 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Psycho-linguistic Analysis of BitChute
Apr 20, 2022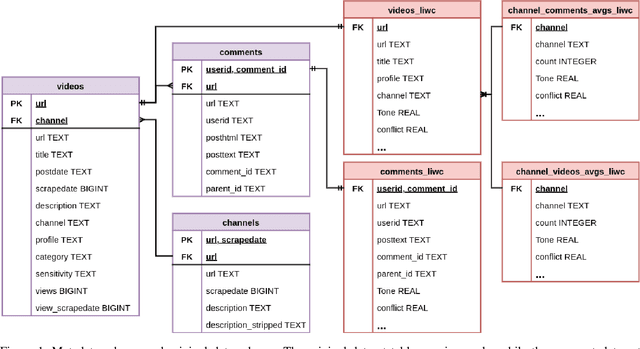
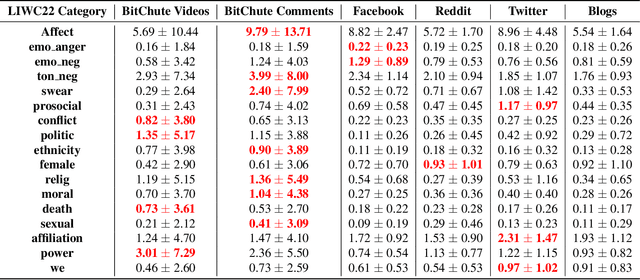

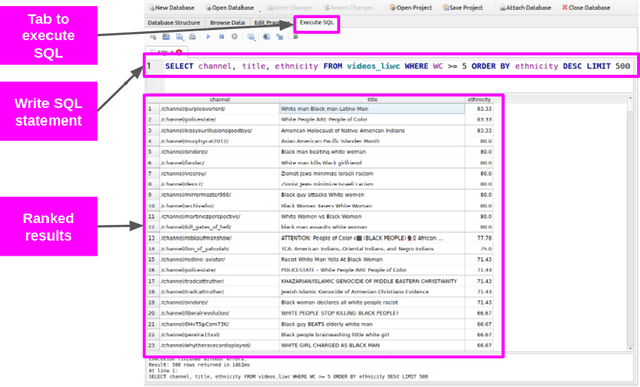
In order to better support researchers, journalist, and practitioners in their use of the MeLa-BitChute dataset for exploration and investigative reporting, we provide new psycho-linguistic metadata for the videos, comments, and channels in the dataset using LIWC22. This paper describes that metadata and methods to filter the data using the metadata. In addition, we provide basic analysis and comparison of the language on BitChute to other social media platforms. The MeLa-BitChute dataset and LIWC metadata described in this paper can be found at: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/KRD1VS.
NELA-GT-2021: A Large Multi-Labelled News Dataset for The Study of Misinformation in News Articles
Mar 10, 2022
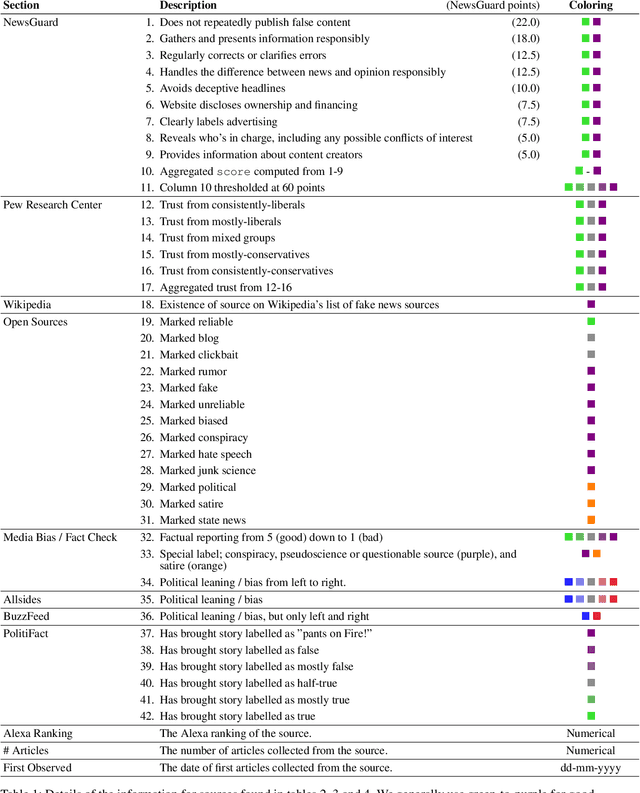

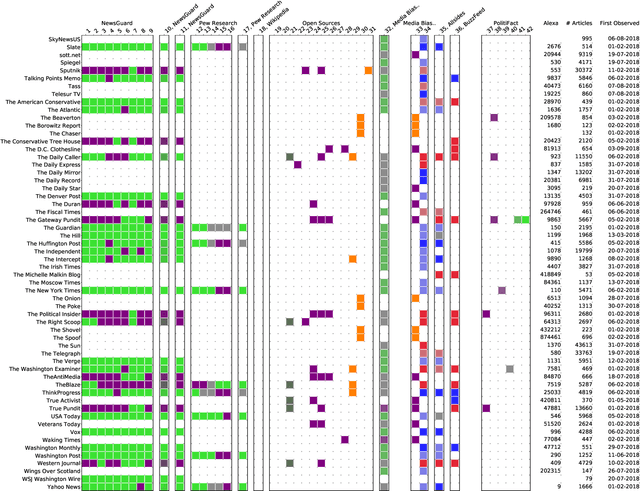
