 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Feature Learning on Embedding Layer of Convolutional Autoencoders and Deep Inverse Feature Learning for Image Clustering
Oct 05, 2020
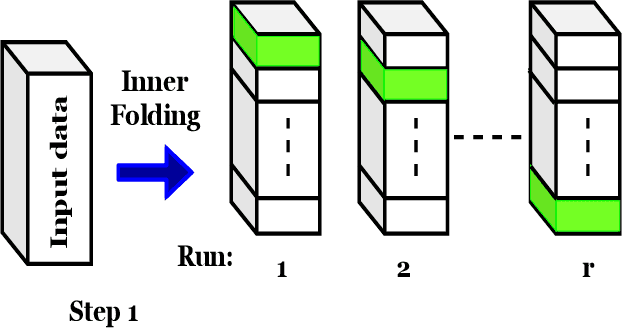
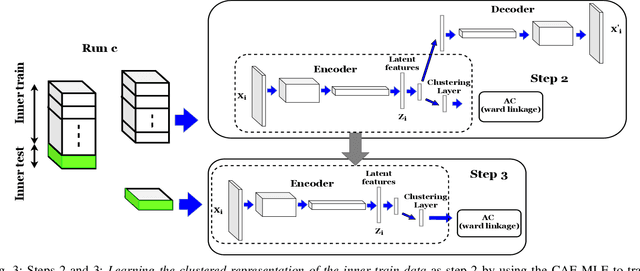

This paper introduces Multi-Level feature learning alongside the Embedding layer of Convolutional Autoencoder (CAE-MLE) as a novel approach in deep clustering. We use agglomerative clustering as the multi-level feature learning that provides a hierarchical structure on the latent feature space. It is shown that applying multi-level feature learning considerably improves the basic deep convolutional embedding clustering (DCEC). CAE-MLE considers the clustering loss of agglomerative clustering simultaneously alongside the learning latent feature of CAE. In the following of the previous works in inverse feature learning, we show that the representation of learning of error as a general strategy can be applied on different deep clustering approaches and it leads to promising results. We develop deep inverse feature learning (deep IFL) on CAE-MLE as a novel approach that leads to the state-of-the-art results among the same category methods. The experimental results show that the CAE-MLE improves the results of the basic method, DCEC, around 7% -14% on two well-known datasets of MNIST and USPS. Also, it is shown that the proposed deep IFL improves the primary results about 9%-17%. Therefore, both proposed approaches of CAE-MLE and deep IFL based on CAE-MLE can lead to notable performance improvement in comparison to the majority of existing techniques. The proposed approaches while are based on a basic convolutional autoencoder lead to outstanding results even in comparison to variational autoencoders or generative adversarial networks.
Piece-wise Matching Layer in Representation Learning for ECG Classification
Sep 26, 2020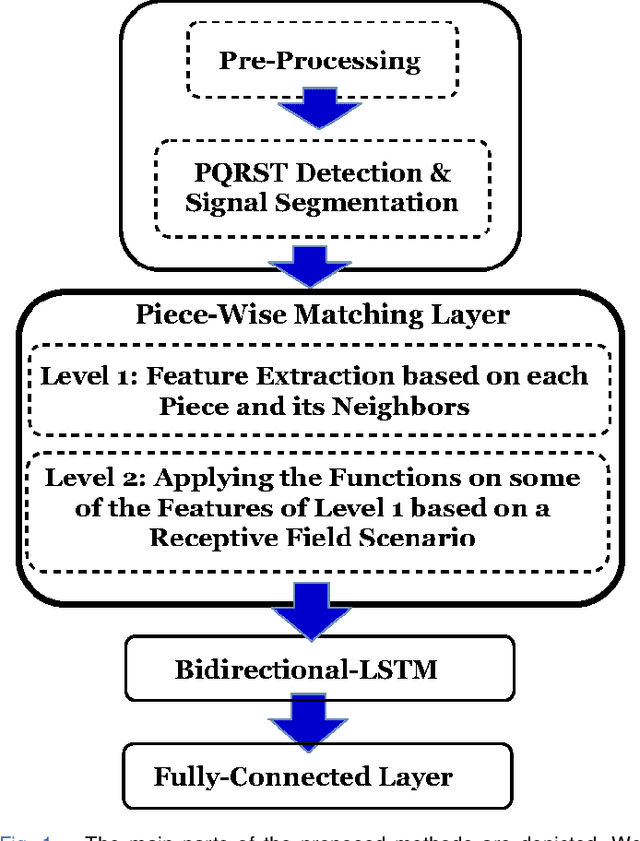
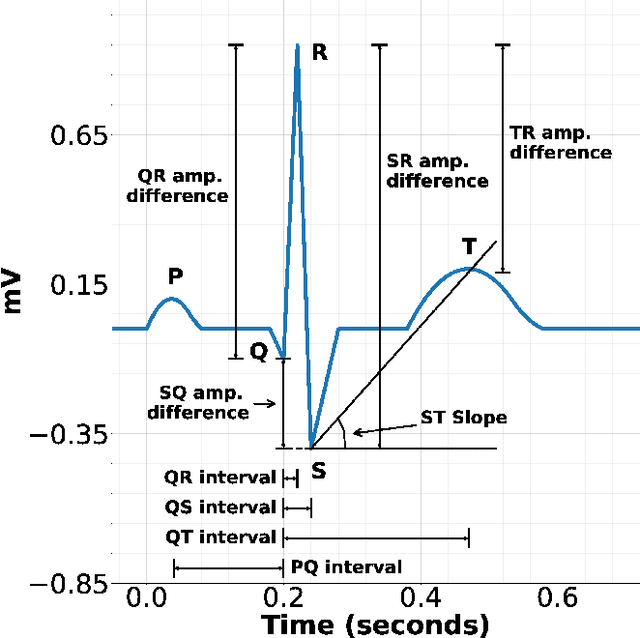
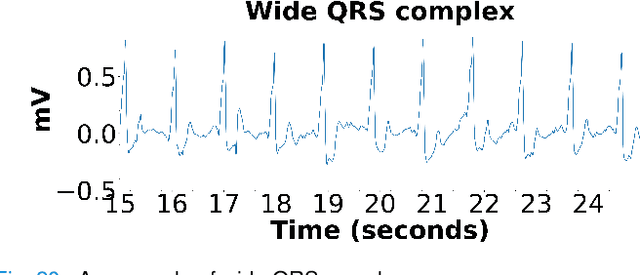
This paper proposes piece-wise matching layer as a novel layer in representation learning methods for electrocardiogram (ECG) classification. Despite the remarkable performance of representation learning methods in the analysis of time series, there are still several challenges associated with these methods ranging from the complex structures of methods, the lack of generality of solutions, the need for expert knowledge, and large-scale training datasets. We introduce the piece-wise matching layer that works based on two levels to address some of the aforementioned challenges. At the first level, a set of morphological, statistical, and frequency features and comparative forms of them are computed based on each periodic part and its neighbors. At the second level, these features are modified