Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Parsing Using Left Corner Language Models
Paper and Code
Nov 17, 1997


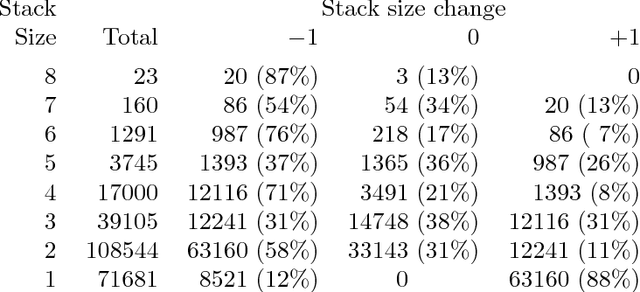
We introduce a novel parser based on a probabilistic version of a left-corner parser. The left-corner strategy is attractive because rule probabilities can be conditioned on both top-down goals and bottom-up derivations. We develop the underlying theory and explain how a grammar can be induced from analyzed data. We show that the left-corner approach provides an advantage over simple top-down probabilistic context-free grammars in parsing the Wall Street Journal using a grammar induced from the Penn Treebank. We also conclude that the Penn Treebank provides a fairly weak testbed due to the flatness of its bracketings and to the obvious overgeneration and undergeneration of its induced grammar.
* Proceedings of the Fifth International Workshop on Parsing
Technologies, MIT, Boston MA, 1997 * 12 pages, uses iwpt97.sty
View paper on