Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo All Good Actors Look The Same? Exploring News Veracity Detection Across The U.S. and The U.K
Paper and Code
May 26, 2020
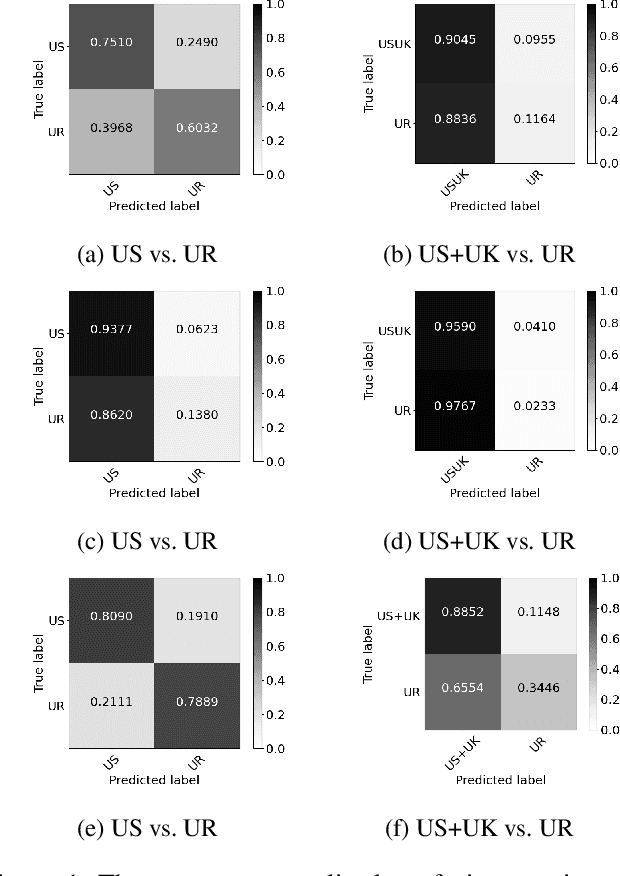
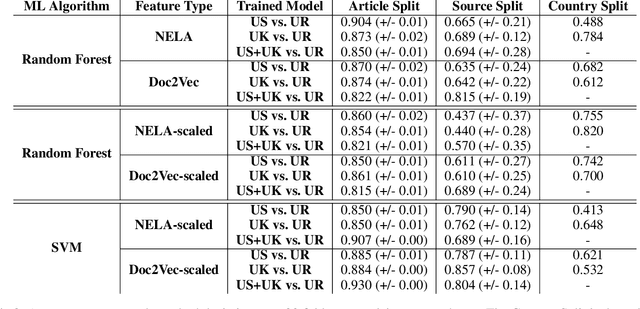
A major concern with text-based news veracity detection methods is that they may not generalize across countries and cultures. In this short paper, we explicitly test news veracity models across news data from the United States and the United Kingdom, demonstrating there is reason for concern of generalizabilty. Through a series of testing scenarios, we show that text-based classifiers perform poorly when trained on one country's news data and tested on another. Furthermore, these same models have trouble classifying unseen, unreliable news sources. In conclusion, we discuss implications of these results and avenues for future work.
* Published in ICWSM 2020 Data Challenge
View paper on