 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Job Understanding at LinkedIn
May 29, 2020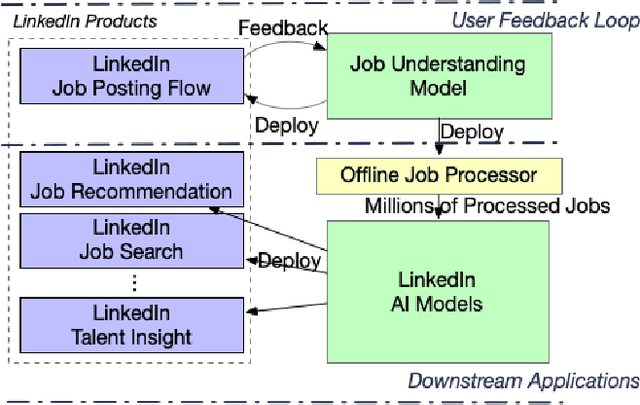
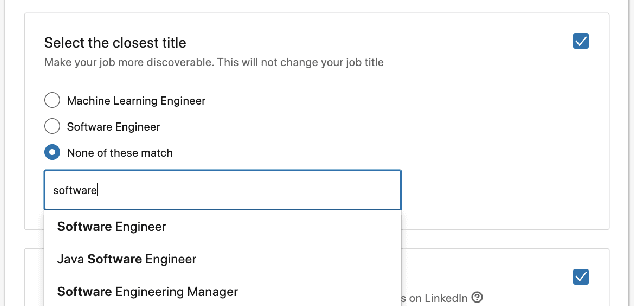
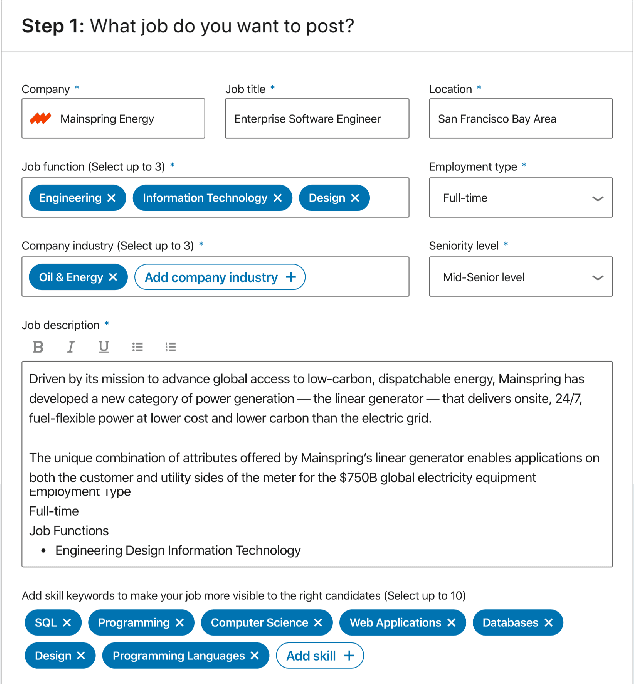
As the world's largest professional network, LinkedIn wants to create economic opportunity for everyone in the global workforce. One of its most critical missions is matching jobs with processionals. Improving job targeting accuracy and hire efficiency align with LinkedIn's Member First Motto. To achieve those goals, we need to understand unstructured job postings with noisy information. We applied deep transfer learning to create domain-specific job understanding models. After this, jobs are represented by professional entities, including titles, skills, companies, and assessment questions. To continuously improve LinkedIn's job understanding ability, we designed an expert feedback loop where we integrated job understanding models into LinkedIn's products to collect job posters' feedback. In this demonstration, we present LinkedIn's job posting flow and demonstrate how the integrated deep job understanding work improves job posters' satisfaction and provides significant metric lifts in LinkedIn's job recommendation system.
Learning to Ask Screening Questions for Job Postings
Apr 30, 2020

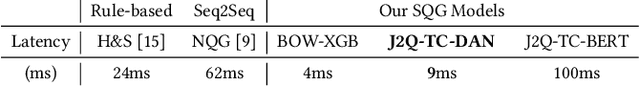
At LinkedIn, we want to create economic opportunity for everyone in the global workforce. A critical aspect of this goal is matching jobs with qualified applicants. To improve hiring efficiency and reduce the need to manually screening each applicant, we develop a new product where recruiters can ask screening questions online so that they can filter qualified candidates easily. To add screening questions to all $20$M active jobs at LinkedIn, we propose a new task that aims to automatically generate screening questions for a given job posting. To solve the task of generating screening questions, we develop a two-stage deep learning model called Job2Questions, where we apply a deep learning model to detect intent from the text description, and then rank the detected intents by their importance based on other contextual features. Since this is a new product with no historical data, we employ deep transfer learning to train complex models with limited training data. We launched the screening question product and our AI models to LinkedIn users and observed significant impact in the job marketplace. During our online A/B test, we observed $+53.10\%$ screening question suggestion acceptance rate, $+22.17\%$ job coverage, $+190\%$ recruiter-applicant interaction, and $+11$ Net Promoter Score. In sum, the deployed Job2Questions model helps recruiters to find qualified applicants and job seekers to find jobs they are qualified for.
