 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Inverse Feature Learning: A Representation Learning of Error
Paper and Code
Mar 09, 2020

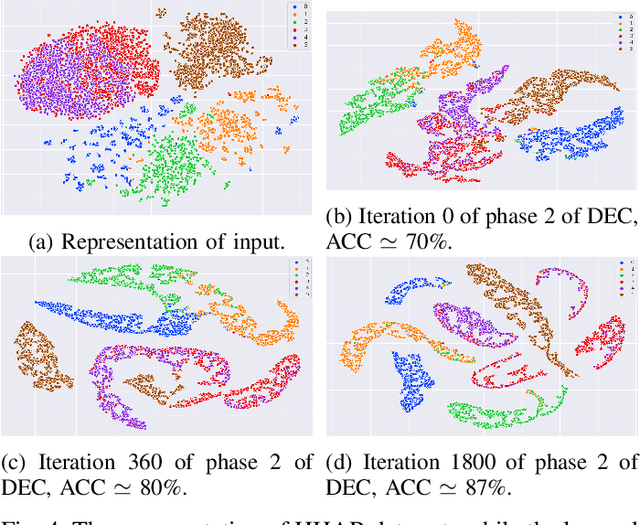
This paper introduces a novel perspective about error in machine learning and proposes inverse feature learning (IFL) as a representation learning approach that learns a set of high-level features based on the representation of error for classification or clustering purposes. The proposed perspective about error representation is fundamentally different from current learning methods, where in classification approaches they interpret the error as a function of the differences between the true labels and the predicted ones or in clustering approaches, in which the clustering objective functions such as compactness are used. Inverse feature learning method operates based on a deep clustering approach to obtain a qualitative form of the representation of error as features. The performance of the proposed IFL method is evaluated by applying the learned features along with the original features, or just using the learned features in different classification and clustering techniques for several data sets. The experimental results show that the proposed method leads to promising results in classification and especially in clustering. In classification, the proposed features along with the primary features improve the results of most of the classification methods on several popular data sets. In clustering, the performance of different clustering methods is considerably improved on different data sets. There are interesting results that show some few features of the representation of error capture highly informative aspects of primary features. We hope this paper helps to utilize the error representation learning in different feature learning domains.