 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Equivariance: Modeling Turbulence with Graph Neural Networks
Apr 10, 2025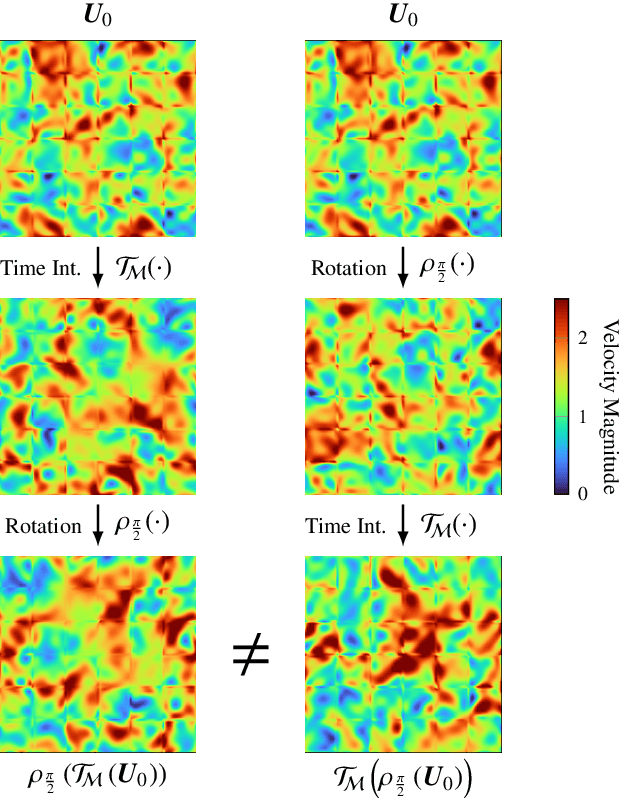
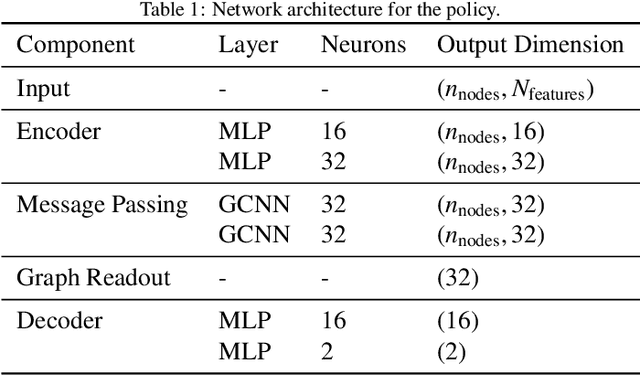
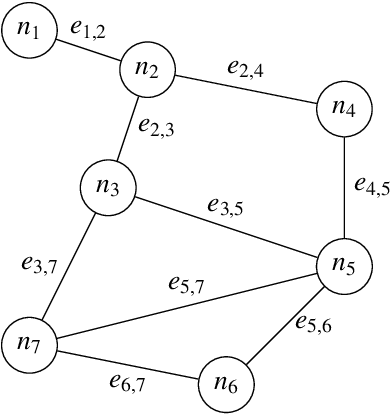

This work proposes a novel methodology for turbulence modeling in Large Eddy Simulation (LES) based on Graph Neural Networks (GNNs), which embeds the discrete rotational, reflectional and translational symmetries of the Navier-Stokes equations into the model architecture. In addition, suitable invariant input and output spaces are derived that allow the GNN models to be embedded seamlessly into the LES framework to obtain a symmetry-preserving simulation setup. The suitability of the proposed approach is investigated for two canonical test cases: Homogeneous Isotropic Turbulence (HIT) and turbulent channel flow. For both cases, GNN models are trained successfully in actual simulations using Reinforcement Learning (RL) to ensure that the models are consistent with the underlying LES formulation and discretization. It is demonstrated for the HIT case that the resulting GNN-based LES scheme recovers rotational and reflectional equivariance up to machine precision in actual simulations. At the same time, the stability and accuracy remain on par with non-symmetry-preserving machine learning models that fail to obey these properties. The same modeling strategy translates well to turbulent channel flow, where the GNN model successfully learns the more complex flow physics and is able to recover the turbulent statistics and Reynolds stresses. It is shown that the GNN model learns a zonal modeling strategy with distinct behaviors in the near-wall and outer regions. The proposed approach thus demonstrates the potential of GNNs for turbulence modeling, especially in the context of LES and RL.
Energy-Conserving Neural Network Closure Model for Long-Time Accurate and Stable LES
Apr 08, 2025