Visualizing the Flow of Discourse with a Concept Ontology
Feb 23, 2018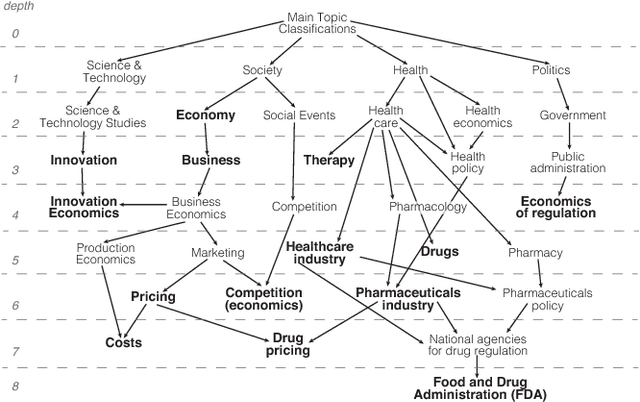


Understanding and visualizing human discourse has long being a challenging task. Although recent work on argument mining have shown success in classifying the role of various sentences, the task of recognizing concepts and understanding the ways in which they are discussed remains challenging. Given an email thread or a transcript of a group discussion, our task is to extract the relevant concepts and understand how they are referenced and re-referenced throughout the discussion. In the present work, we present a preliminary approach for extracting and visualizing group discourse by adapting Wikipedia's category hierarchy to be an external concept ontology. From a user study, we found that our method achieved better results than 4 strong alternative approaches, and we illustrate our visualization method based on the extracted discourse flows.
Neural Tensor Factorization
Feb 13, 2018
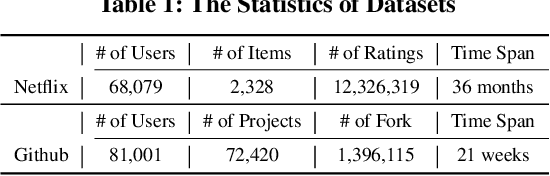
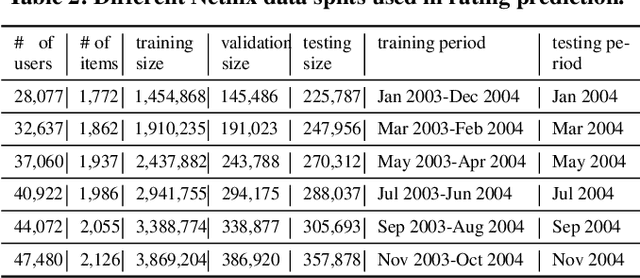
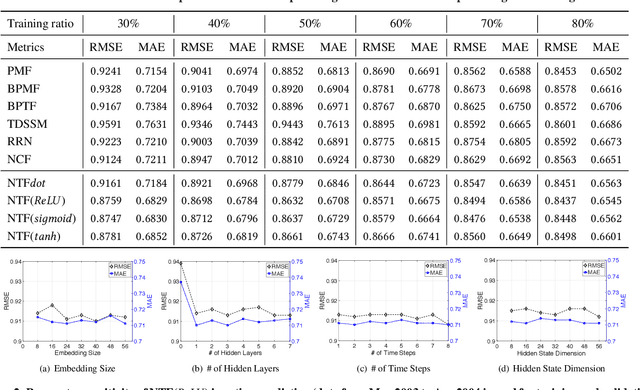
Neural collaborative filtering (NCF) and recurrent recommender systems (RRN) have been successful in modeling user-item relational data. However, they are also limited in their assumption of static or sequential modeling of relational data as they do not account for evolving users' preference over time as well as changes in the underlying factors that drive the change in user-item relationship over time. We address these limitations by proposing a Neural Tensor Factorization (NTF) model for predictive tasks on dynamic relational data. The NTF model generalizes conventional tensor factorization from two perspectives: First, it leverages the long short-term memory architecture to characterize the multi-dimensional temporal interactions on relational data. Second, it incorporates the multi-layer perceptron structure for learning the non-linearities between different latent factors. Our extensive experiments demonstrate the significant improvement in rating prediction and link prediction on dynamic relational data by our NTF model over both neural network based factorization models and other traditional methods.
