 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking the Temporal Dynamics of News Coverage of Catastrophic and Violent Events
Apr 15, 2026The modern news cycle has been fundamentally reshaped by the rapid exchange of information online. As a result, media framing shifts dynamically as new information, political responses, and social reactions emerge. Understanding how these narratives form, propagate, and evolve is essential for interpreting public discourse during moments of crisis. In this study, we examine the temporal and semantic dynamics of reporting for violent and catastrophic events using a large-scale corpus of 126,602 news articles collected from online publishers. We quantify narrative change through publication volume, semantic drift, semantic dispersion, and term relevance. Our results show that sudden events of impact exhibit structured and predictable news-cycle patterns characterized by rapid surges in coverage, early semantic drift, and gradual declines toward the baseline. In addition, our results indicate the terms that are driving the temporal patterns.
NELA-GT-2021: A Large Multi-Labelled News Dataset for The Study of Misinformation in News Articles
Mar 10, 2022
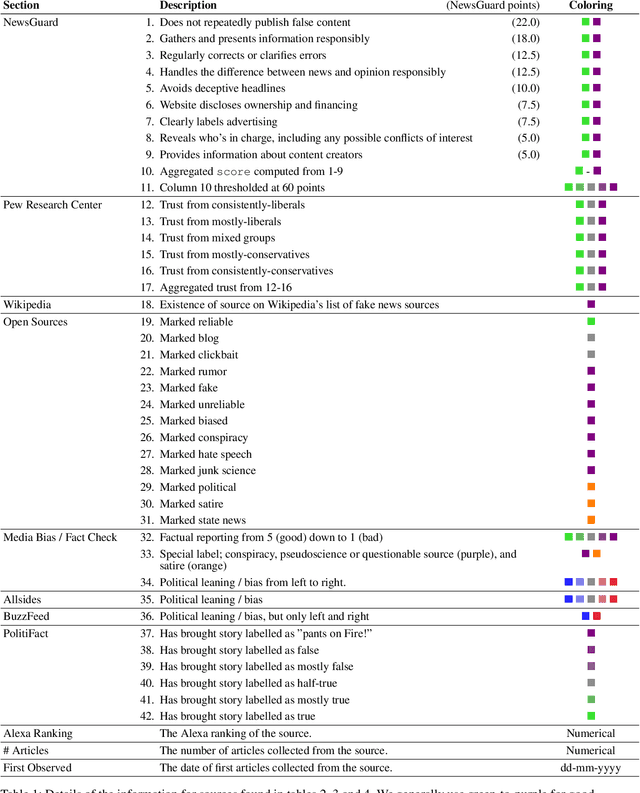

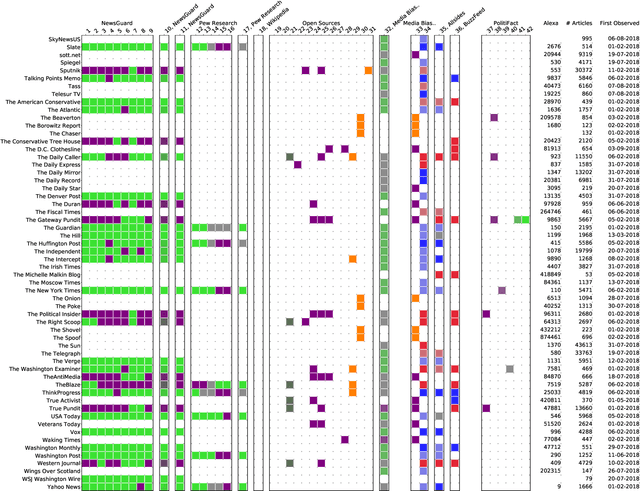
In this paper, we present the fourth installment of the NELA-GT datasets, NELA-GT-2021. The dataset contains 1.8M articles from 367 outlets between January 1st, 2021 and December 31st, 2021. Just as in past releases of the dataset, NELA-GT-2021 includes outlet-level veracity labels from Media Bias/Fact Check and tweets embedded in collected news articles. The NELA-GT-2021 dataset can be found at: https://doi.org/10.7910/DVN/RBKVBM
The MeLa BitChute Dataset
Feb 10, 2022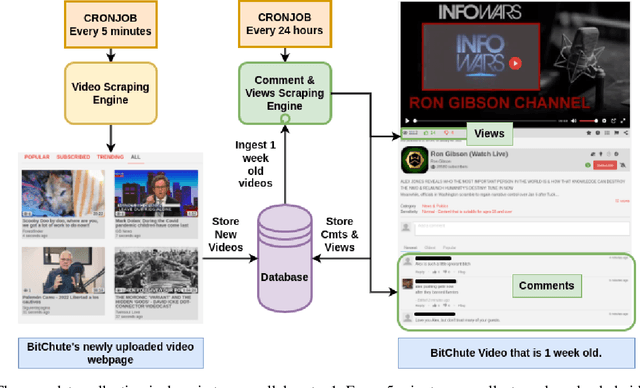
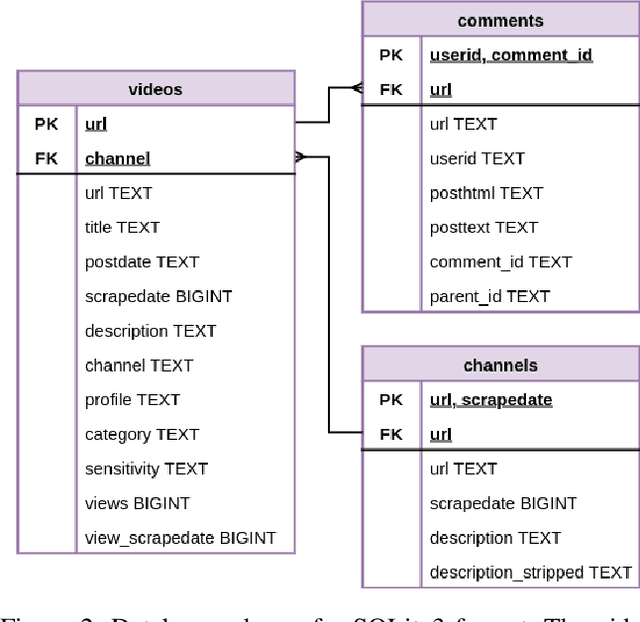

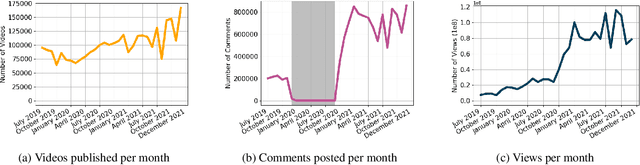
In this paper we present a near-complete dataset of over 3M videos from 61K channels over 2.5 years (June 2019 to December 2021) from the social video hosting platform BitChute, a commonly used alternative to YouTube. Additionally, we include a variety of video-level metadata, including comments, channel descriptions, and views for each video. The MeLa-BitChute dataset can be found at: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/KRD1VS.