In this paper, we present the fourth installment of the NELA-GT datasets, NELA-GT-2021. The dataset contains 1.8M articles from 367 outlets between January 1st, 2021 and December 31st, 2021. Just as in past releases of the dataset, NELA-GT-2021 includes outlet-level veracity labels from Media Bias/Fact Check and tweets embedded in collected news articles. The NELA-GT-2021 dataset can be found at: https://doi.org/10.7910/DVN/RBKVBM
The MeLa BitChute Dataset
Feb 10, 2022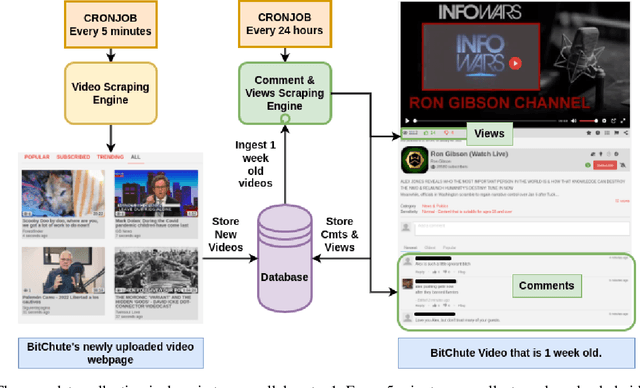
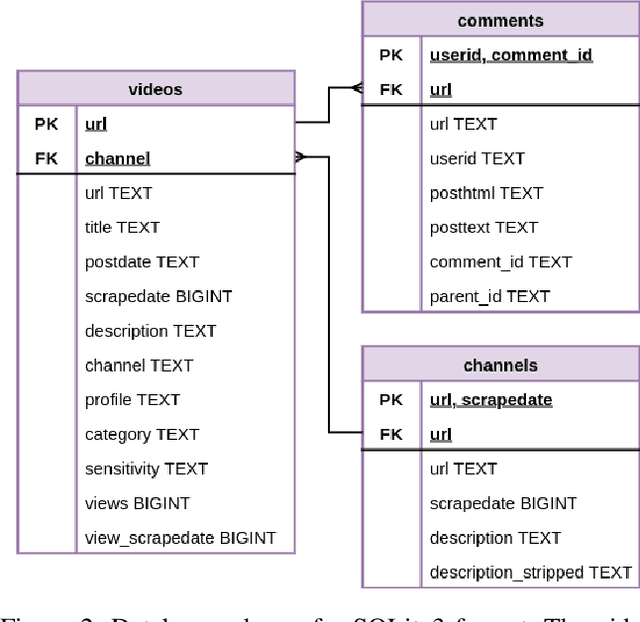

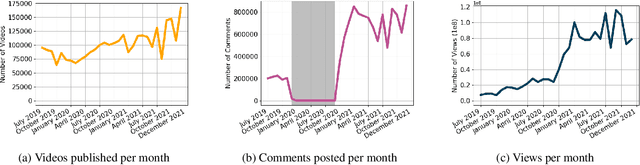
In this paper we present a near-complete dataset of over 3M videos from 61K channels over 2.5 years (June 2019 to December 2021) from the social video hosting platform BitChute, a commonly used alternative to YouTube. Additionally, we include a variety of video-level metadata, including comments, channel descriptions, and views for each video. The MeLa-BitChute dataset can be found at: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/KRD1VS.