Open-World Knowledge Graph Completion
Nov 09, 2017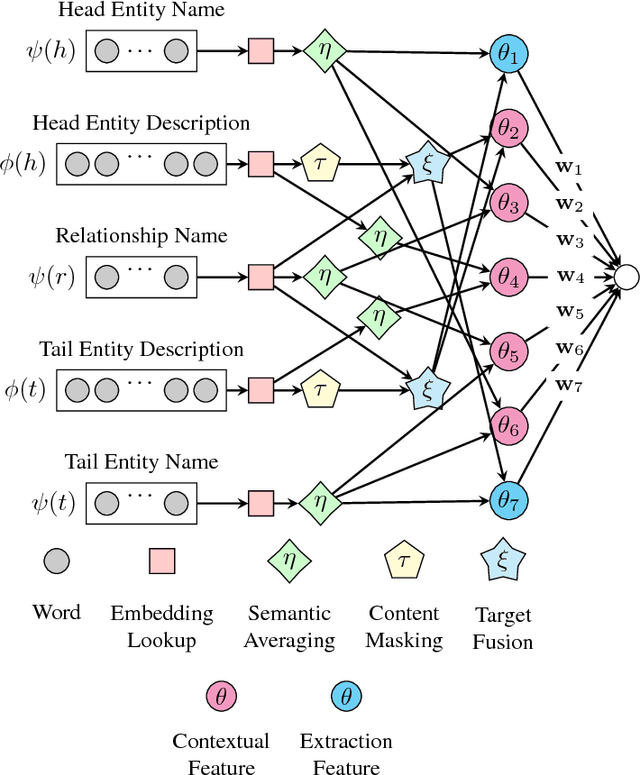


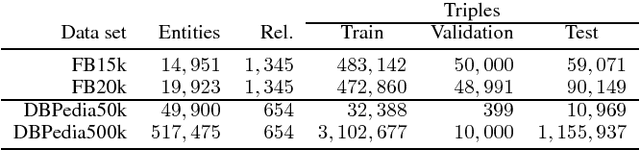
Knowledge Graphs (KGs) have been applied to many tasks including Web search, link prediction, recommendation, natural language processing, and entity linking. However, most KGs are far from complete and are growing at a rapid pace. To address these problems, Knowledge Graph Completion (KGC) has been proposed to improve KGs by filling in its missing connections. Unlike existing methods which hold a closed-world assumption, i.e., where KGs are fixed and new entities cannot be easily added, in the present work we relax this assumption and propose a new open-world KGC task. As a first attempt to solve this task we introduce an open-world KGC model called ConMask. This model learns embeddings of the entity's name and parts of its text-description to connect unseen entities to the KG. To mitigate the presence of noisy text descriptions, ConMask uses a relationship-dependent content masking to extract relevant snippets and then trains a fully convolutional neural network to fuse the extracted snippets with entities in the KG. Experiments on large data sets, both old and new, show that ConMask performs well in the open-world KGC task and even outperforms existing KGC models on the standard closed-world KGC task.
ProjE: Embedding Projection for Knowledge Graph Completion
Nov 16, 2016



With the large volume of new information created every day, determining the validity of information in a knowledge graph and filling in its missing parts are crucial tasks for many researchers and practitioners. To address this challenge, a number of knowledge graph completion methods have been developed using low-dimensional graph embeddings. Although researchers continue to improve these models using an increasingly complex feature space, we show that simple changes in the architecture of the underlying model can outperform state-of-the-art models without the need for complex feature engineering. In this work, we present a shared variable neural network model called ProjE that fills-in missing information in a knowledge graph by learning joint embeddings of the knowledge graph's entities and edges, and through subtle, but important, changes to the standard loss function. In doing so, ProjE has a parameter size that is smaller than 11 out of 15 existing methods while performing $37\%$ better than the current-best method on standard datasets. We also show, via a new fact checking task, that ProjE is capable of accurately determining the veracity of many declarative statements.