Fake it Till You Make it: Self-Supervised Semantic Shifts for Monolingual Word Embedding Tasks
Jan 30, 2021


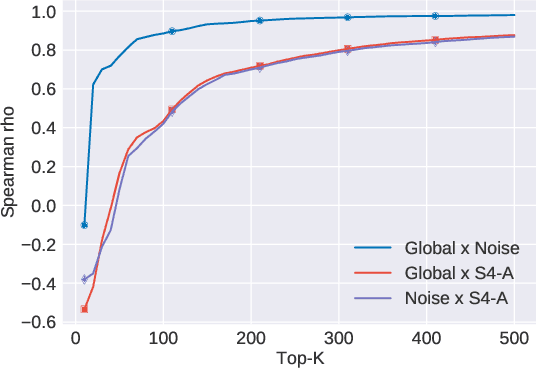
The use of language is subject to variation over time as well as across social groups and knowledge domains, leading to differences even in the monolingual scenario. Such variation in word usage is often called lexical semantic change (LSC). The goal of LSC is to characterize and quantify language variations with respect to word meaning, to measure how distinct two language sources are (that is, people or language models). Because there is hardly any data available for such a task, most solutions involve unsupervised methods to align two embeddings and predict semantic change with respect to a distance measure. To that end, we propose a self-supervised approach to model lexical semantic change by generating training samples by introducing perturbations of word vectors in the input corpora. We show that our method can be used for the detection of semantic change with any alignment method. Furthermore, it can be used to choose the landmark words to use in alignment and can lead to substantial improvements over the existing techniques for alignment. We illustrate the utility of our techniques using experimental results on three different datasets, involving words with the same or different meanings. Our methods not only provide significant improvements but also can lead to novel findings for the LSC problem.
Tell Me Who Your Friends Are: Using Content Sharing Behavior for News Source Veracity Detection
Jan 15, 2021
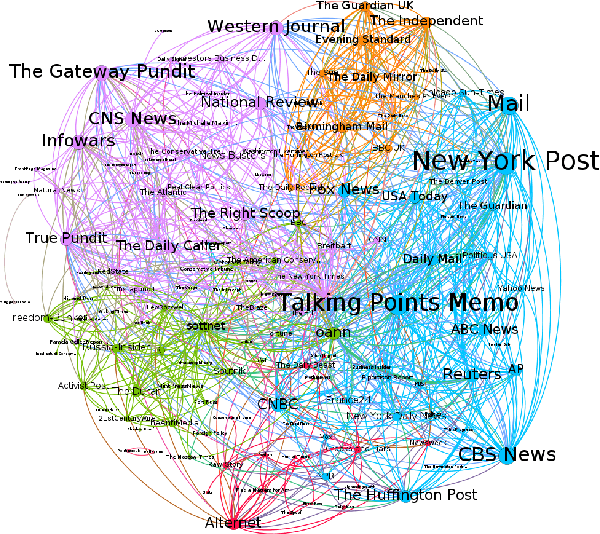
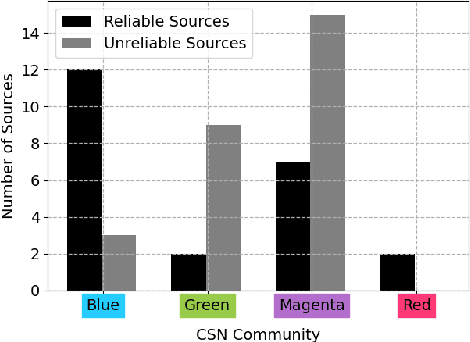

Stopping the malicious spread and production of false and misleading news has become a top priority for researchers. Due to this prevalence, many automated methods for detecting low quality information have been introduced. The majority of these methods have used article-level features, such as their writing style, to detect veracity. While writing style models have been shown to work well in lab-settings, there are concerns of generalizability and robustness. In this paper, we begin to address these concerns by proposing a novel and robust news veracity detection model that uses the content sharing behavior of news sources formulated as a network. We represent these content sharing networks (CSN) using a deep walk based method for embedding graphs that accounts for similarity in both the network space and the article text space. We show that state of the art writing style and CSN features make diverse mistakes when predicting, meaning that they both play different roles in the classification task. Moreover, we show that the addition of CSN features increases the accuracy of writing style models, boosting accuracy as much as 14\% when using Random Forests. Similarly, we show that the combination of hand-crafted article-level features and CSN features is robust to concept drift, performing consistently well over a 10-month time frame.
