 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Joint Resource Allocation for Wireless Powered ISAC with Target Localization
Dec 31, 2025Wireless powered integrated sensing and communication (ISAC) faces a fundamental tradeoff between energy supply, communication throughput, and sensing accuracy. This paper investigates a wireless powered ISAC system with target localization requirements, where users harvest energy from wireless power transfer (WPT) and then conduct ISAC transmissions in a time-division manner. In addition to energy supply, the WPT signal also contributes to target sensing, and the localization accuracy is characterized by Cramér-Rao bound (CRB) constraints. Under this setting, we formulate a max-min throughput maximization problem by jointly allocating the WPT duration, ISAC transmission time allocation, and transmit power. Due to the nonconvexity of the resulting problem, a suitable reformulation is developed by exploiting variable substitutions and the monotonicity of logarithmic functions, based on which an efficient successive convex approximation (SCA)-based iterative algorithm is proposed. Simulation results demonstrate convergence and significant performance gains over benchmark schemes, highlighting the importance of coordinated time-power optimization in balancing sensing accuracy and communication performance in wireless powered ISAC systems.
On Neural Networks as Infinite Tree-Structured Probabilistic Graphical Models
May 27, 2023Deep neural networks (DNNs) lack the precise semantics and definitive probabilistic interpretation of probabilistic graphical models (PGMs). In this paper, we propose an innovative solution by constructing infinite tree-structured PGMs that correspond exactly to neural networks. Our research reveals that DNNs, during forward propagation, indeed perform approximations of PGM inference that are precise in this alternative PGM structure. Not only does our research complement existing studies that describe neural networks as kernel machines or infinite-sized Gaussian processes, it also elucidates a more direct approximation that DNNs make to exact inference in PGMs. Potential benefits include improved pedagogy and interpretation of DNNs, and algorithms that can merge the strengths of PGMs and DNNs.
ACDER: Augmented Curiosity-Driven Experience Replay
Nov 16, 2020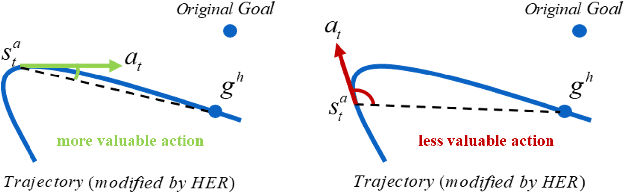
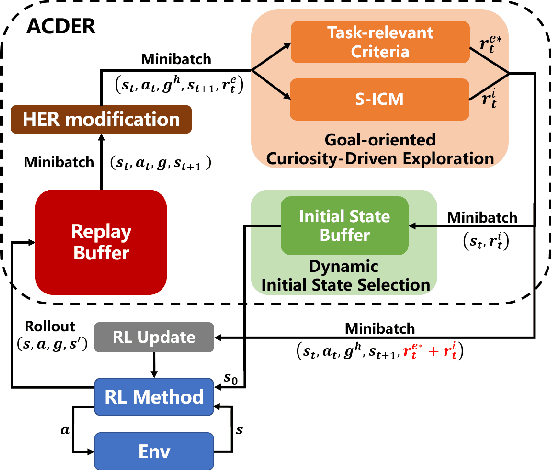


Exploration in environments with sparse feedback remains a challenging research problem in reinforcement learning (RL). When the RL agent explores the environment randomly, it results in low exploration efficiency, especially in robotic manipulation tasks with high dimensional continuous state and action space. In this paper, we propose a novel method, called Augmented Curiosity-Driven Experience Replay (ACDER), which leverages (i) a new goal-oriented curiosity-driven exploration to encourage the agent to pursue novel and task-relevant states more purposefully and (ii) the dynamic initial states selection as an automatic exploratory curriculum to further improve the sample-efficiency. Our approach complements Hindsight Experience Replay (HER) by introducing a new way to pursue valuable states. Experiments conducted on four challenging robotic manipulation tasks with binary rewards, including Reach, Push, Pick&Place and Multi-step Push. The empirical results show that our proposed method significantly outperforms existing methods in the first three basic tasks and also achieves satisfactory performance in multi-step robotic task learning.
Hindsight Generative Adversarial Imitation Learning
Mar 19, 2019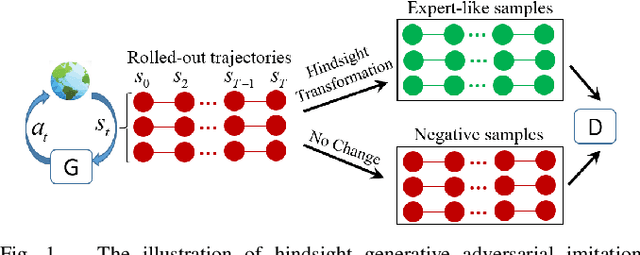
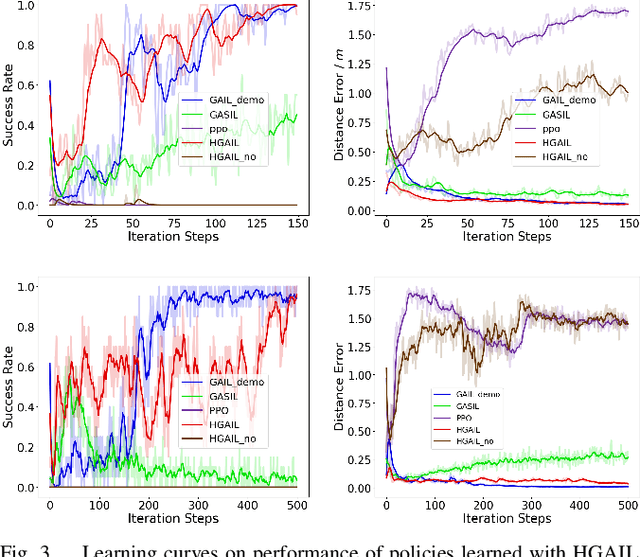
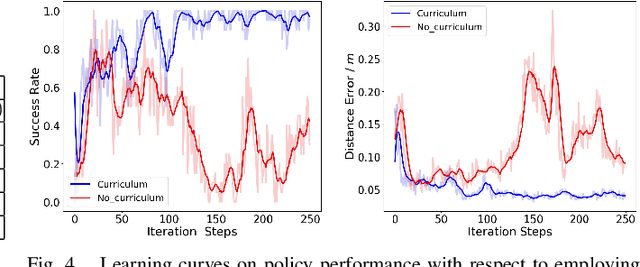
Compared to reinforcement learning, imitation learning (IL) is a powerful paradigm for training agents to learn control policies efficiently from expert demonstrations. However, in most cases, obtaining demonstration data is costly and laborious, which poses a significant challenge in some scenarios. A promising alternative is to train agent learning skills via imitation learning without expert demonstrations, which, to some extent, would extremely expand imitation learning areas. To achieve such expectation, in this paper, we propose Hindsight Generative Adversarial Imitation Learning (HGAIL) algorithm, with the aim of achieving imitation learning satisfying no need of demonstrations. Combining hindsight idea with the generative adversarial imitation learning (GAIL) framework, we realize implementing imitation learning successfully in cases of expert demonstration data are not available. Experiments show that the proposed method can train policies showing comparable performance to current imitation learning methods. Further more, HGAIL essentially endows curriculum learning mechanism which is critical for learning policies.