 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing with Difficulty: A Bayesian Rating Model for Heterogeneous Items
May 29, 2024



In applied statistics and machine learning, the "gold standards" used for training are often biased and almost always noisy. Dawid and Skene's justifiably popular crowdsourcing model adjusts for rater (coder, annotator) sensitivity and specificity, but fails to capture distributional properties of rating data gathered for training, which in turn biases training. In this study, we introduce a general purpose measurement-error model with which we can infer consensus categories by adding item-level effects for difficulty, discriminativeness, and guessability. We further show how to constrain the bimodal posterior of these models to avoid (or if necessary, allow) adversarial raters. We validate our model's goodness of fit with posterior predictive checks, the Bayesian analogue of $\chi^2$ tests. Dawid and Skene's model is rejected by goodness of fit tests, whereas our new model, which adjusts for item heterogeneity, is not rejected. We illustrate our new model with two well-studied data sets, binary rating data for caries in dental X-rays and implication in natural language.
GIST: Gibbs self-tuning for locally adaptive Hamiltonian Monte Carlo
Apr 23, 2024



We present a novel and flexible framework for localized tuning of Hamiltonian Monte Carlo samplers by sampling the algorithm's tuning parameters conditionally based on the position and momentum at each step. For adaptively sampling path lengths, we show that randomized Hamiltonian Monte Carlo, the No-U-Turn Sampler, and the Apogee-to-Apogee Path Sampler all fit within this unified framework as special cases. The framework is illustrated with a simple alternative to the No-U-Turn Sampler for locally adapting path lengths.
Delayed rejection Hamiltonian Monte Carlo for sampling multiscale distributions
Oct 01, 2021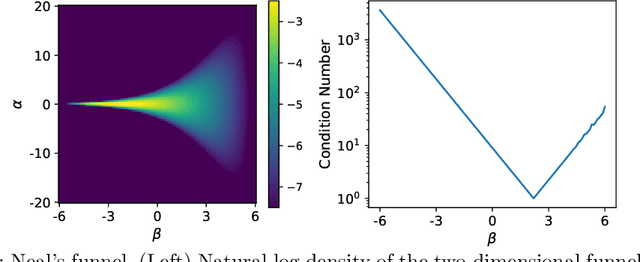



The efficiency of Hamiltonian Monte Carlo (HMC) can suffer when sampling a distribution with a wide range of length scales, because the small step sizes needed for stability in high-curvature regions are inefficient elsewhere. To address this we present a delayed rejection variant: if an initial HMC trajectory is rejected, we make one or more subsequent proposals each using a step size geometrically smaller than the last. We extend the standard delayed rejection framework by allowing the probability of a retry to depend on the probability of accepting the previous proposal. We test the scheme in several sampling tasks, including multiscale model distributions such as Neal's funnel, and statistical applications. Delayed rejection enables up to five-fold performance gains over optimally-tuned HMC, as measured by effective sample size per gradient evaluation. Even for simpler distributions, delayed rejection provides increased robustness to step size misspecification. Along the way, we provide an accessible but rigorous review of detailed balance for HMC.
Pathfinder: Parallel quasi-Newton variational inference
Aug 11, 2021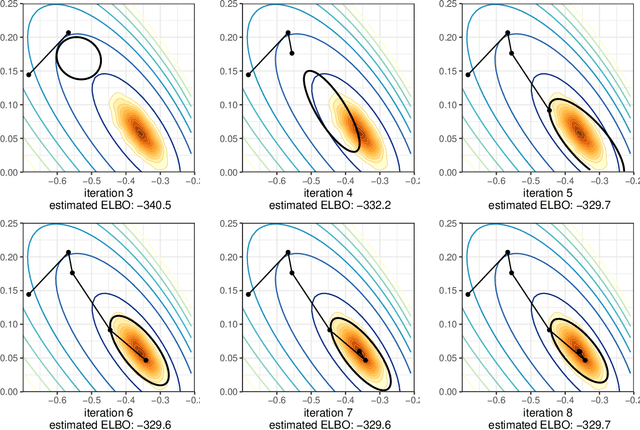
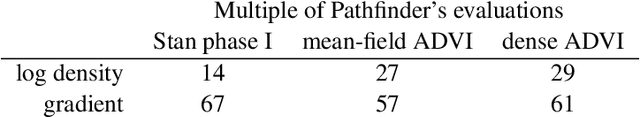
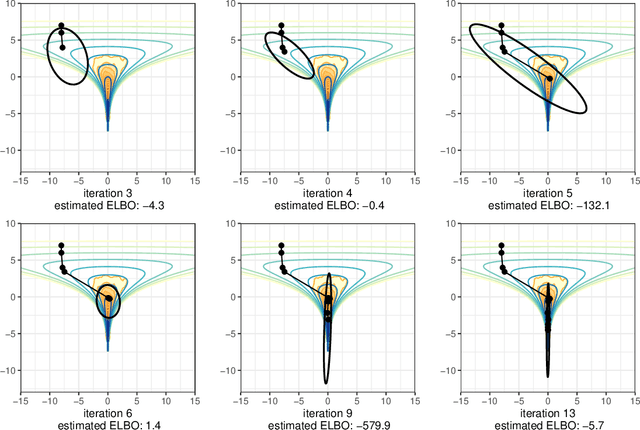

