 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Fuzzing for Testing and Securing Cyber-Physical Systems
May 28, 2020
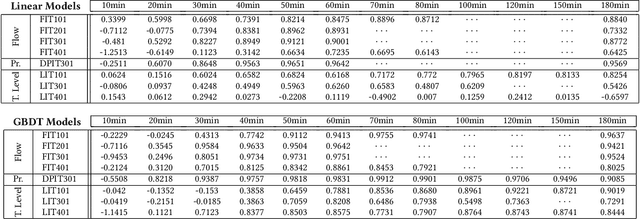
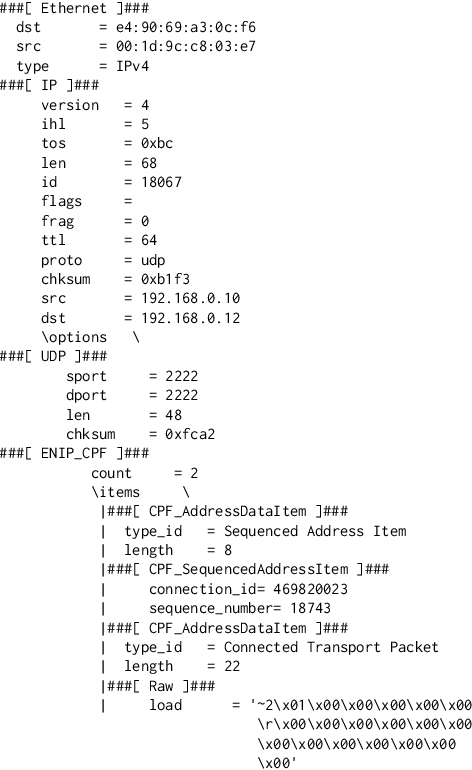
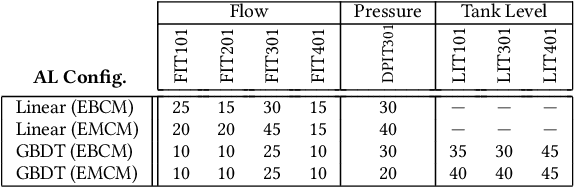
Cyber-physical systems (CPSs) in critical infrastructure face a pervasive threat from attackers, motivating research into a variety of countermeasures for securing them. Assessing the effectiveness of these countermeasures is challenging, however, as realistic benchmarks of attacks are difficult to manually construct, blindly testing is ineffective due to the enormous search spaces and resource requirements, and intelligent fuzzing approaches require impractical amounts of data and network access. In this work, we propose active fuzzing, an automatic approach for finding test suites of packet-level CPS network attacks, targeting scenarios in which attackers can observe sensors and manipulate packets, but have no existing knowledge about the payload encodings. Our approach learns regression models for predicting sensor values that will result from sampled network packets, and uses these predictions to guide a search for payload manipulations (i.e. bit flips) most likely to drive the CPS into an unsafe state. Key to our solution is the use of online active learning, which iteratively updates the models by sampling payloads that are estimated to maximally improve them. We evaluate the efficacy of active fuzzing by implementing it for a water purification plant testbed, finding it can automatically discover a test suite of flow, pressure, and over/underflow attacks, all with substantially less time, data, and network access than the most comparable approach. Finally, we demonstrate that our prediction models can also be utilised as countermeasures themselves, implementing them as anomaly detectors and early warning systems.
Defending Model Inversion and Membership Inference Attacks via Prediction Purification
May 08, 2020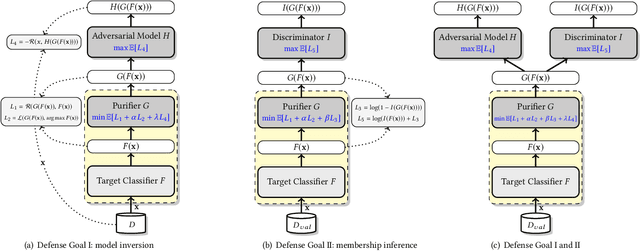
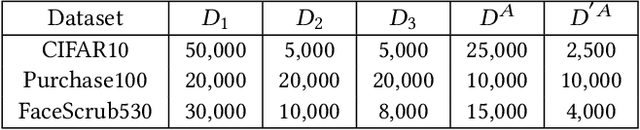
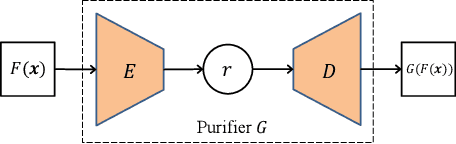
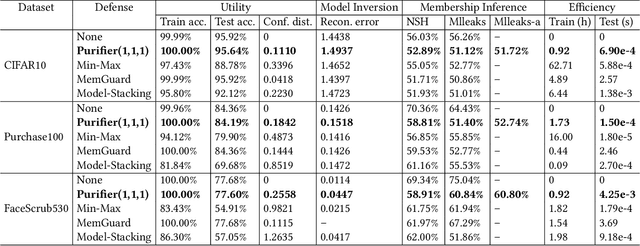
Neural networks are susceptible to data inference attacks such as the model inversion attack and the membership inference attack, where the attacker could infer the reconstruction and the membership of a data sample from the confidence scores predicted by the target classifier. In this paper, we propose a common approach, namely purification framework, to defend data inference attacks. It purifies the confidence score vectors predicted by the target classifier, with the goal of removing redundant information that could be exploited by the attacker to perform the inferences. Specifically, we design a purifier model which takes a confidence score vector as input and reshapes it to meet the defense goals. It does not retrain the target classifier. The purifier can be used to mitigate the model inversion attack, the membership inference attack or both attacks. We evaluate our approach on deep neural networks using benchmark datasets. We show that the purification framework can effectively defend the model inversion attack and the membership inference attack, while introducing negligible utility loss to the target classifier (e.g., less than 0.3% classification accuracy drop). Moreover, we also empirically show that it is possible to defend data inference attacks with negligible change to the generalization ability of the classification function.