 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSChME at SemEval-2020 Task 1: A Model Ensemble for Detecting Lexical Semantic Change
Dec 02, 2020



This paper describes SChME (Semantic Change Detection with Model Ensemble), a method usedin SemEval-2020 Task 1 on unsupervised detection of lexical semantic change. SChME usesa model ensemble combining signals of distributional models (word embeddings) and wordfrequency models where each model casts a vote indicating the probability that a word sufferedsemantic change according to that feature. More specifically, we combine cosine distance of wordvectors combined with a neighborhood-based metric we named Mapped Neighborhood Distance(MAP), and a word frequency differential metric as input signals to our model. Additionally,we explore alignment-based methods to investigate the importance of the landmarks used in thisprocess. Our results show evidence that the number of landmarks used for alignment has a directimpact on the predictive performance of the model. Moreover, we show that languages that sufferless semantic change tend to benefit from using a large number of landmarks, whereas languageswith more semantic change benefit from a more careful choice of landmark number for alignment.
Models for Predicting Community-Specific Interest in News Articles
Aug 27, 2018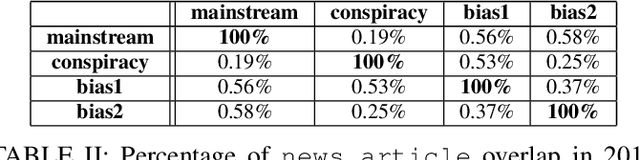
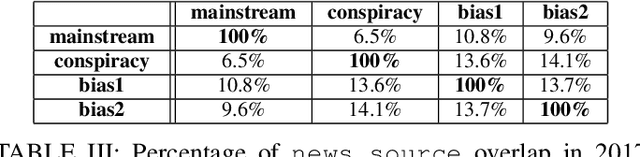

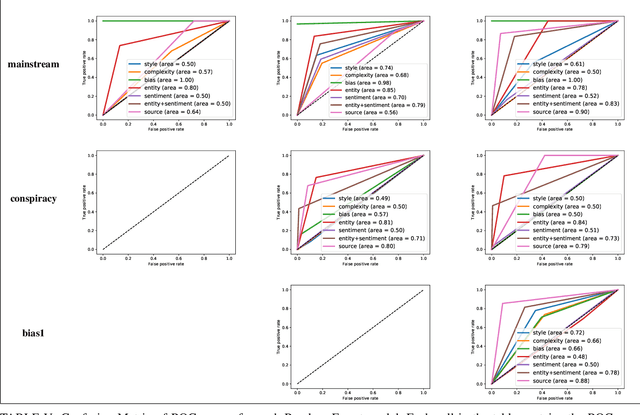
In this work, we ask two questions: 1. Can we predict the type of community interested in a news article using only features from the article content? and 2. How well do these models generalize over time? To answer these questions, we compute well-studied content-based features on over 60K news articles from 4 communities on reddit.com. We train and test models over three different time periods between 2015 and 2017 to demonstrate which features degrade in performance the most due to concept drift. Our models can classify news articles into communities with high accuracy, ranging from 0.81 ROC AUC to 1.0 ROC AUC. However, while we can predict the community-specific popularity of news articles with high accuracy, practitioners should approach these models carefully. Predictions are both community-pair dependent and feature group dependent. Moreover, these feature groups generalize over time differently, with some only degrading slightly over time, but others degrading greatly. Therefore, we recommend that community-interest predictions are done in a hierarchical structure, where multiple binary classifiers can be used to separate community pairs, rather than a traditional multi-class model. Second, these models should be retrained over time based on accuracy goals and the availability of training data.
An Exploration of Unreliable News Classification in Brazil and The U.S
Jun 07, 2018
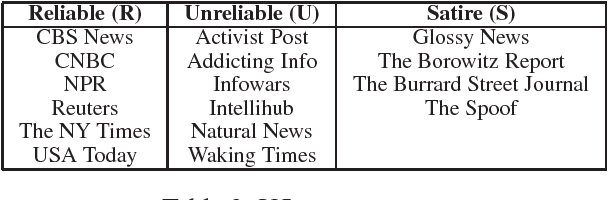