We introduce Pathfinder, a variational method for approximately sampling from differentiable log densities. Starting from a random initialization, Pathfinder locates normal approximations to the target density along a quasi-Newton optimization path, with local covariance estimated using the inverse Hessian estimates produced by the optimizer. Pathfinder returns draws from the approximation with the lowest estimated Kullback-Leibler (KL) divergence to the true posterior. We evaluate Pathfinder on a wide range of posterior distributions, demonstrating that its approximate draws are better than those from automatic differentiation variational inference (ADVI) and comparable to those produced by short chains of dynamic Hamiltonian Monte Carlo (HMC), as measured by 1-Wasserstein distance. Compared to ADVI and short dynamic HMC runs, Pathfinder requires one to two orders of magnitude fewer log density and gradient evaluations, with greater reductions for more challenging posteriors. Importance resampling over multiple runs of Pathfinder improves the diversity of approximate draws, reducing 1-Wasserstein distance further and providing a measure of robustness to optimization failures on plateaus, saddle points, or in minor modes. The Monte Carlo KL-divergence estimates are embarrassingly parallelizable in the core Pathfinder algorithm, as are multiple runs in the resampling version, further increasing Pathfinder's speed advantage with multiple cores.
Probabilistic Parsing Using Left Corner Language Models
Nov 17, 1997


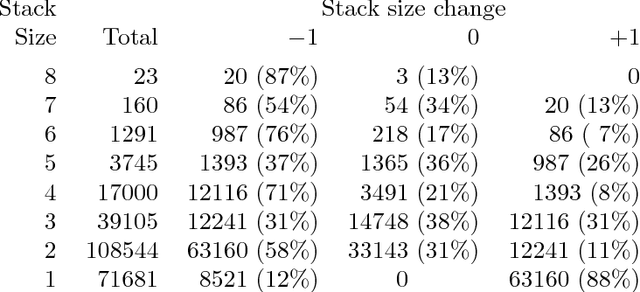
We introduce a novel parser based on a probabilistic version of a left-corner parser. The left-corner strategy is attractive because rule probabilities can be conditioned on both top-down goals and bottom-up derivations. We develop the underlying theory and explain how a grammar can be induced from analyzed data. We show that the left-corner approach provides an advantage over simple top-down probabilistic context-free grammars in parsing the Wall Street Journal using a grammar induced from the Penn Treebank. We also conclude that the Penn Treebank provides a fairly weak testbed due to the flatness of its bracketings and to the obvious overgeneration and undergeneration of its induced grammar.
* 12 pages, uses iwpt97.sty