 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Feature Learning: Feature learning based on Representation Learning of Error
Paper and Code
Mar 08, 2020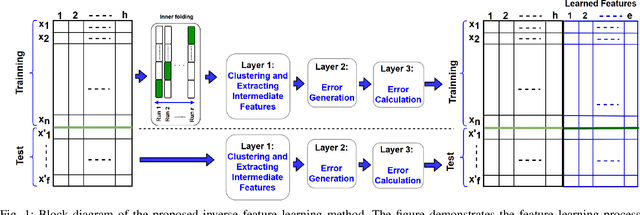



This paper proposes inverse feature learning as a novel supervised feature learning technique that learns a set of high-level features for classification based on an error representation approach. The key contribution of this method is to learn the representation of error as high-level features, while current representation learning methods interpret error by loss functions which are obtained as a function of differences between the true labels and the predicted ones. One advantage of such learning method is that the learned features for each class are independent of learned features for other classes; therefore, this method can learn simultaneously meaning that it can learn new classes without retraining. Error representation learning can also help with generalization and reduce the chance of over-fitting by adding a set of impactful features to the original data set which capture the relationships between each instance and different classes through an error generation and analysis process. This method can be particularly effective in data sets, where the instances of each class have diverse feature representations or the ones with imbalanced classes. The experimental results show that the proposed method results in significantly better performance compared to the state-of-the-art classification techniques for several popular data sets. We hope this paper can open a new path to utilize the proposed perspective of error representation learning in different feature learning domains.