Discriminative Predicate Path Mining for Fact Checking in Knowledge Graphs
Apr 15, 2016



Traditional fact checking by experts and analysts cannot keep pace with the volume of newly created information. It is important and necessary, therefore, to enhance our ability to computationally determine whether some statement of fact is true or false. We view this problem as a link-prediction task in a knowledge graph, and present a discriminative path-based method for fact checking in knowledge graphs that incorporates connectivity, type information, and predicate interactions. Given a statement S of the form (subject, predicate, object), for example, (Chicago, capitalOf, Illinois), our approach mines discriminative paths that alternatively define the generalized statement (U.S. city, predicate, U.S. state) and uses the mined rules to evaluate the veracity of statement S. We evaluate our approach by examining thousands of claims related to history, geography, biology, and politics using a public, million node knowledge graph extracted from Wikipedia and PubMedDB. Not only does our approach significantly outperform related models, we also find that the discriminative predicate path model is easily interpretable and provides sensible reasons for the final determination.
Scalable Models for Computing Hierarchies in Information Networks
Jan 04, 2016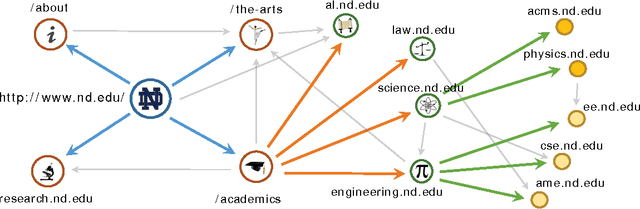
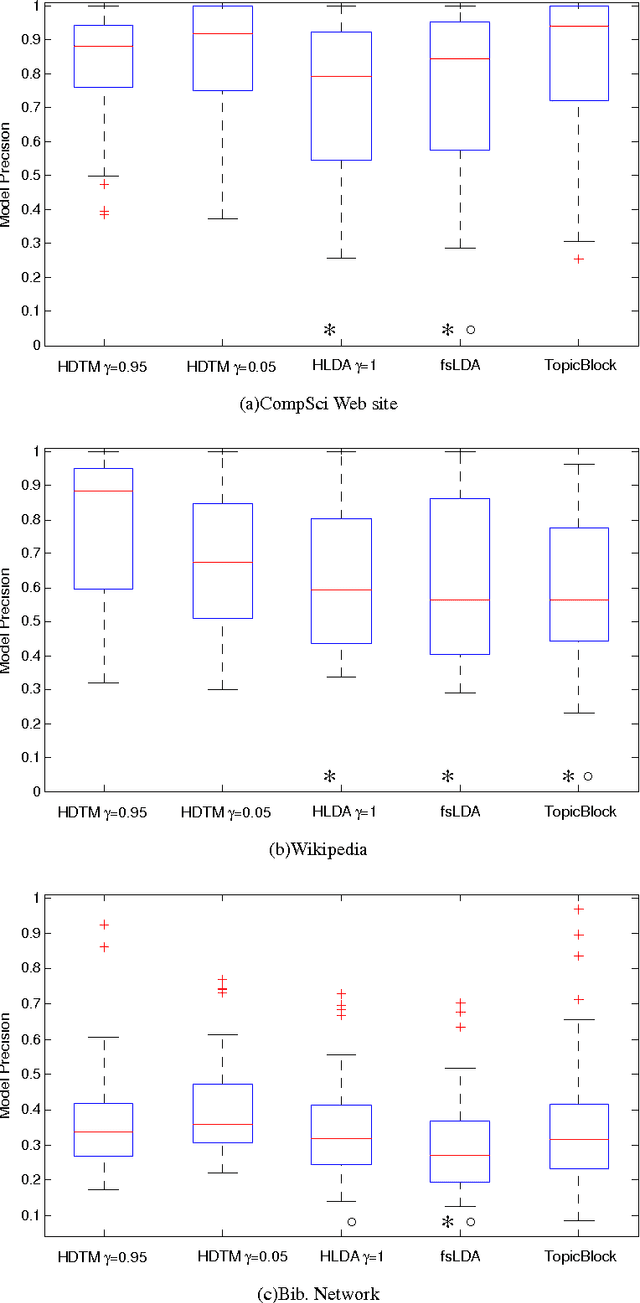


Information hierarchies are organizational structures that often used to organize and present large and complex information as well as provide a mechanism for effective human navigation. Fortunately, many statistical and computational models exist that automatically generate hierarchies; however, the existing approaches do not consider linkages in information {\em networks} that are increasingly common in real-world scenarios. Current approaches also tend to present topics as an abstract probably distribution over words, etc rather than as tangible nodes from the original network. Furthermore, the statistical techniques present in many previous works are not yet capable of processing data at Web-scale. In this paper we present the Hierarchical Document Topic Model (HDTM), which uses a distributed vertex-programming process to calculate a nonparametric Bayesian generative model. Experiments on three medium size data sets and the entire Wikipedia dataset show that HDTM can infer accurate hierarchies even over large information networks.