Tell Me Who Your Friends Are: Using Content Sharing Behavior for News Source Veracity Detection
Jan 15, 2021
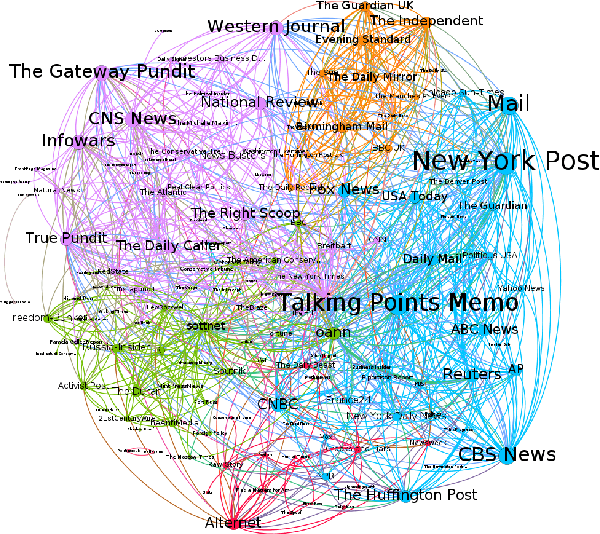
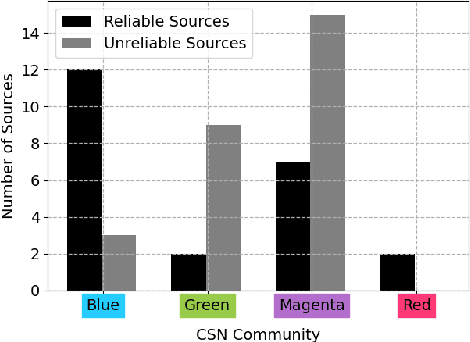

Stopping the malicious spread and production of false and misleading news has become a top priority for researchers. Due to this prevalence, many automated methods for detecting low quality information have been introduced. The majority of these methods have used article-level features, such as their writing style, to detect veracity. While writing style models have been shown to work well in lab-settings, there are concerns of generalizability and robustness. In this paper, we begin to address these concerns by proposing a novel and robust news veracity detection model that uses the content sharing behavior of news sources formulated as a network. We represent these content sharing networks (CSN) using a deep walk based method for embedding graphs that accounts for similarity in both the network space and the article text space. We show that state of the art writing style and CSN features make diverse mistakes when predicting, meaning that they both play different roles in the classification task. Moreover, we show that the addition of CSN features increases the accuracy of writing style models, boosting accuracy as much as 14\% when using Random Forests. Similarly, we show that the combination of hand-crafted article-level features and CSN features is robust to concept drift, performing consistently well over a 10-month time frame.
Do All Good Actors Look The Same? Exploring News Veracity Detection Across The U.S. and The U.K
May 26, 2020
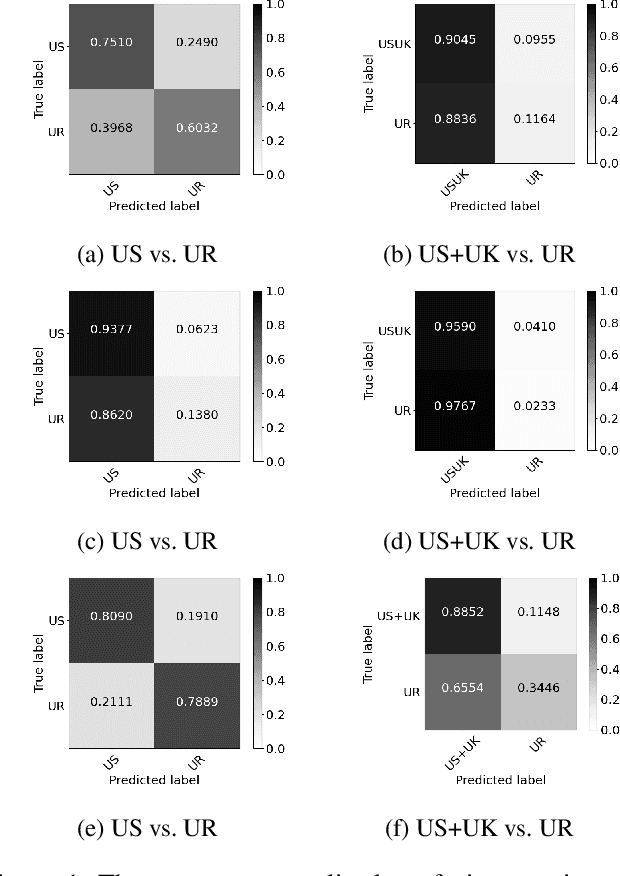
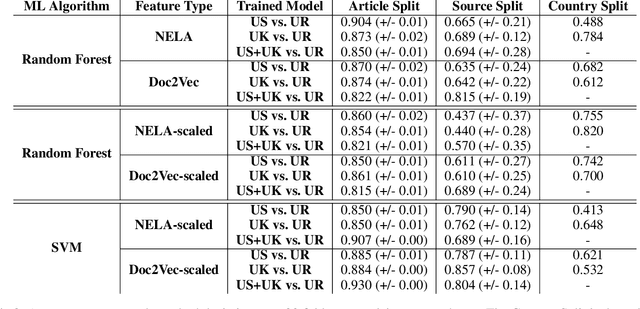
A major concern with text-based news veracity detection methods is that they may not generalize across countries and cultures. In this short paper, we explicitly test news veracity models across news data from the United States and the United Kingdom, demonstrating there is reason for concern of generalizabilty. Through a series of testing scenarios, we show that text-based classifiers perform poorly when trained on one country's news data and tested on another. Furthermore, these same models have trouble classifying unseen, unreliable news sources. In conclusion, we discuss implications of these results and avenues for future work.