by predefined transformation functions based on a receptive field scenario. Several scenarios of offline processing, incremental processing, fixed sliding receptive field, and event-based triggering receptive field can be implemented based on the choice of length and mechanism of indicating the receptive field. We propose dynamic time wrapping as a mechanism that indicates a receptive field based on event triggering tactics. To evaluate the performance of this method in time series analysis, we applied the proposed layer in two publicly available datasets of PhysioNet competitions in 2015 and 2017 where the input data is ECG signal. We compared the performance of our method against a variety of known tuned methods from expert knowledge, machine learning, deep learning methods, and the combination of them. The proposed approach improves the state of the art in two known completions 2015 and 2017 around 4% and 7% correspondingly while it does not rely on in advance knowledge of the classes or the possible places of arrhythmia.
Deep Inverse Feature Learning: A Representation Learning of Error
Mar 09, 2020

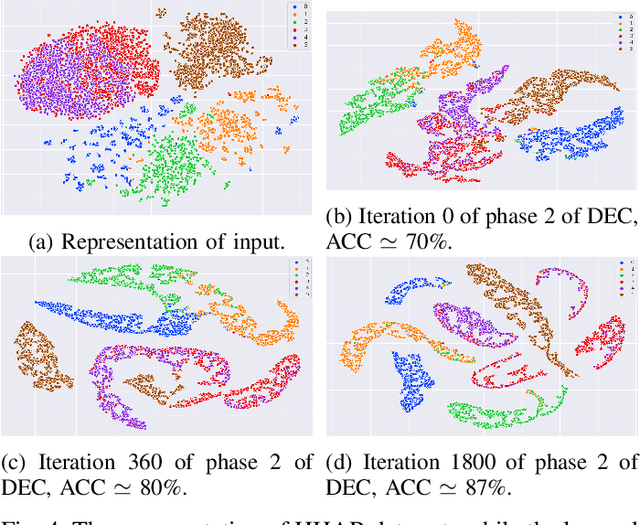
This paper introduces a novel perspective about error in machine learning and proposes inverse feature learning (IFL) as a representation learning approach that learns a set of high-level features based on the representation of error for classification or clustering purposes. The proposed perspective about error representation is fundamentally different from current learning methods, where in classification approaches they interpret the error as a function of the differences between the true labels and the predicted ones or in clustering approaches, in which the clustering objective functions such as compactness are used. Inverse feature learning method operates based on a deep clustering approach to obtain a qualitative form of the representation of error as features. The performance of the proposed IFL method is evaluated by applying the learned features along with the original features, or just using the learned features in different classification and clustering techniques for several data sets. The experimental results show that the proposed method leads to promising results in classification and especially in clustering. In classification, the proposed features along with the primary features improve the results of most of the classification methods on several popular data sets. In clustering, the performance of different clustering methods is considerably improved on different data sets. There are interesting results that show some few features of the representation of error capture highly informative aspects of primary features. We hope this paper helps to utilize the error representation learning in different feature learning domains.
