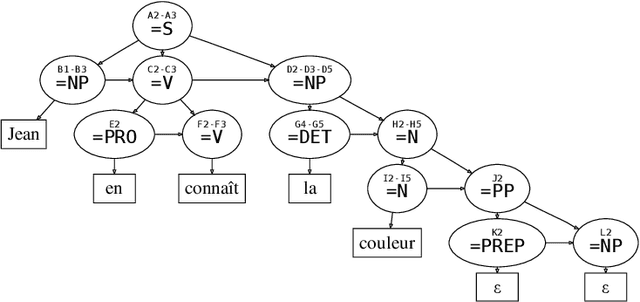


This article proposes a method to extract dependency structures from phrase-structure level parsing with Interaction Grammars. Interaction Grammars are a formalism which expresses interactions among words using a polarity system. Syntactical composition is led by the saturation of polarities. Interactions take place between constituents, but as grammars are lexicalized, these interactions can be translated at the level of words. Dependency relations are extracted from the parsing process: every dependency is the consequence of a polarity saturation. The dependency relations we obtain can be seen as a refinement of the usual dependency tree. Generally speaking, this work sheds new light on links between phrase structure and dependency parsing.