 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Solving Graph Neural Tangent Kernel Equivalent to Training Graph Neural Network?
Sep 14, 2023
A rising trend in theoretical deep learning is to understand why deep learning works through Neural Tangent Kernel (NTK) [jgh18], a kernel method that is equivalent to using gradient descent to train a multi-layer infinitely-wide neural network. NTK is a major step forward in the theoretical deep learning because it allows researchers to use traditional mathematical tools to analyze properties of deep neural networks and to explain various neural network techniques from a theoretical view. A natural extension of NTK on graph learning is \textit{Graph Neural Tangent Kernel (GNTK)}, and researchers have already provide GNTK formulation for graph-level regression and show empirically that this kernel method can achieve similar accuracy as GNNs on various bioinformatics datasets [dhs+19]. The remaining question now is whether solving GNTK regression is equivalent to training an infinite-wide multi-layer GNN using gradient descent. In this paper, we provide three new theoretical results. First, we formally prove this equivalence for graph-level regression. Second, we present the first GNTK formulation for node-level regression. Finally, we prove the equivalence for node-level regression.
Query Complexity of Active Learning for Function Family With Nearly Orthogonal Basis
Jun 06, 2023Many machine learning algorithms require large numbers of labeled data to deliver state-of-the-art results. In applications such as medical diagnosis and fraud detection, though there is an abundance of unlabeled data, it is costly to label the data by experts, experiments, or simulations. Active learning algorithms aim to reduce the number of required labeled data points while preserving performance. For many convex optimization problems such as linear regression and $p$-norm regression, there are theoretical bounds on the number of required labels to achieve a certain accuracy. We call this the query complexity of active learning. However, today's active learning algorithms require the underlying learned function to have an orthogonal basis. For example, when applying active learning to linear regression, the requirement is the target function is a linear composition of a set of orthogonal linear functions, and active learning can find the coefficients of these linear functions. We present a theoretical result to show that active learning does not need an orthogonal basis but rather only requires a nearly orthogonal basis. We provide the corresponding theoretical proofs for the function family of nearly orthogonal basis, and its applications associated with the algorithmically efficient active learning framework.
HLIC: Harmonizing Optimization Metrics in Learned Image Compression by Reinforcement Learning
Sep 30, 2021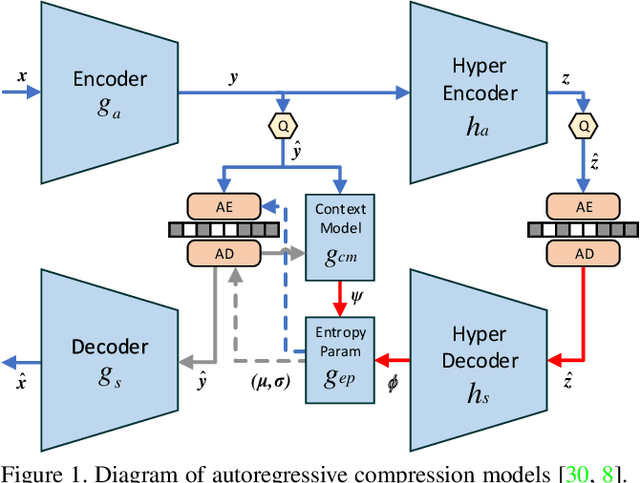
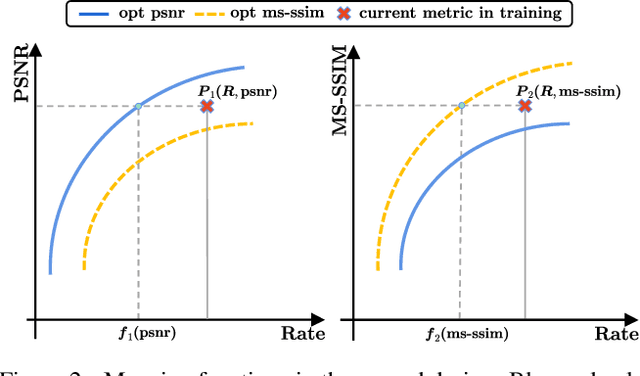

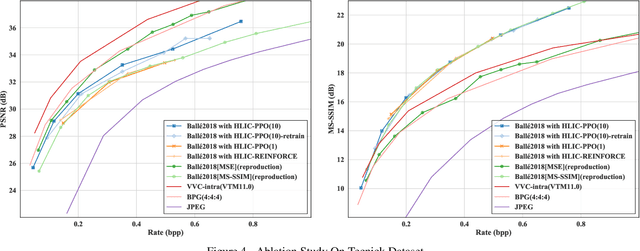
Learned image compression is making good progress in recent years. Peak signal-to-noise ratio (PSNR) and multi-scale structural similarity (MS-SSIM) are the two most popular evaluation metrics. As different metrics only reflect certain aspects of human perception, works in this field normally optimize two models using PSNR and MS-SSIM as loss function separately, which is suboptimal and makes it difficult to select the model with best visual quality or overall performance. Towards solving this problem, we propose to Harmonize optimization metrics in Learned Image Compression (HLIC) using online loss function adaptation by reinforcement learning. By doing so, we are able to leverage the advantages of both PSNR and MS-SSIM, achieving better visual quality and higher VMAF score. To our knowledge, our work is the first to explore automatic loss function adaptation for harmonizing optimization metrics in low level vision tasks like learned image compression.
Checkerboard Context Model for Efficient Learned Image Compression
Apr 01, 2021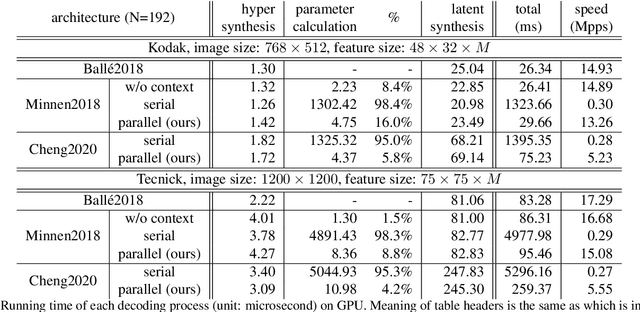

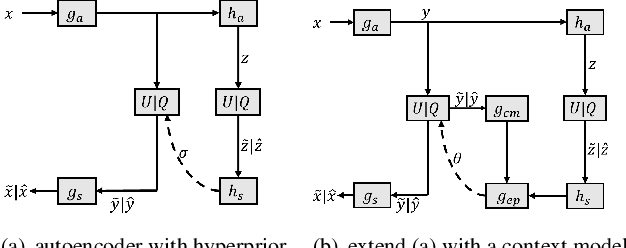

For learned image compression, the autoregressive context model is proved effective in improving the rate-distortion (RD) performance. Because it helps remove spatial redundancies among latent representations. However, the decoding process must be done in a strict scan order, which breaks the parallelization. We propose a parallelizable checkerboard context model (CCM) to solve the problem. Our two-pass checkerboard context calculation eliminates such limitations on spatial locations by re-organizing the decoding order. Speeding up the decoding process more than 40 times in our experiments, it achieves significantly improved computational efficiency with almost the same rate-distortion performance. To the best of our knowledge, this is the first exploration on parallelization-friendly spatial context model for learned image compression.