Machine learning-based closure models for LES have shown promise in capturing complex turbulence dynamics but often suffer from instabilities and physical inconsistencies. In this work, we develop a novel skew-symmetric neural architecture as closure model that enforces stability while preserving key physical conservation laws. Our approach leverages a discretization that ensures mass, momentum, and energy conservation, along with a face-averaging filter to maintain mass conservation in coarse-grained velocity fields. We compare our model against several conventional data-driven closures (including unconstrained convolutional neural networks), and the physics-based Smagorinsky model. Performance is evaluated on decaying turbulence and Kolmogorov flow for multiple coarse-graining factors. In these test cases we observe that unconstrained machine learning models suffer from numerical instabilities. In contrast, our skew-symmetric model remains stable across all tests, though at the cost of increased dissipation. Despite this trade-off, we demonstrate that our model still outperforms the Smagorinsky model in unseen scenarios. These findings highlight the potential of structure-preserving machine learning closures for reliable long-time LES.
Physics-aware generative models for turbulent fluid flows through energy-consistent stochastic interpolants
Apr 08, 2025



Generative models have demonstrated remarkable success in domains such as text, image, and video synthesis. In this work, we explore the application of generative models to fluid dynamics, specifically for turbulence simulation, where classical numerical solvers are computationally expensive. We propose a novel stochastic generative model based on stochastic interpolants, which enables probabilistic forecasting while incorporating physical constraints such as energy stability and divergence-freeness. Unlike conventional stochastic generative models, which are often agnostic to underlying physical laws, our approach embeds energy consistency by making the parameters of the stochastic interpolant learnable coefficients. We evaluate our method on a benchmark turbulence problem - Kolmogorov flow - demonstrating superior accuracy and stability over state-of-the-art alternatives such as autoregressive conditional diffusion models (ACDMs) and PDE-Refiner. Furthermore, we achieve stable results for significantly longer roll-outs than standard stochastic interpolants. Our results highlight the potential of physics-aware generative models in accelerating and enhancing turbulence simulations while preserving fundamental conservation properties.
Comparison of neural closure models for discretised PDEs
Oct 26, 2022



Neural closure models have recently been proposed as a method for efficiently approximating small scales in multiscale systems with neural networks. The choice of loss function and associated training procedure has a large effect on the accuracy and stability of the resulting neural closure model. In this work, we systematically compare three distinct procedures: "derivative fitting", "trajectory fitting" with discretise-then-optimise, and "trajectory fitting" with optimise-then-discretise. Derivative fitting is conceptually the simplest and computationally the most efficient approach and is found to perform reasonably well on one of the test problems (Kuramoto-Sivashinsky) but poorly on the other (Burgers). Trajectory fitting is computationally more expensive but is more robust and is therefore the preferred approach. Of the two trajectory fitting procedures, the discretise-then-optimise approach produces more accurate models than the optimise-then-discretise approach. While the optimise-then-discretise approach can still produce accurate models, care must be taken in choosing the length of the trajectories used for training, in order to train the models on long-term behaviour while still producing reasonably accurate gradients during training. Two existing theorems are interpreted in a novel way that gives insight into the long-term accuracy of a neural closure model based on how accurate it is in the short term.