Inverse Feature Learning: Feature learning based on Representation Learning of Error
Mar 08, 2020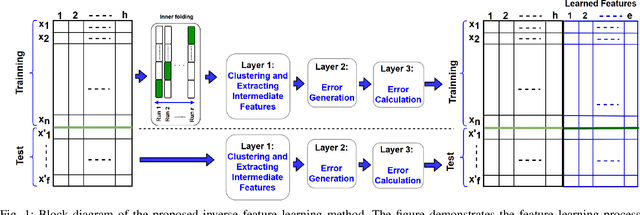



This paper proposes inverse feature learning as a novel supervised feature learning technique that learns a set of high-level features for classification based on an error representation approach. The key contribution of this method is to learn the representation of error as high-level features, while current representation learning methods interpret error by loss functions which are obtained as a function of differences between the true labels and the predicted ones. One advantage of such learning method is that the learned features for each class are independent of learned features for other classes; therefore, this method can learn simultaneously meaning that it can learn new classes without retraining. Error representation learning can also help with generalization and reduce the chance of over-fitting by adding a set of impactful features to the original data set which capture the relationships between each instance and different classes through an error generation and analysis process. This method can be particularly effective in data sets, where the instances of each class have diverse feature representations or the ones with imbalanced classes. The experimental results show that the proposed method results in significantly better performance compared to the state-of-the-art classification techniques for several popular data sets. We hope this paper can open a new path to utilize the proposed perspective of error representation learning in different feature learning domains.
An Unsupervised Feature Learning Approach to Reduce False Alarm Rate in ICUs
Apr 17, 2019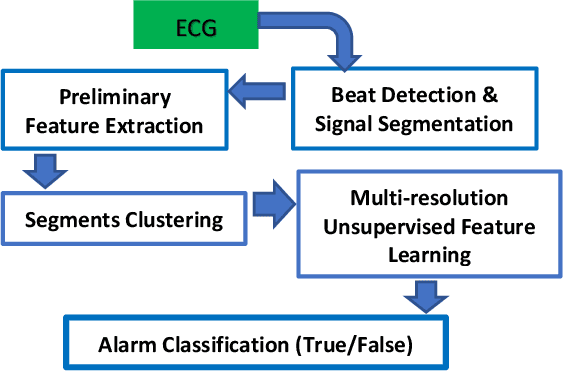
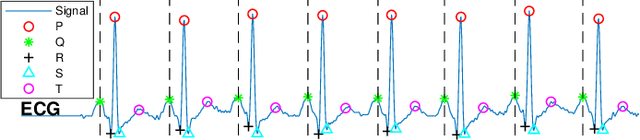
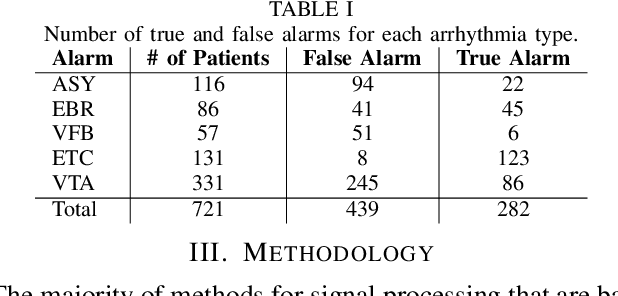
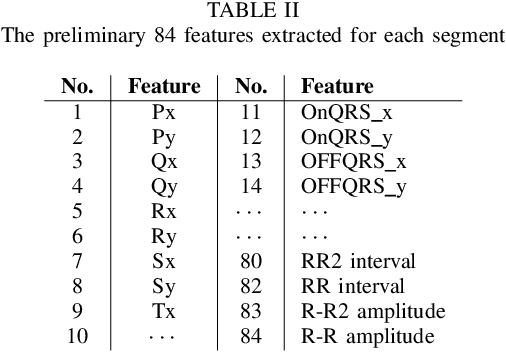
The high rate of false alarms in intensive care units (ICUs) is one of the top challenges of using medical technology in hospitals. These false alarms are often caused by patients' movements, detachment of monitoring sensors, or different sources of noise and interference that impact the collected signals from different monitoring devices. In this paper, we propose a novel set of high-level features based on unsupervised feature learning technique in order to effectively capture the characteristics of different arrhythmia in electrocardiogram (ECG) signal and differentiate them from irregularity in signals due to different sources of signal disturbances. This unsupervised feature learning technique, first extracts a set of low-level features from all existing heart cycles of a patient, and then clusters these segments for each individual patient to provide a set of prominent high-level features. The objective of the clustering phase is to enable the classification method to differentiate between the high-level features extracted from normal and abnormal cycles (i.e., either due to arrhythmia or different sources of distortions in signal) in order to put more attention to the features extracted from abnormal portion of the signal that contribute to the alarm. The performance of this method is evaluated using the 2015 PhysioNet/Computing in Cardiology Challenge dataset for reducing false arrhythmia alarms in the ICUs. As confirmed by the experimental results, the proposed method offers a considerable performance in terms of accuracy, sensitivity and specificity of alarm detection only using a few high-level features that are extracted from one single lead ECG signal.