SChME at SemEval-2020 Task 1: A Model Ensemble for Detecting Lexical Semantic Change
Dec 02, 2020



This paper describes SChME (Semantic Change Detection with Model Ensemble), a method usedin SemEval-2020 Task 1 on unsupervised detection of lexical semantic change. SChME usesa model ensemble combining signals of distributional models (word embeddings) and wordfrequency models where each model casts a vote indicating the probability that a word sufferedsemantic change according to that feature. More specifically, we combine cosine distance of wordvectors combined with a neighborhood-based metric we named Mapped Neighborhood Distance(MAP), and a word frequency differential metric as input signals to our model. Additionally,we explore alignment-based methods to investigate the importance of the landmarks used in thisprocess. Our results show evidence that the number of landmarks used for alignment has a directimpact on the predictive performance of the model. Moreover, we show that languages that sufferless semantic change tend to benefit from using a large number of landmarks, whereas languageswith more semantic change benefit from a more careful choice of landmark number for alignment.
Do All Good Actors Look The Same? Exploring News Veracity Detection Across The U.S. and The U.K
May 26, 2020
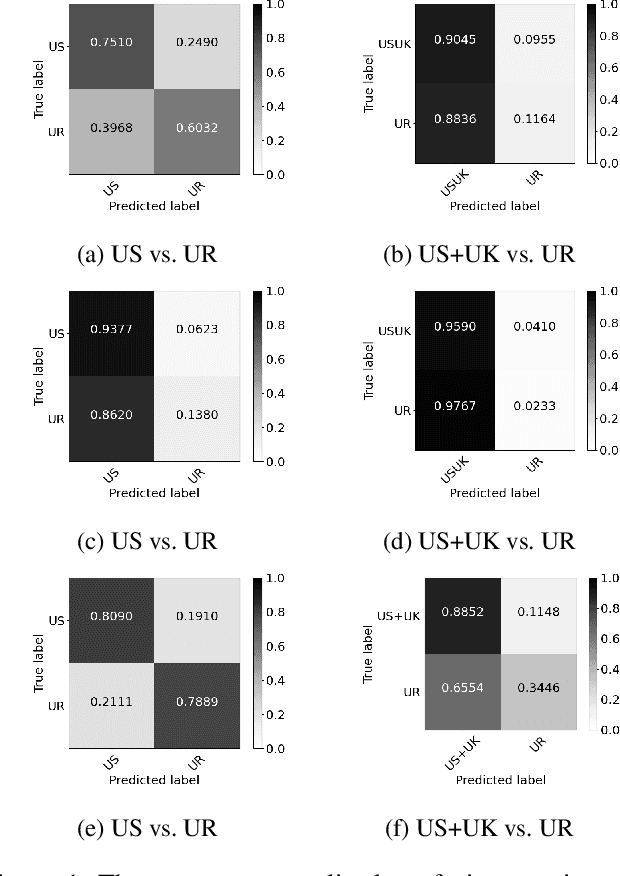
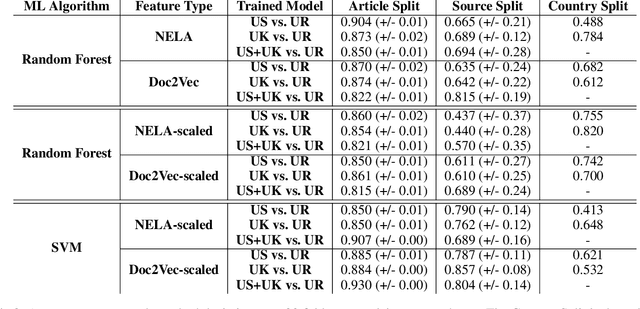
A major concern with text-based news veracity detection methods is that they may not generalize across countries and cultures. In this short paper, we explicitly test news veracity models across news data from the United States and the United Kingdom, demonstrating there is reason for concern of generalizabilty. Through a series of testing scenarios, we show that text-based classifiers perform poorly when trained on one country's news data and tested on another. Furthermore, these same models have trouble classifying unseen, unreliable news sources. In conclusion, we discuss implications of these results and avenues for future work.