The propagation of unreliable information is on the rise in many places around the world. This expansion is facilitated by the rapid spread of information and anonymity granted by the Internet. The spread of unreliable information is a wellstudied issue and it is associated with negative social impacts. In a previous work, we have identified significant differences in the structure of news articles from reliable and unreliable sources in the US media. Our goal in this work was to explore such differences in the Brazilian media. We found significant features in two data sets: one with Brazilian news in Portuguese and another one with US news in English. Our results show that features related to the writing style were prominent in both data sets and, despite the language difference, some features have a universal behavior, being significant to both US and Brazilian news articles. Finally, we combined both data sets and used the universal features to build a machine learning classifier to predict the source type of a news article as reliable or unreliable.
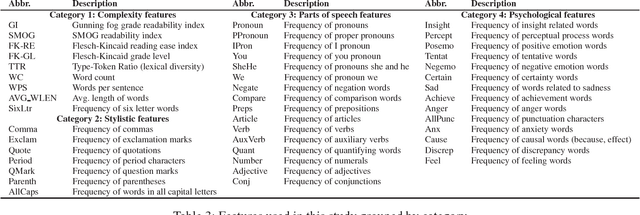
This Just In: Fake News Packs a Lot in Title, Uses Simpler, Repetitive Content in Text Body, More Similar to Satire than Real News
Mar 28, 2017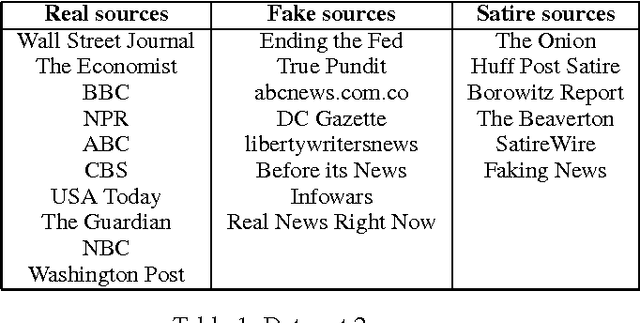

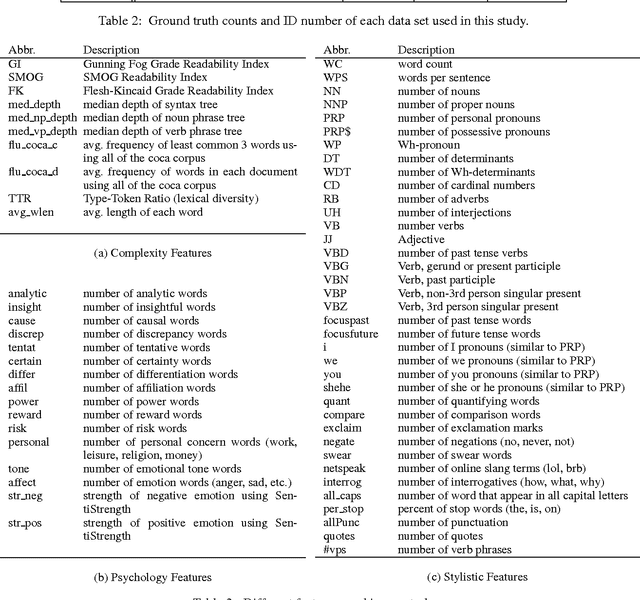
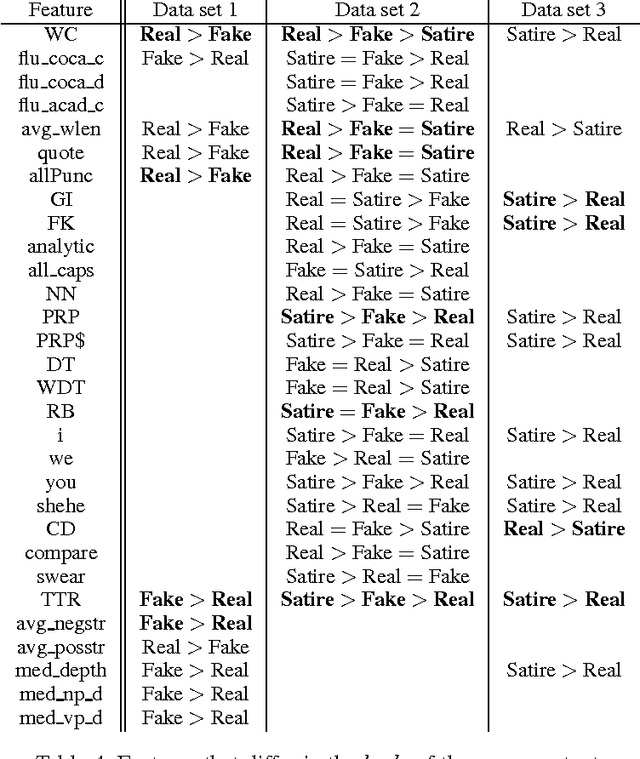
The problem of fake news has gained a lot of attention as it is claimed to have had a significant impact on 2016 US Presidential Elections. Fake news is not a new problem and its spread in social networks is well-studied. Often an underlying assumption in fake news discussion is that it is written to look like real news, fooling the reader who does not check for reliability of the sources or the arguments in its content. Through a unique study of three data sets and features that capture the style and the language of articles, we show that this assumption is not true. Fake news in most cases is more similar to satire than to real news, leading us to conclude that persuasion in fake news is achieved through heuristics rather than the strength of arguments. We show overall title structure and the use of proper nouns in titles are very significant in differentiating fake from real. This leads us to conclude that fake news is targeted for audiences who are not likely to read beyond titles and is aimed at creating mental associations between entities and claims.