Models for Predicting Community-Specific Interest in News Articles
Aug 27, 2018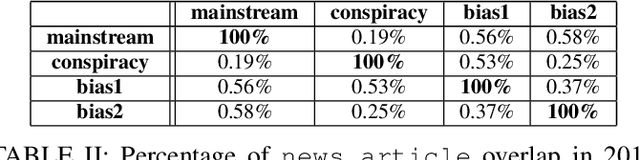
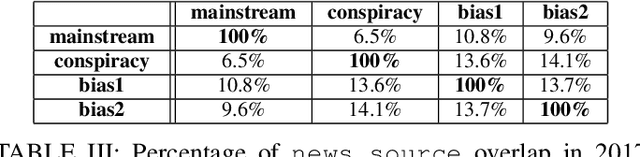

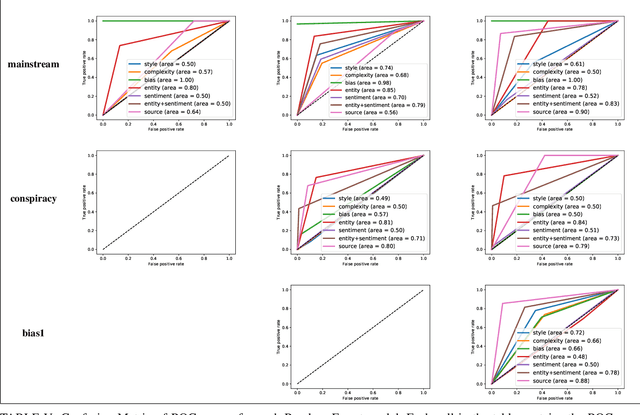
In this work, we ask two questions: 1. Can we predict the type of community interested in a news article using only features from the article content? and 2. How well do these models generalize over time? To answer these questions, we compute well-studied content-based features on over 60K news articles from 4 communities on reddit.com. We train and test models over three different time periods between 2015 and 2017 to demonstrate which features degrade in performance the most due to concept drift. Our models can classify news articles into communities with high accuracy, ranging from 0.81 ROC AUC to 1.0 ROC AUC. However, while we can predict the community-specific popularity of news articles with high accuracy, practitioners should approach these models carefully. Predictions are both community-pair dependent and feature group dependent. Moreover, these feature groups generalize over time differently, with some only degrading slightly over time, but others degrading greatly. Therefore, we recommend that community-interest predictions are done in a hierarchical structure, where multiple binary classifiers can be used to separate community pairs, rather than a traditional multi-class model. Second, these models should be retrained over time based on accuracy goals and the availability of training data.
An Exploration of Unreliable News Classification in Brazil and The U.S
Jun 07, 2018
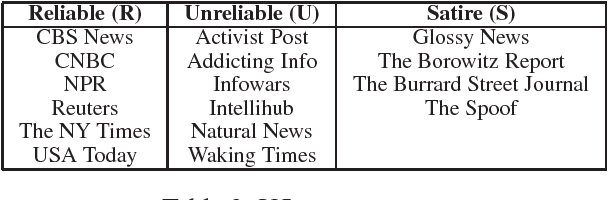

The propagation of unreliable information is on the rise in many places around the world. This expansion is facilitated by the rapid spread of information and anonymity granted by the Internet. The spread of unreliable information is a wellstudied issue and it is associated with negative social impacts. In a previous work, we have identified significant differences in the structure of news articles from reliable and unreliable sources in the US media. Our goal in this work was to explore such differences in the Brazilian media. We found significant features in two data sets: one with Brazilian news in Portuguese and another one with US news in English. Our results show that features related to the writing style were prominent in both data sets and, despite the language difference, some features have a universal behavior, being significant to both US and Brazilian news articles. Finally, we combined both data sets and used the universal features to build a machine learning classifier to predict the source type of a news article as reliable or unreliable.
