 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Deep Reinforcement Learning for Autonomous UAV Navigation and Exploration of Outdoor Environments
Dec 11, 2019



With the rapidly growing expansion in the use of UAVs, the ability to autonomously navigate in varying environments and weather conditions remains a highly desirable but as-of-yet unsolved challenge. In this work, we use Deep Reinforcement Learning to continuously improve the learning and understanding of a UAV agent while exploring a partially observable environment, which simulates the challenges faced in a real-life scenario. Our innovative approach uses a double state-input strategy that combines the acquired knowledge from the raw image and a map containing positional information. This positional data aids the network understanding of where the UAV has been and how far it is from the target position, while the feature map from the current scene highlights cluttered areas that are to be avoided. Our approach is extensively tested using variants of Deep Q-Network adapted to cope with double state input data. Further, we demonstrate that by altering the reward and the Q-value function, the agent is capable of consistently outperforming the adapted Deep Q-Network, Double Deep Q- Network and Deep Recurrent Q-Network. Our results demonstrate that our proposed Extended Double Deep Q-Network (EDDQN) approach is capable of navigating through multiple unseen environments and under severe weather conditions.
Multi-Task Regression-based Learning for Autonomous Unmanned Aerial Vehicle Flight Control within Unstructured Outdoor Environments
Jul 18, 2019
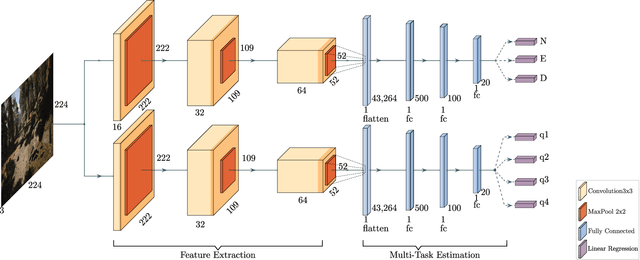
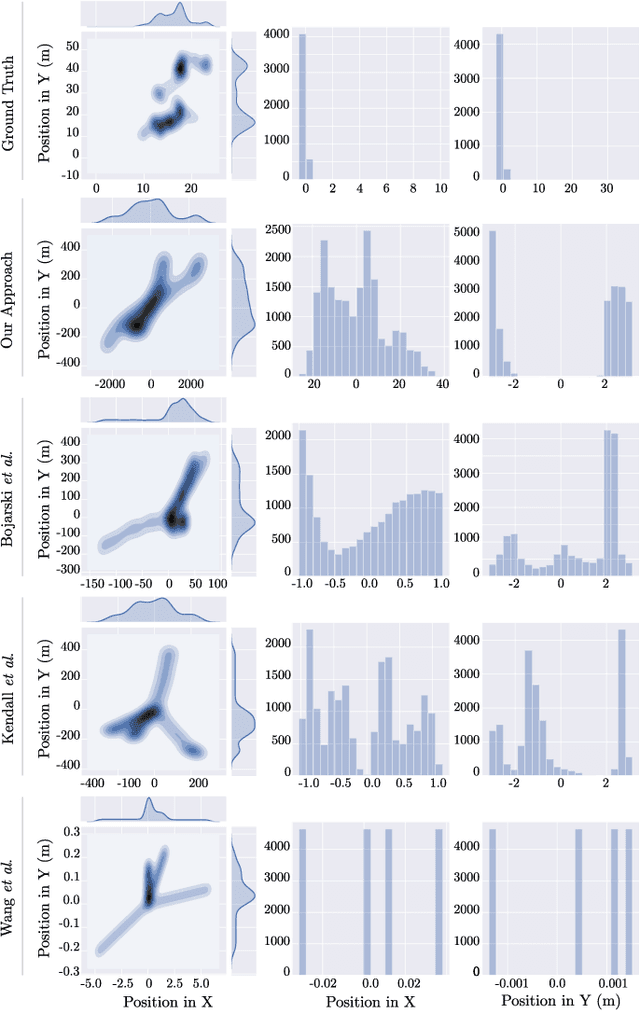
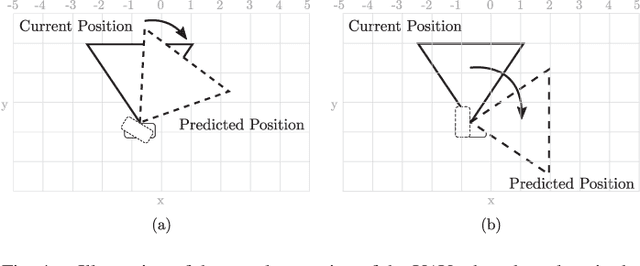
Increased growth in the global Unmanned Aerial Vehicles (UAV) (drone) industry has expanded possibilities for fully autonomous UAV applications. A particular application which has in part motivated this research is the use of UAV in wide area search and surveillance operations in unstructured outdoor environments. The critical issue with such environments is the lack of structured features that could aid in autonomous flight, such as road lines or paths. In this paper, we propose an End-to-End Multi-Task Regression-based Learning approach capable of defining flight commands for navigation and exploration under the forest canopy, regardless of the presence of trails or additional sensors (i.e. GPS). Training and testing are performed using a software in the loop pipeline which allows for a detailed evaluation against state-of-the-art pose estimation techniques. Our extensive experiments demonstrate that our approach excels in performing dense exploration within the required search perimeter, is capable of covering wider search regions, generalises to previously unseen and unexplored environments and outperforms contemporary state-of-the-art techniques.