Autonomous Extraction of a Hierarchical Structure of Tasks in Reinforcement Learning, A Sequential Associate Rule Mining Approach
Nov 17, 2018



Reinforcement learning (RL) techniques, while often powerful, can suffer from slow learning speeds, particularly in high dimensional spaces. Decomposition of tasks into a hierarchical structure holds the potential to significantly speed up learning, generalization, and transfer learning. However, the current task decomposition techniques often rely on high-level knowledge provided by an expert (e.g. using dynamic Bayesian networks) to extract a hierarchical task structure; which is not necessarily available in autonomous systems. In this paper, we propose a novel method based on Sequential Association Rule Mining that can extract Hierarchical Structure of Tasks in Reinforcement Learning (SARM-HSTRL) in an autonomous manner for both Markov decision processes (MDPs) and factored MDPs. The proposed method leverages association rule mining to discover the causal and temporal relationships among states in different trajectories, and extracts a task hierarchy that captures these relationships among sub-goals as termination conditions of different sub-tasks. We prove that the extracted hierarchical policy offers a hierarchically optimal policy in MDPs and factored MDPs. It should be noted that SARM-HSTRL extracts this hierarchical optimal policy without having dynamic Bayesian networks in scenarios with a single task trajectory and also with multiple tasks' trajectories. Furthermore, it has been theoretically and empirically shown that the extracted hierarchical task structure is consistent with trajectories and provides the most efficient, reliable, and compact structure under appropriate assumptions. The numerical results compare the performance of the proposed SARM-HSTRL method with conventional HRL algorithms in terms of the accuracy in detecting the sub-goals, the validity of the extracted hierarchies, and the speed of learning in several testbeds.
Autonomous Extracting a Hierarchical Structure of Tasks in Reinforcement Learning and Multi-task Reinforcement Learning
Sep 15, 2017
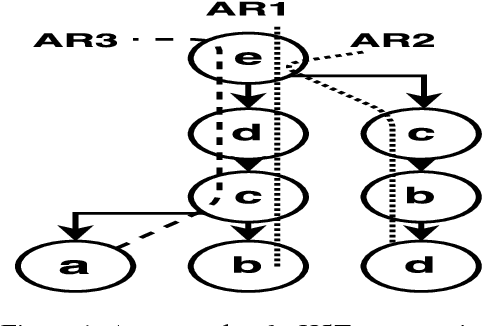
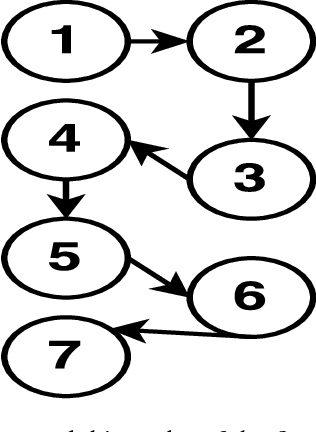

Reinforcement learning (RL), while often powerful, can suffer from slow learning speeds, particularly in high dimensional spaces. The autonomous decomposition of tasks and use of hierarchical methods hold the potential to significantly speed up learning in such domains. This paper proposes a novel practical method that can autonomously decompose tasks, by leveraging association rule mining, which discovers hidden relationship among entities in data mining. We introduce a novel method called ARM-HSTRL (Association Rule Mining to extract Hierarchical Structure of Tasks in Reinforcement Learning). It extracts temporal and structural relationships of sub-goals in RL, and multi-task RL. In particular,it finds sub-goals and relationship among them. It is shown the significant efficiency and performance of the proposed method in two main topics of RL.