 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effects of Fine-tuning Language Models for Text-Based Reinforcement Learning
Apr 15, 2024Text-based reinforcement learning involves an agent interacting with a fictional environment using observed text and admissible actions in natural language to complete a task. Previous works have shown that agents can succeed in text-based interactive environments even in the complete absence of semantic understanding or other linguistic capabilities. The success of these agents in playing such games suggests that semantic understanding may not be important for the task. This raises an important question about the benefits of LMs in guiding the agents through the game states. In this work, we show that rich semantic understanding leads to efficient training of text-based RL agents. Moreover, we describe the occurrence of semantic degeneration as a consequence of inappropriate fine-tuning of language models in text-based reinforcement learning (TBRL). Specifically, we describe the shift in the semantic representation of words in the LM, as well as how it affects the performance of the agent in tasks that are semantically similar to the training games. We believe these results may help develop better strategies to fine-tune agents in text-based RL scenarios.
An Exploration of Unreliable News Classification in Brazil and The U.S
Jun 07, 2018
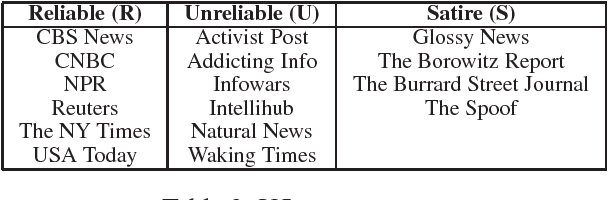
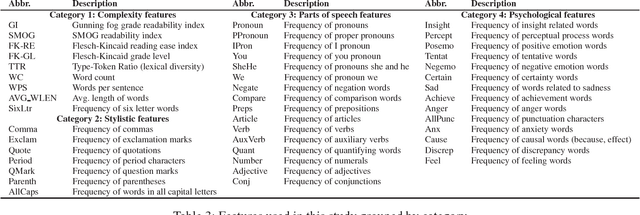

The propagation of unreliable information is on the rise in many places around the world. This expansion is facilitated by the rapid spread of information and anonymity granted by the Internet. The spread of unreliable information is a wellstudied issue and it is associated with negative social impacts. In a previous work, we have identified significant differences in the structure of news articles from reliable and unreliable sources in the US media. Our goal in this work was to explore such differences in the Brazilian media. We found significant features in two data sets: one with Brazilian news in Portuguese and another one with US news in English. Our results show that features related to the writing style were prominent in both data sets and, despite the language difference, some features have a universal behavior, being significant to both US and Brazilian news articles. Finally, we combined both data sets and used the universal features to build a machine learning classifier to predict the source type of a news article as reliable or unreliable.