This Just In: Fake News Packs a Lot in Title, Uses Simpler, Repetitive Content in Text Body, More Similar to Satire than Real News
Mar 28, 2017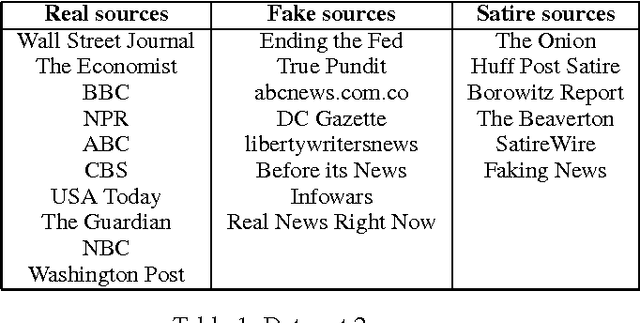

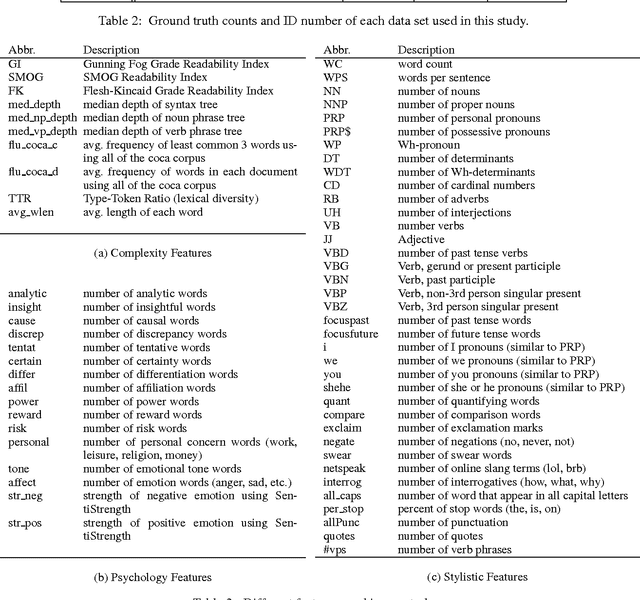
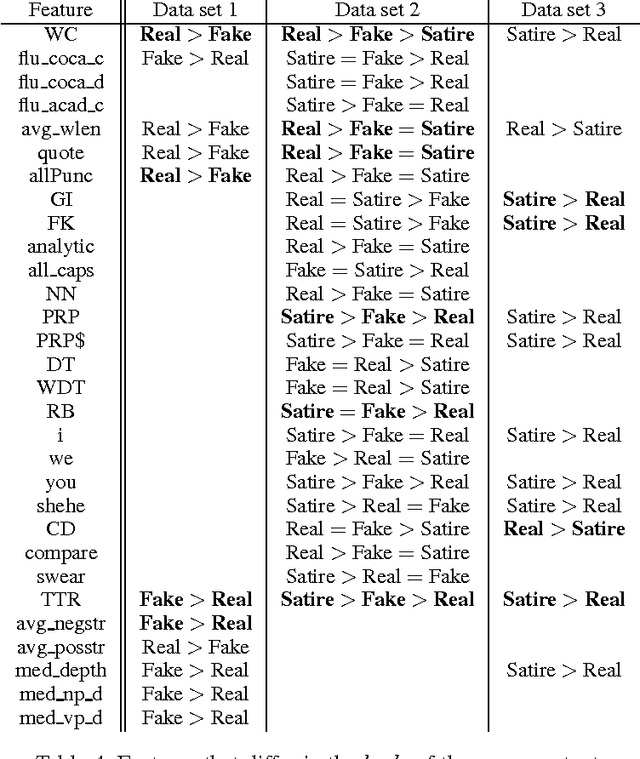
The problem of fake news has gained a lot of attention as it is claimed to have had a significant impact on 2016 US Presidential Elections. Fake news is not a new problem and its spread in social networks is well-studied. Often an underlying assumption in fake news discussion is that it is written to look like real news, fooling the reader who does not check for reliability of the sources or the arguments in its content. Through a unique study of three data sets and features that capture the style and the language of articles, we show that this assumption is not true. Fake news in most cases is more similar to satire than to real news, leading us to conclude that persuasion in fake news is achieved through heuristics rather than the strength of arguments. We show overall title structure and the use of proper nouns in titles are very significant in differentiating fake from real. This leads us to conclude that fake news is targeted for audiences who are not likely to read beyond titles and is aimed at creating mental associations between entities and claims.